
문제
https://www.acmicpc.net/problem/11728
풀이
전부 vector에 넣고 정렬하기
#include <iostream>
#include <algorithm>
#include <vector>
#include <set>
using namespace std;
typedef pair<int, int> pii;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int N, M;
cin >> N >> M;
vector<int> v;
for(int i = 0; i < N + M; i++) {
int x;
cin >> x;
v.push_back(x);
}
sort(v.begin(), v.end());
for(auto e: v){
cout << e << " ";
}
return 0;
}
단순하게 풀었더니 시간이 엄청 오래 걸린다. 그리고 이 문제의 의도와 무관하게 푼 거 같다. 어떻게 풀어야 더 효율적일까?
분할 정복 & 투포인터
참고자료
문제 조건을 제대로 읽어보면, 입력으로 주어지는 두 배열은 이미 정렬되어 있다.
이처럼 정렬된 두 배열을 합칠 때는 분할정복 알고리즘을 적용할 수 있다. 그 대표적인 예시가 바로 합병 정렬이다.
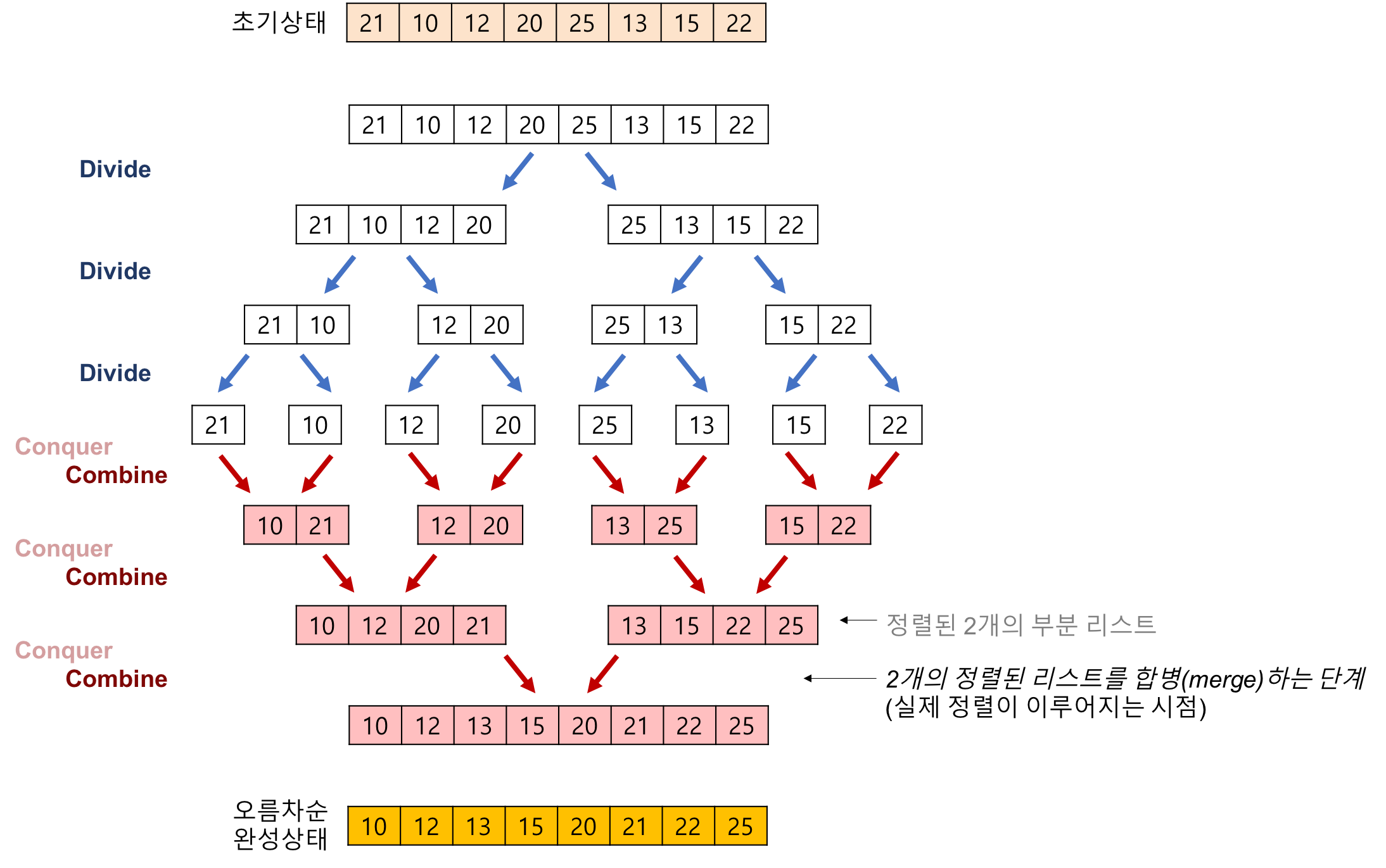
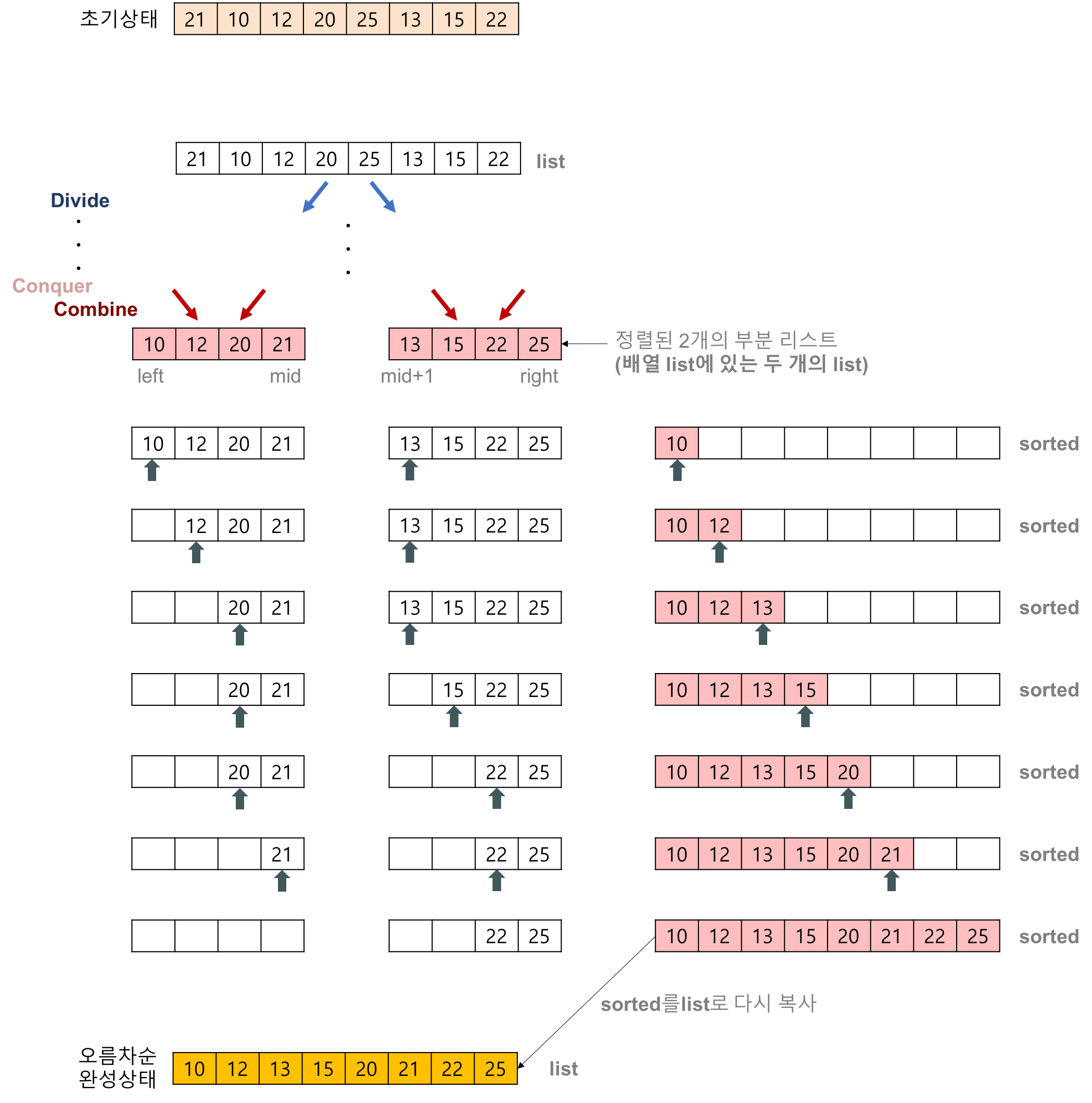
위의 그림처럼 정렬된 2개의 부분 배열을 합칠 때는, 각 배열의 원소를 가리키는 두 개의 포인터를 만들고, 그 포인터가 가리키는 두 값을 비교하면서 정렬된 하나의 배열을 만들면 된다. 이를 투포인터 알고리즘이라고 부르기도 한다.
#include <iostream>
#include <algorithm>
#include <vector>
#include <set>
using namespace std;
const int MAX = 1000001;
int a[MAX];
int b[MAX];
int N, M;
void input() {
cin >> N >> M;
for(int i = 0; i < N; i++){
cin >> a[i];
}
for(int i = 0; i < M; i++){
cin >> b[i];
}
}
void solution() {
int pa = 0, pb = 0;
while(pa < N && pb < M){
if(a[pa] < b[pb]) {
cout << a[pa++] << " ";
}else{
cout << b[pb++] << " ";
}
}
while(pa < N){
cout << a[pa++] << " ";
}
while(pb < M){
cout << b[pb++] << " ";
}
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
input();
solution();
return 0;
}
실행 시간이 좀 더 단축되었다!

습관이 될 때까지 📝