
1. 데이터베이스란?
💡 컴퓨터 시스템에 저장되는 정보 또는 데이터의 집합
데이터베이스는 데이터베이스 관리 시스템인 (DBMS)로 제어한다.
데이터 + DBMS + 연관된 어플리케이션들 = 데이터베이스 시스템 (= 데이터베이스)
💡 데이터베이스 사용이유는?
어플리케이션에서는 데이터가 메모리상에서 존재하는데, 메모리에 존재하는 데이터는 보존이 되지 않아서 어플리케이션을 종료하면 메모리에 있던 데이터들을 다시 읽어 들일 수 없다. 이러한 데이터를 오랜 기간 저장, 보존하기 위해 데이터 베이스를 사용한다.
1) 관계형 데이터베이스
(관계형 데이터 모델에 기초를 둔 데이터베이스 시스템)
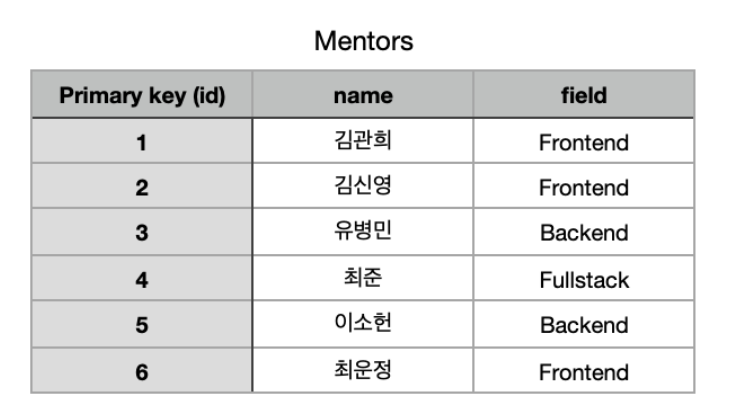
- 관계형 데이터: 데이터들이 서로 상호관련성을 가진 형태로 표현한 데이터.
- 모든 데이터들은 2차원 테이블로 표현할 수 있다.
- 각각의 테이블은 column, row로 구성
(column: 테이블의 각 항목 | row: 각 항목들의 실제 값.)- 각 row는 primary key가 있어야 한다. 이 primary key를 통해 해당 row을 찾거나 참조.
- 각 테이블들은 서로 상화관련성을 가지고 서로 연결된다.
테이블끼리의 연결
-
one to one
두 테이블이 정확히 일대일 매칭이 되는 경우

이렇게 두 테이블을 겹쳤을때 무리없이 겹쳐져서 한테이블 처럼 보아도 문제가 없는 경우(속성들은 분리됨) -
one to many
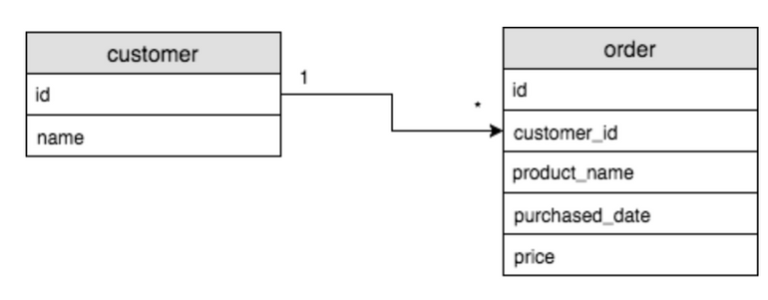
한 테이블의 row가 테이블 B의 여러 row와 연결 되는 관계
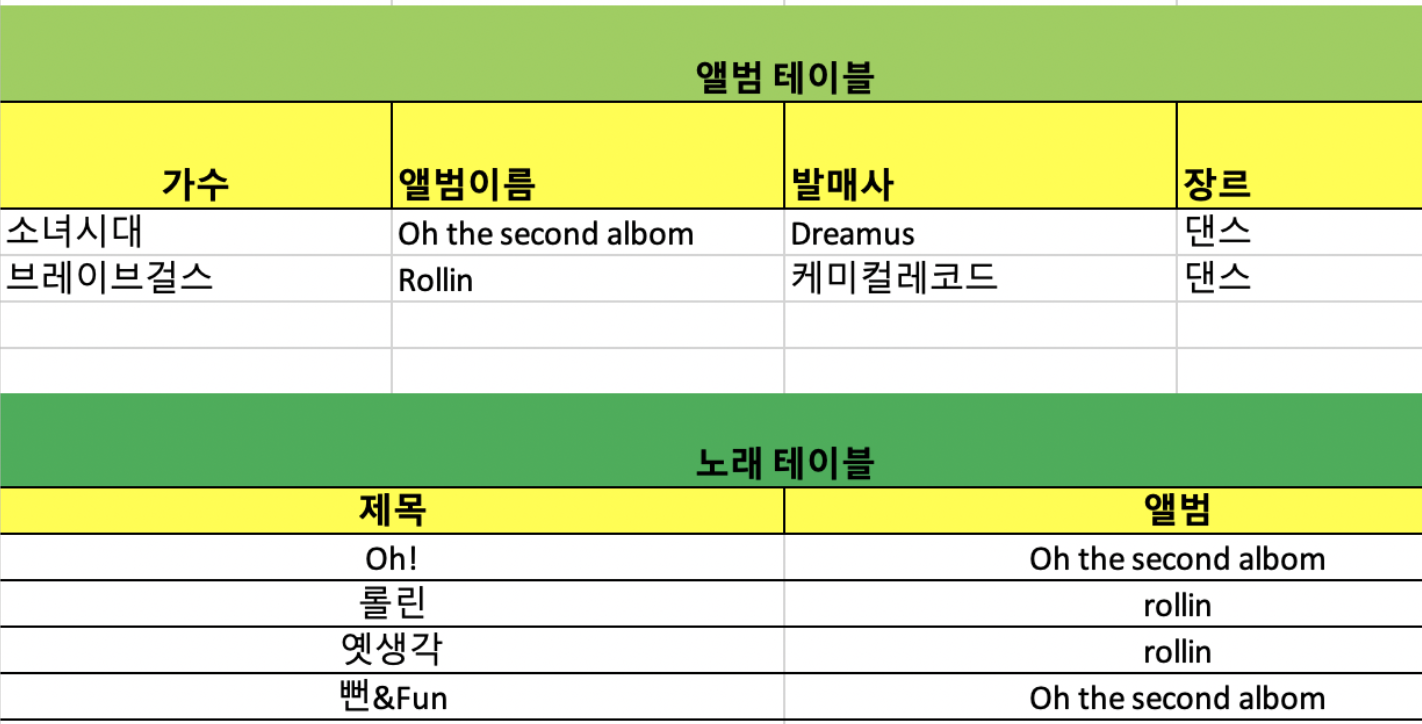
위에 처럼 한 앨범안에 여러 수록곡이 있는 그런 관계
(앨범명은 하나지만 그 앨범명은 여러 값을 가질 수 있다.) -
many to many
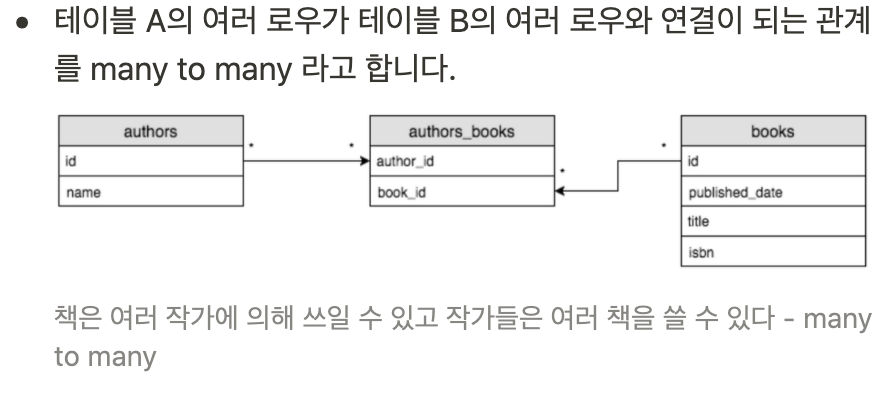
테이블 a의 여러 row가 테이블 b의 여러 row와 연결이 되는 관계
=> 이러한 관계는 어느 테이블이 기준인지에 따라 달라진다.
테이블 연결 방법
Foreign Key를 사용해서 연결한다.
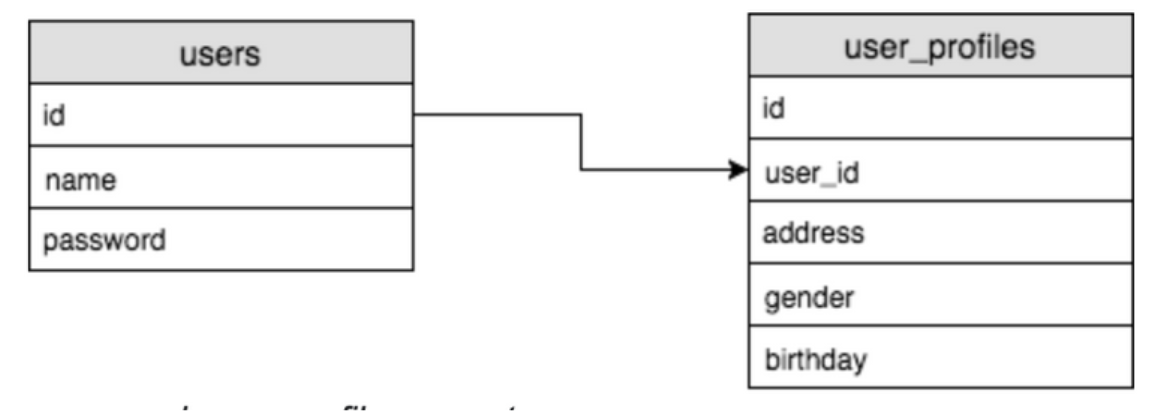
user_profiles(외부키) | users_id는 users(기본키)
즉, users_id는 users 테이블의 id에 존재하는 값만 생성 될 수 있다.
💡 테이블들 연결하는 이유
- 정규화
하나의 테이블에 모든 정보를 넣게 되면 동일 정보들이 불필요하게 중복되어서 저장된다. 이는 더 많은 디스크를 사용하게 되고, 잘못된 데이터가 저장될 가능이 높아진다.
따라서, 테이블들을 따로 쓰고 연결하면 중복된 데이터를 저장하지 않아, 디스크를 더 효율적으로 쓸 수 있고, 서로 같은 데이터지만 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어진다.
스타벅스 모델링
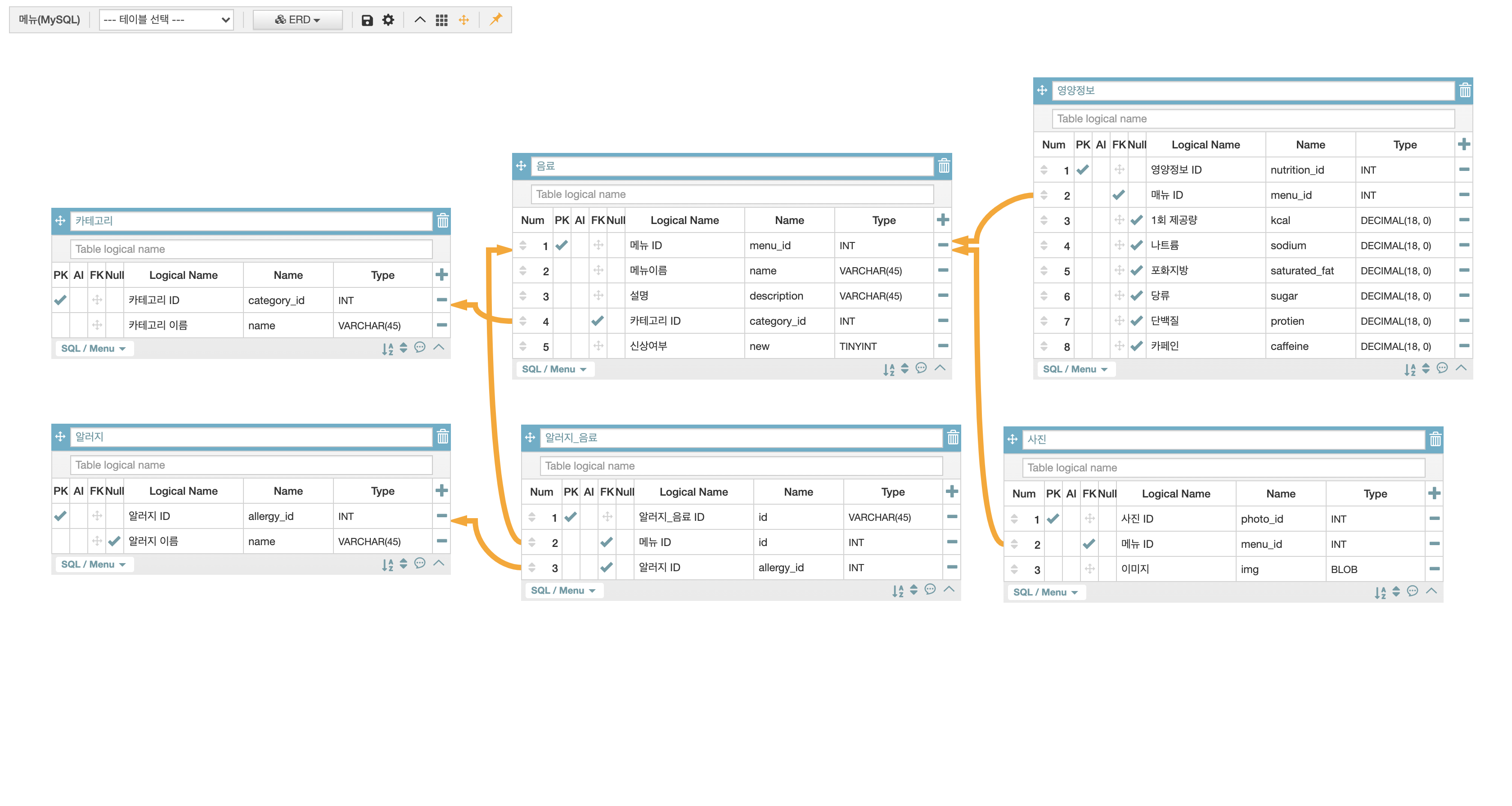
- 테이블명은 소문자로 시작하고 복수형태를 띈다.
- 각 속성값들은 소문자사용
- 테이블의 관계를 나타낼때는 역참조보단 정참조가 더 낫다.
역참조를 하게 되면 어떤 속성을 명시하는지 한번에 바로 알 수가 없다. 그러나 정참조를 하게 되면 어떤 속성을 명시 하는지 한번에 알 수있다. 그래서 영양정보테이블과 음료테이블을 역참조에서 정참조로 바꾸어 주면 더 좋다.
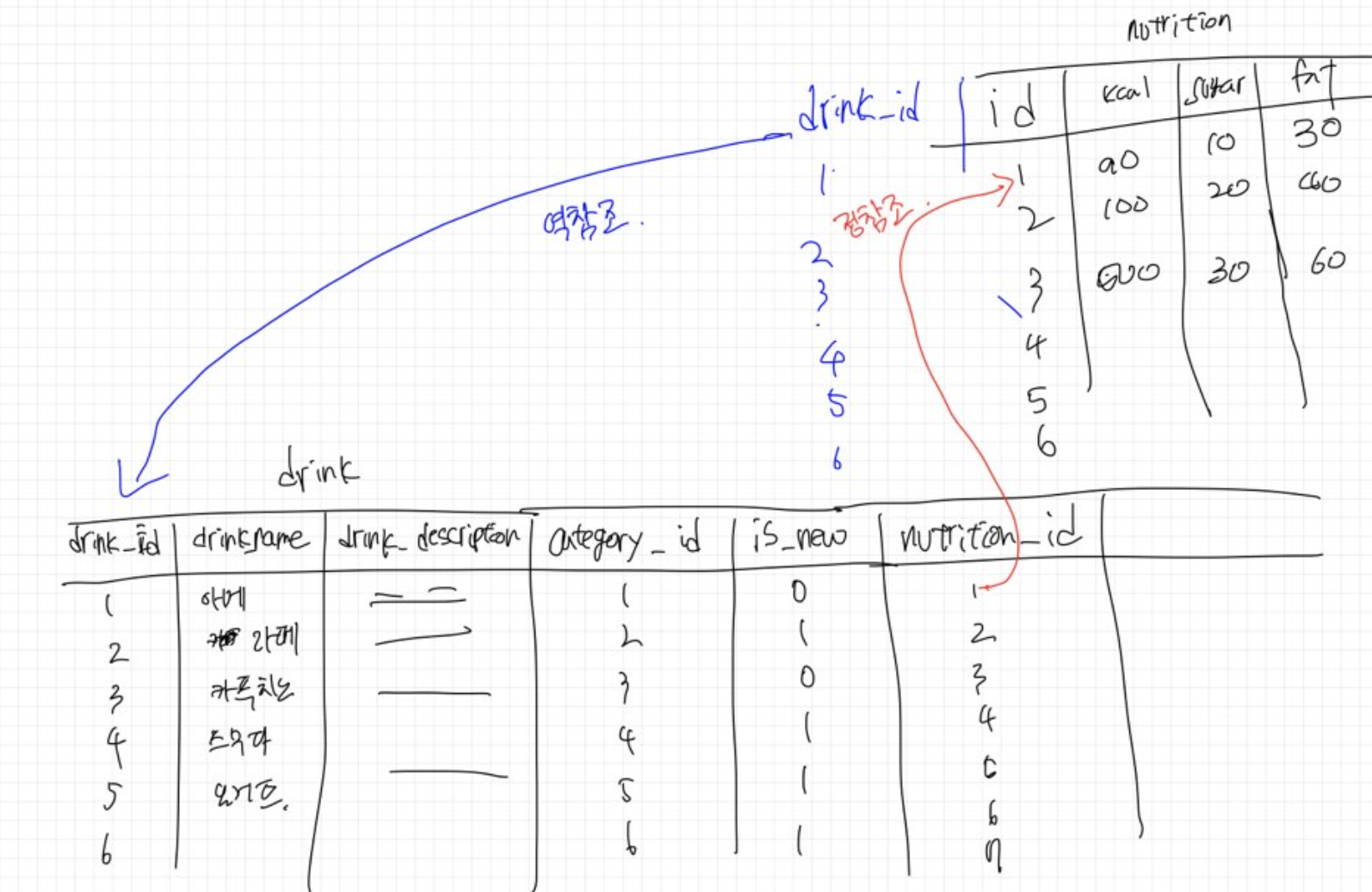
위 사진은 그냥 내가 테이블을 이해하기 편하게 그린건데..
이때 영양테이블이 음료테이블의 drink_id를 참조하는 역참조인경우에는 영양정보테이블에 있는 id값이 음료 테이블의 id를 참조하기 때문에 영양테이블에 있는 id값들만으로 무슨 음료를 지정하고 있는 한번에 파악이 불가능 하다. 그런데 정참조를 하게 되면 음료 테이블들도 nutrition_id 값을 가지고 있기때문에 한번에 무슨 음료수인지 파악하는것이 가능해진다. 이러면 테이블들을 더 효과적으로 연결하는 것이 가능하다.
