이전 게시물들에서 자바 코드가 어떻게 메모리에 적재되어 실행되며, 메모리 상에서 어떻게 관리되는지 살펴보았다.
이번 게시물에서는 JVM의 메모리 구조가 어떻게 이루어져 있는지 살펴보자.
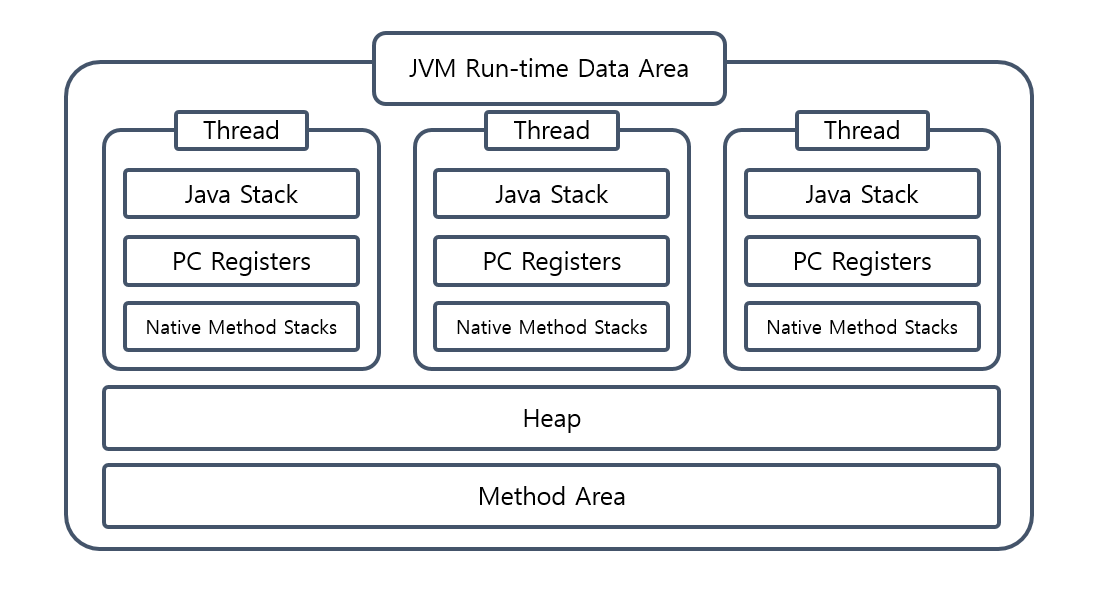
런타임 데이터 영역은 JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역.
모든 쓰레드가 공유하는 영역과 쓰레드 별로 가지고 있는 메모리 영역들로 구성된다.
런타임 데이터 영역은 다음의 다섯가지 영역으로 나눌 수 있다.
- Method Area (공유 영역)
- Heap Area (공유 영역)
- Stack Area (쓰레드별 영역)
- PC Register (쓰레드별 영역)
- Native Method Stack (쓰레드별 영역)
여기서 Method Area와 Heap Area는 모든 스레드가 공유하는 영역이고,
나머지 Stack Area, PC Register, Native Method Stack은 위 그림처럼 스레드마다 생성되는 개별 영역이다.
1. 메서드 영역 (Method Area)
메서드 영역는 JVM이 시작될 때 생성되는 공간으로 바이트코드 파일(.class)를 처음 메모리 공간에 올릴 때 초기화되는 대상을 저장하기 위한 메모리 공간이다.
JVM이 동작하고 클래스가 로드될 때 적재되서 프로그램이 종료될 때까지 저장되며,
모든 스레드가 공유하는 영역으로 다음과 같은 초기화 코드 정보들이 저장된다.
- Field Info: 멤버 변수의 이름, 데이터 타입, 접근 제어자 정보
- Method Info: 메소드 이름, return 타입, 함수 매개변수, 접근 제어자 정보
- Type Info: 클래스인지 인터페이스인지 여부 저장, Type의 속성, Super Class의 이름 등
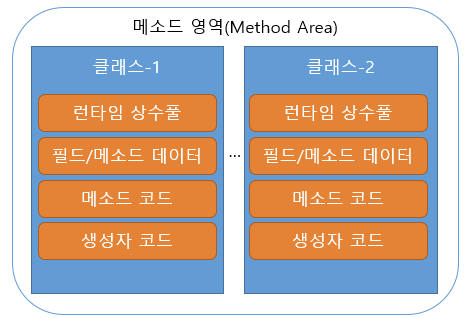
이러한 데이터들은 위에서 설명한 클래스 로더에 의해 동적으로(실행하면서 그때그때 필요한 클래스들만) 적재되며, 때문에 메서드 영역에는 어플리케이션에 사용되는 모든 클래스의 메타데이터가 항상 저장되는 것이 아님.
- 이를 동적 로딩이라고 함.
세부 내용은 클래스 로더 게시글 참조
- 또한, 메서드 영역에 저장된 클래스의 메타데이터가 힙 영역에 있는 객체들과 연결되어 있지 않다면, GC는 힙 영역에서 객체의 메모리를 회수하고, 해당 클래스의 인스턴스가 힙 영역에 없을 때, 메서드 영역에서도 클래스의 메타데이터를 삭제함.
1.2. 런타임 상수 풀(Runtime Constant Pool)
각 클래스 혹은 인터페이스마다 별도의 Constant Pool 테이블이 존재하는데, 클래스를 생성할 때 참조해야할 정보들을 상수로 가지고 있는 영역이다.
런타임 상수 풀은 클래스 로더가 메서드 영역에 클래스를 로딩할 때 같이 메서드 영역에 적재되는 부분으로
클래스 및 인터페이스의 상수 뿐만 아니라 메서드와 필드에 대한 모든 참조에 대한 정보를 가지고 있다.
저번 클래스 로더 게시물을 통해 우리는 클래스 로더가 .class 파일을 JVM에 로드할 떄 Linking 과정의 resolve 단계에서 심볼릭 레퍼런스를 실제 레퍼런스로 바꾼다는 것을 알고 있다.
이러한 심볼릭 레퍼런스(참조하는 클래스가 메서드 영역에 할당되어 있지 않은 경우, 초기화 값임) 혹은 실제 레퍼런스(참조하는 클래스가 메서드 영역에 할당되어 있는 경우)가 담겨 있는 영역을 런타임 상수 풀이라고 볼 수 있다.
또한 메서드와 필드에 대한 모든 레퍼런스까지 담고 있어, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아 참조한다.
1.3. Runtime Constant Pool과 String Pool의 차이
String Pool은 힙 영역에 존재하는 특수한 메모리 영역으로 동일한 문자열 리터럴을 재사용하기 위해 사용됨
- 리터럴: 상수의 일종으로 선언 없이 바로 사용할 수 있는 상수
Java는 기본 자료형을 제외한 객체를 만들 때, new 키워드로 만들어 참조형으로 만든다.
하지만, String은 예외적으로 new 키워드 없이도 객체를 만들 수 있다. 이를 “문자열 리터럴 생성 방식”이라고 함
String str1 = "Hello"; // 리터럴 생성 방식, String Pool에 저장
String str2 = "Hello"; // 이미 존재하는 "Hello"를 참조
String str3 = new String("Hello"); // Heap에 별도 저장Java 8 버전부터는 런타임 상수 풀은 "Metaspace" 영역(힙 외부에 존재하는 운영체제가 괸리하는 영역)에 저장되고, String Pool은 힙 영역에 저장되며 GC의 대상이 된다.
- Metaspace 영역에 대한 설명은 하단의 힙 영역 부분 참조
2. 힙 영역(Heap Area)
힙 영역은 메서드 영역과 함께 모든 스레드가 공유하며, JVM이 관리하는 프로그램 상에서 데이터를 저장하기 위해 런타임시 동적으로 할당하여 사용하는 영역.
자바에서는 “new” 키워드로 객체와 배열을 생성하며, 생성된 객체와 배열의 크기에 따라 힙 영역의 크기가 동적으로 변하고, 모든 스레드에서 공유되는 특징을 가진다.
- class
- interface
- enum
- array
힙 영역에 생성된 객체와 배열은 “Reference Type”으로서, JVM 스택 영역의 변수나 다른 객체의 필드에서 참조된다.
즉, 힙의 참조 주소는 각 스레드의 Stack이 갖고 있고, 해당 주소로 찾아가 힙 영역에 있는 인스턴스를 핸들링할 수 있다는 것이다.
만일 참조하는 변수나 필드가 없다면 의미 없는 객체가 되기 때문에, 이는 Garbage Collector의 수집 대상이 되어 힙 영역에서 자동으로 제거된다.
이처럼 힙 영역은 가비지 컬렉션(GC)의 대상이 되는 공간이며, 효율적인 가비지 컬렉션을 수행하기 위해 영역을 다음과 같이 나눈다.
(세부 내용은 JVM 실행 엔진 게시글 참조)
- Young Generation: 생명 주기가 짧은 객체를 GC 대상으로 하는 영역
- Eden: “new”를 통해 새로 생성된 객체가 위치, 정기적인 쓰레기 수집 후 살아남은 객체들은 Survivor로 이동
- Survivor 0 / Survivor 1: 최소 1번 이상의 GC로부터 살아남은 객체가 존재하는 영역
- Survivor 영역 중 하나는 비어있는 상태로 남아있어야 한다.
- Old Generation: 생명 주기가 긴 객체를 GC 대상으로 하는 영역, Young Generation에서 마지막까지 살아남은 객체가 이동
또한, 힙 영역에 관련하여 알면 좋은 영역이 있는데, 바로 “Metaspace”라는 영역이다.
Java 8 이후의 힙 영역의 구조는 정확히는 Young / Old Generation 만 포함된다.
Java 8 이전까지는 클래스의 메타데이터(클래스 정의, 메서드 정보, 클래스 변수 등)가 힙 영역의 “PermGen” 영역이라는 곳에 저장되었다.
이 경우에는 JVM 시작시, 설정된 고정 크기에 많은 클래스 로드와 많은 정적 데이터를 사용하는 경우 PermGen 영역이 고갈되면서 java.lang.OutOfMemoryError: PermGen space 오류로 이어지곤 했다.
그러나, Java 8 이후부터는 Metaspace라는 운영체제가 관리하는 네이티브 메모리 영역으로 분리하여 JVM이 메모리 요구사항에 따라 필요한 만큼 동적으로 메모리를 할당 받을 수 있게 되었다.
3. 스택 영역(Stack Area)
스택 영역은 메서드 호출 시 지역 변수, 매개변수, 함수 호출 내역 등이 저장되는 영역이다.
각 스레다마다 개별적으로 생성되는 영역이며, 메서드 호출 시마다 각각의 스택 프레임(그 메서드만을 위한 공간)이 생성되고, 메서드 수행이 끝나면 해당하는 스택 프레임은 삭제된다.
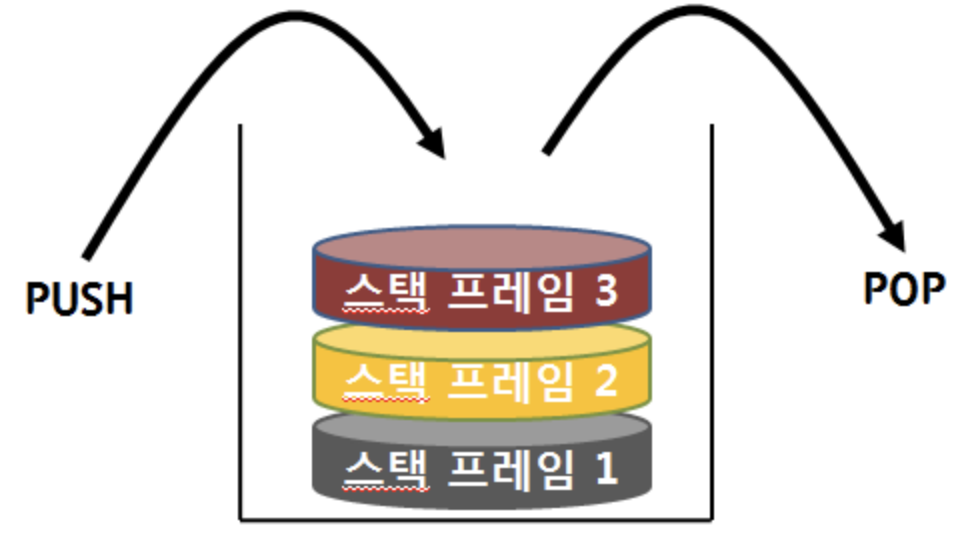
스택 프레임에는 아래와 같은 데이터들이 저장됨
- Local Variables
- 함수에서 쓰이는 매개변수 혹은 지역 변수들이 저장.
- 함수 내에 몇 개의 지역 변수가 있을지는 컴파일 시점에 정해지고, 런타임에 메모리가 할당됨
- Operand stack
- 피연산자들을 stack 자료구조로 저장하는것
- Frame data
- 반환 타입, 상수 풀에 대한 참조와 같은 데이터들이 포함됨
- 예를 들어, 만약 어떤 로직에서 상수 풀의 데이터를 사용하는 로직이 있다면, 해당 로직을 수행하기 위해 프레임 데이터의 상수 풀을 참조하는 포인터를 이용한다.
단, 데이터의 타입에 따라 스택과 힙에 저장되는 방식이 다르다는 점에 유의해야함.
- 원시 타입 변수는 스택 영역에 직접 값을 가짐
- boolean
- short
- int
- long
- byte
- float
- double
- char
- 참조 타입 변수는 힙 영역이나 메소드 영역의 객체 주소를 스택 영역에 가짐
스택 영역은 각 스레다마다 하나씩 존재하며, 스레드가 시작될 때 할당됨
프로세스가 메모리에 로드될 때 스택 사이즈가 고정되어 있어, 런타임 간에는 스택 사이즈를 변경할 수 없다.
만일 고정된 크기의 JVM 스택에서 프로그램 실행 중 메모리 공간이 모자르다면 StackOverFlowError가 발생한다.
또한, 새로 생성될 쓰레드에게 메모리가 부족해 스택을 할당할 수 없거나, 스택의 확장에 충분한 메모리를 확보할 수 없는 경우 OutOfMemoryError 가 발생한다.
쓰레드를 종료하면 런타임 스택도 사라진다.
4. PC 레지스터 (Program Counter Register)
PC 레지스터 영역은 각 스레드마다 할당되며, 각 스레드의 현재 수행 중인 JVM 명령의 주소가 저장되는 영역이다.
일반적으로 프로그램의 실행은 CPU에서 명령어(Instruction)을 실행하는 과정으로 이루어지는데, CPU는 연산을 수행하는 동안 필요한 정보를 레지스터라는 CPU 내의 기억장치를 이용한다.
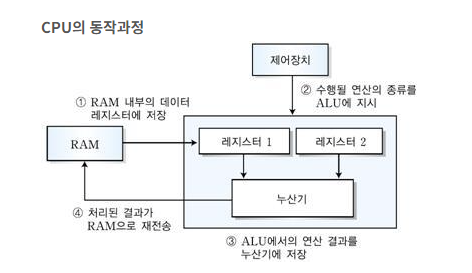
예를 들어, “add(A, B)”라는 명령어를 수행할 때, A와 B를 가져오고 이를 더하라는 연산이 순서대로 진행될 때,
CPU는 A 값을 로드하고 B 값도 로드하는 동안 A의 값을 CPU가 기억할 필요가 생긴다.
이 떄, 사용되는 저장공간이 CPU내의 Register이다.
그렇다면, JVM에서는 왜 또 별도로 PC Register라는 것을 사용할까?
첫번째로, 멀티쓰레딩 환경을 지원하기 위함이다.
스레드는 각자의 메소드를 실행하며, 멀티스레드 환경을 보장하기 위해 JVM에서는 각 스레드별로 수행할 명령어의 주소를 알 필요가 있다.
두번째로는 자바 또한 OS의 입장에서는 하나의 프로세스라는 것이다.
자바는 플랫폼으로부터 독립성을 추구하는 언어로 JVM이라는 가상머신으로 OS 위에서 가동되며, 따라서 가상머신의 자원을 활용하여야 한다.
떄문에 자바는 CPU Register를 이용하여 CPU에 직접 연산을 수행하도록 하는 것이 아닌,
현재 작업하는 내용을 CPU에게 연산으로 제공해야하며, 이를 위한 버퍼 공간으로 PC Register라는 CPU Register와 별개의 메모리 영역을 만들게 된 것이다.
자바는 스레드마다 수행하는 메소드의 JVM 명령(Instrution)의 주소를 PC Register로 저장하는데,
만일 자바가 아닌 다른 언어(C, 어셈블리)의 메소드를 수행하고 있다면, 해당 명령어의 주소는 저장하지 않고, “undefined” 값을 기록한다.
이러한 undefined 상태의 메소드들을 “네이티브 메소드”라고 부르며 이는 성능 향상에 도움을 주기도 한다.
5. 네이티브 메서드 스택 (Native Method Stack)
자바 이외의 언어로 작성된 네이티브 코드(C, C++, 어셈블리)를 실행하기 위한 공간으로, JIT 컴파일러에 의해 변환된 네이티브 코드 역시 여기서 실행된다고 할 수 있다.
사용되는 메모리 영역으로는 일반적인 C 스택을 사용한다.
일반적으로 메서드를 실행하는 경우 JVM 스택에 쌓이다가 해당 메서드 내부에 네이티브 방식을 사용하는 메서드가 있다면 해당 메서드는 네이티브 스택에 쌓인다.
그리고, 네이티브 메서드 수행이 끝나면 다시 자바 스택으로 돌아와 다시 작업을 수행한다.
이 덕분에, 네이티브 코드로 되어 있는 함수의 호출을 자바 프로그램 내에서도 직접 수행할 수 있고 그 결과를 받아올 수도 있는 것이다.
네이티브 메서드 스택은 JNI(Java Native Interface)를 통해 자바와 네이티브 코드 간의 상호 작용을 지원하는데, JNI는 자바 어플리케이션에서 네이티브 코드를 호출할 수 있게 해주는 인터페이스라고 할 수 있다.
[ JNI (Java Native Interface) ]
JNI는 자바가 다른 언어로 만들어진 어플리케이션과 상호 작용할 수 있는 인터페이스를 제공하는 프로그램이다.
JNI는 Native Method를 적재하고 수행할 수 있도록한다.
자바 코드상에서native키워드로 선언된 메소드는 자바가 아닌 네이티브 코드로 구현되며,
JNI가 이렇게 작성한 자바 메서드와 네이티브 코드 간의 상호작용을 가능하게 한다.public class NativeExample { static { // C/C++ 라이브러리(네이티브 메서드 라이브러리) 로드 System.loadLibrary("NativeLib"); } public native void nativeMethod(); // 네이티브 메서드 선언 public static void main(String[] args) { NativeExample example = new NativeExample(); example.nativeMethod(); // 네이티브 코드 호출 } }
참조
https://inpa.tistory.com/entry/JAVA-☕-JVM-내부-구조-메모리-영역-심화편#런타임_데이터_영역_runtime_data_area
https://velog.io/@ddangle/Java-런타임-데이터-영역Runtime-Data-Area에-대해
