데이터 엔지니어링 공부를 하다면서 느끼는건데, 마냥 데이터라고 파이썬 위주로 쓰는 것도 아닌 것 같다.
하둡, Spark 등 많은 데이터 인프라 관련 기술들이 JVM 위에서 동작하기도 하고,
현직에 계신 멘토님 말씀으로는 java로 작성된 오픈 소스들을 커스텀해서 포팅하는 작업도 굉장히 많이 한다고 한다.
이를 위해서라도 Java에 대해 알 필요가 있어서 Java의 핵심이라고 볼 수 있는 JVM에 대해 정리해보고자 한다.
이번 게시물에서는 JVM의 동작 방식과 구조에 대해 간략히 살펴보고, JVM의 첫 관문이라 볼 수 있는 "클래스 로더" 라는 것에 대해 알아볼 예정이다.
이 게시물을 시작으로 JVM 이라는 시리즈로 엮어서 JVM의 구성 요소들에 대해서 하나씩 자세히 살펴볼 예정이다.
1. JVM의 동작 방식
JVM의 역할은 자바 애플리케이션을 클래스 로더를 통해 읽어 자바 API와 함께 실행하는 것이다.
다음은 자바 소스 파일을 어떤 동작으로 코드를 읽는 지에 대한 요약 도식이다.
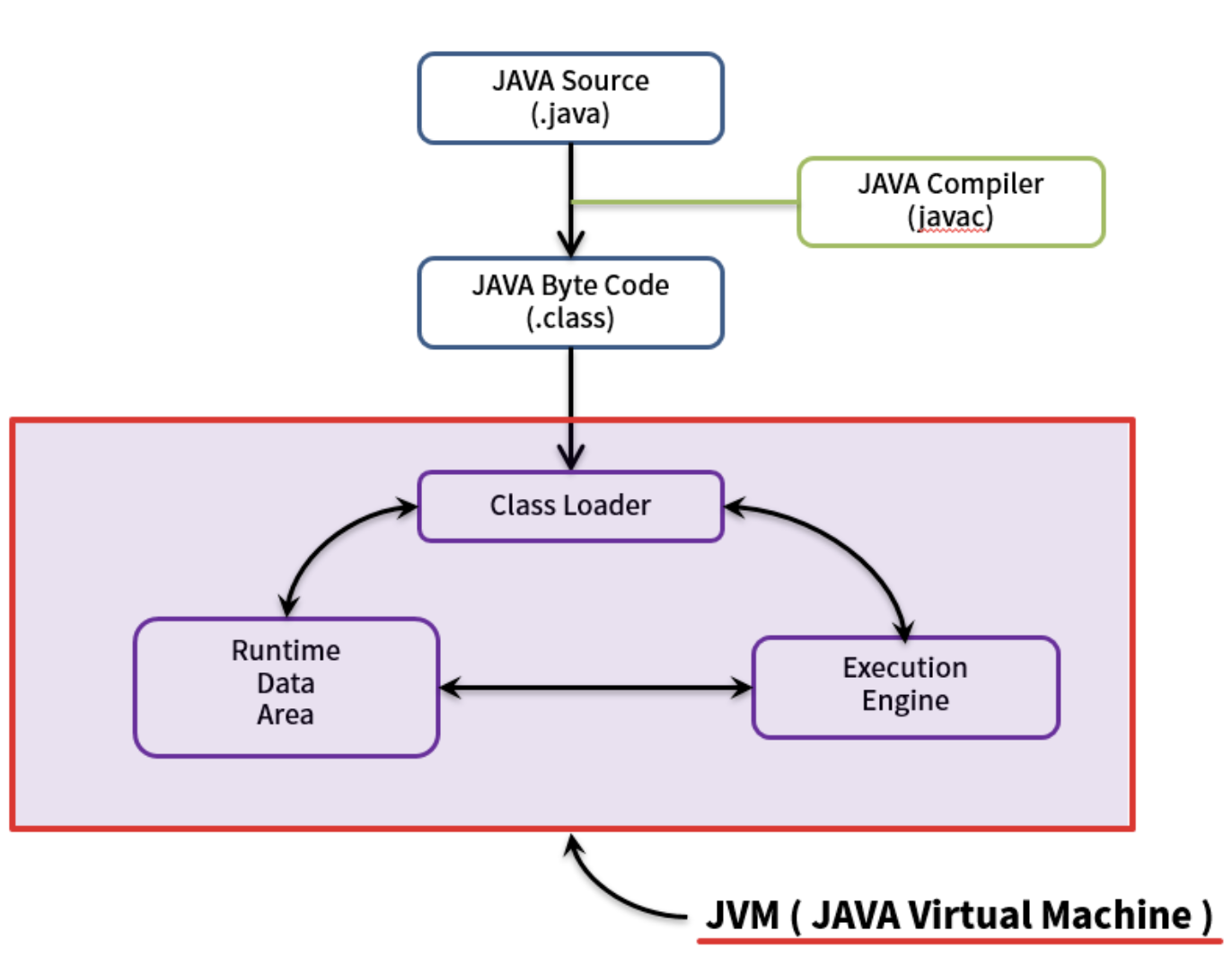
- 자바 프로그램을 실행하면 JVM은 OS로부터 메모리를 할당 받는다.
- 자바 컴파일러(javac)가 자바 소스코드(.java)를 자바 바이트코드(.class)로 컴파일한다.
- 클래스 로더는 동적 로딩을 통해 필요한 클래스들을 로딩 및 링크하여 Runtime Data Area에 올린다.
- Runtime Data area에 로딩된 바이트 코드는 Execution Engine에 의해 해석됨
- 이 과정에서 Execution Engine에 의해 가비지 컬렉터의 작동과 스레드의 동기화가 이루어짐
2. JVM 구조
다음은 위에서 본 도식에서 JVM에 해당하는 부분을 좀 더 상세화한 도식이다.
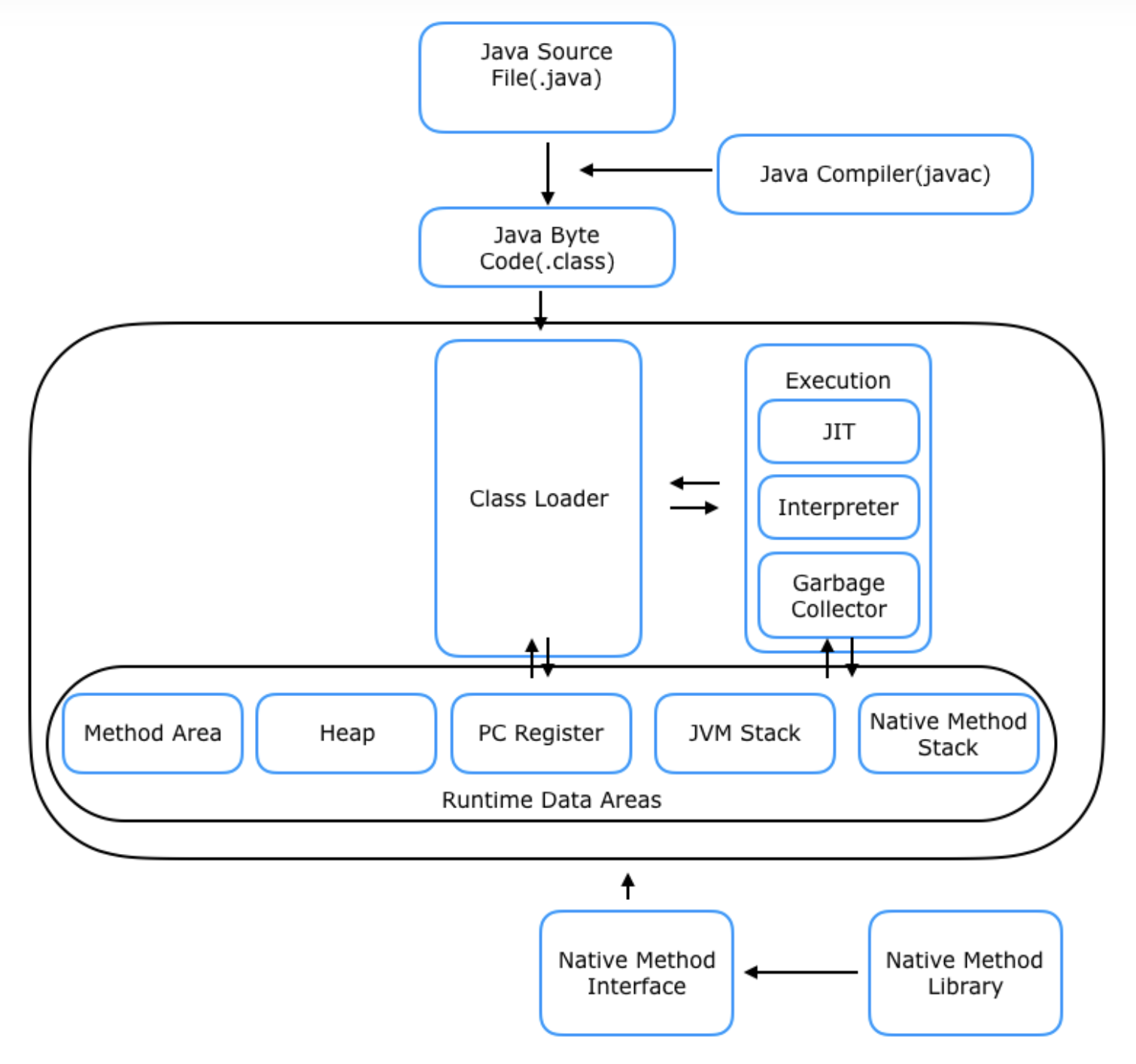
위 사진처럼 JVM은 다음과 같이 구성된다.
- 클래스로더
- 실행 엔진
- 인터프리터
- JIT 컴파일러
- 가비지 콜렉터
- 란타임 데이터 영역
- 메소드 영역
- 힙 영역
- PC Register
- 스택 영역
- 네이티브 메소드
- JNI (Native Method Interface)
- 네이티브 메소드 라이브러리
3. 클래스 로더(Class Loader)
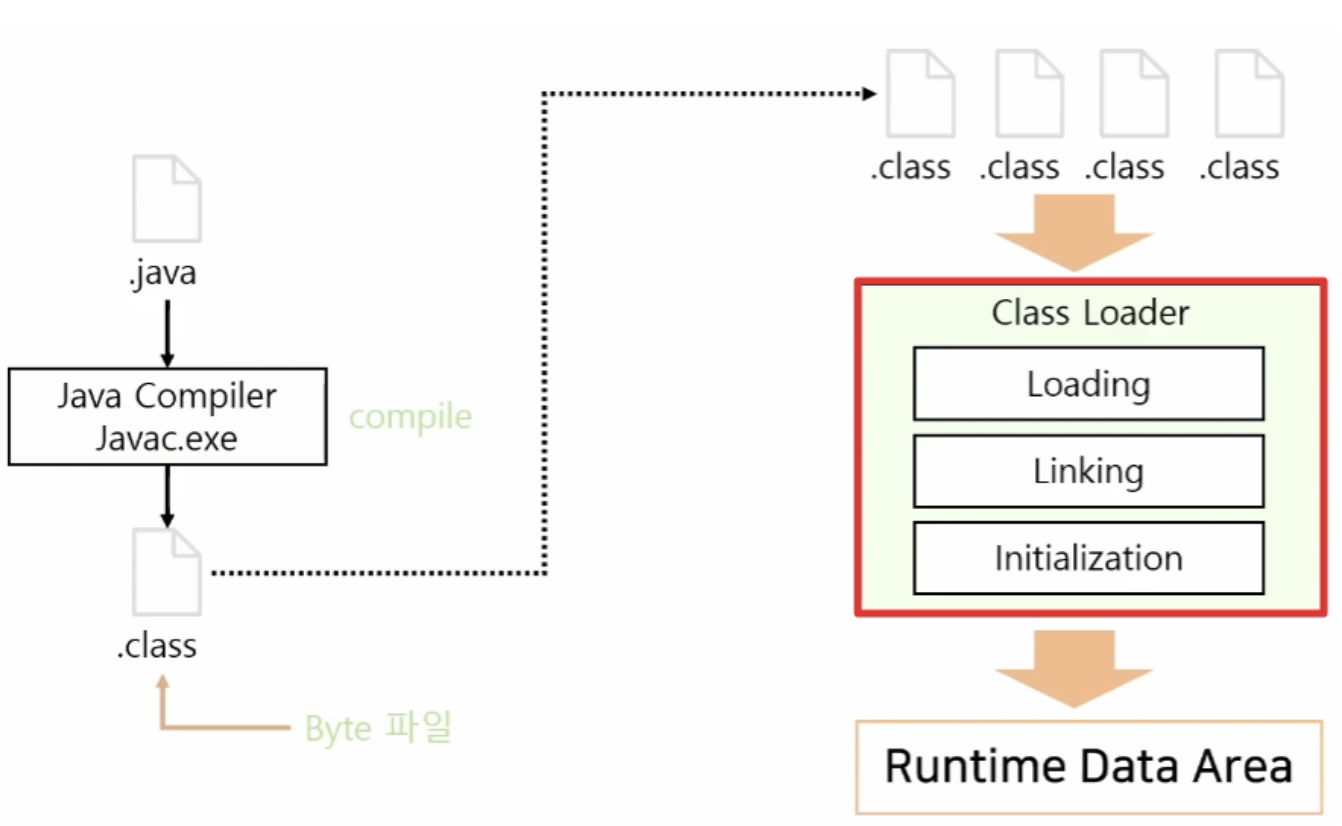
클래스 로더는 JVM 내로 클래스 파일(.class)을 동적으로 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈임.
- 로드: 클래스 정보를 런타임 데이터 영역에 저장
- 링크: 로드 + 로딩된 클래스 파일에 대해 검증 → 준비 → 해석
즉, 로드된 바이트 코드들을 엮어서 JVM의 메모리 영역인 Runtime Data Area에 배치함.
클래스를 메모리에 올리는 로딩은 한번에 메모리에 올리지 않고, 어플리케이션에서 필요한 경우 동적으로 메모리에 적재하게 되며, 이는 메모리를 효율적으로 관리할 수 있게됨
클래스 로더는 다음 3단계를 통해 클래스 파일을 로딩함
- Loading
- 자바 바이트코드(.class)를 메소드 영역에 저장
- 각 자바 바이트코드는 JVM에 의해 메소드 영역에 다음 정보들을 저장
- 로드된 클래스를 비릇한 그의 부모 클래스의 정보
- 클래스 파일과 Class, Interface, Enum의 관련 여부
- 변수나 메소드 등의 정보
- Linking
- verify: 읽어 들인 클래스가 자바 언어 명세 및 JVM 명세에 명시된 대로 잘 구성되어 있는지 검사
- prepare: 클래스가 필요로 하는 메모리를 할당하고, 클래스에서 정의된 필드. 메소드, 인터페이스를 나타내는 데이터 구조를 준비
- resolve: 클래스의 상수 풀 내 심볼릭 레퍼런스를 메소드 영역에 있는 실제 레퍼런스로 교체
- 심볼릭 레퍼런스: 이름 등으로 참조되는 형태
- 예:
java.lang.String
- 예:
- 실제 레퍼런스: 실행 시점에 JVM은 예를 들어, 심볼릭 레퍼런스를 사용하여 메모리에 로드된
String클래스의 실제 메모리 주소를 찾은 것
- 심볼릭 레퍼런스: 이름 등으로 참조되는 형태
- Initialization
- 클래스 변수들을 적절한 값으로 초기화, 즉, static 필드들이 설정된 값으로 초기화 됨.
3.1. 클래스 로더의 종류
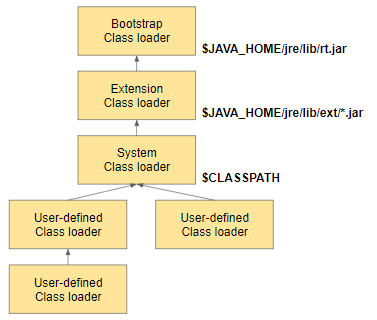
클래스로더는 위와 같은 계층 구조를 가지며, 크게 3종류(계층)로 분류함
- 부트스트랩 클래스로더
- 확장 클래스로더
- 어플리케이션 클래스로더
3.1.1. 부트스트랩 클래스 로더
JVM 시작 시 가장 최초로 실행되는 클래스로더
자바 클래스를 로드할 수 있는 자바 자체의 클래스 로더와 최소한의 자바 클래스
(java.lang.Object, java.lang.Class, java.lang.ClassLoader, java.util.* 등)을 로드함
3.1.2. 확장 클래스 로더
확장 클래스 로더는 부트스트랩 클래스 로더를 부모로 갖는 클래스 로더로서, 확장 자바 클래스들을 로드
java.ext.dirs 환경 변수에 설전된 디렉토리의 클래스 파일을 로드하고, 이 값이 설정되어 있지 않은 경우
$(JAVA_HOME)/jre/lib/ext 에 있는 클래스 파일들을 로드
3.1.3. 애플리케이션 클래스 로더
자바 프로그램 실행 시 지정한 Classpath에 있는 클래스 파일 혹은 jar에 속한 클래스들을 로드함
쉽게 말하면 우리가 만든 .class 확장자 파일을 로드함
시스템 클래스 로더라고도 불림
3.2. 계층형 클래스로더 구조의 동작 방식
JVM 클래스 로더는 위와 같이 계층형 구조를 가지며, 새로운 클래스를 로드해야할 때, 다음과 같이 동작
- JVM의 “메소드 영역”에 클래스가 이미 로드되어 있는지 확인.
만일 로드되어 있는 경우 해당 클래스를 사용 - “메소드 영역”에 클래스가 로드되어 있지 않을 경우, “애플리케이션 클래스 로더”에 클래스 로드를 요청
- “애플리케이션 클래스 로더”는 “확장 클래스 로더”에 요청을 위임
- “확장 클래스 로더”는 “부트스트랩 클래스 로더”에 요청을 위임
- “부트스트랩 클래스 로더”는 부트스트랩 Classpath(JDK/JRE/LIB)에 해당 클래스가 있는지 확인
클래스가 존재하지 않는 경우 “확장 클래스 로더”에게 요청을 넘김 - “확장 클래스 로더”는 확장 Classpath(JDK/JRE/LIB/EXT)에 해당 클래스가 있는지 확인
존재하지 않는 경우 “애플리케이션 클래스 로더”에게 요청을 넘김 - “애플리케이션 클래스 로더”는 시스템 Classpath에 해당 클래스가 있는지 확인.
존재하지 않는 경우 ClassNotFoundExeception을 발생시킴
3.3. 동적 로딩
자바의 클래스 로딩은 클래스 참조 시점에 JVM에 코드가 링크되고, 실제 런타임 시점에 로딩되는 동적 로딩 과정을 거침.
이는, JVM이 미리 모든 클래스에 대한 정보를 메소드 영역에 로딩하지 않는다는 것을 의미함
3.3.1. 로드타임 동적 로딩
JVM이 시작되고 .class 파일의 클래스를 로드할 때, 모든 클래스의 최상위 클래스인 Objcet와 그밖의 java.lang.util 등 일부 자바 API 패키지를 함꼐 로드함.
3.3.2. 런타임 동적 로딩
클래스의 method 등이 동작할 때 필요해지는 클래스들이 있음.
즉, 실질적으로 클래스의 내부에서 클래스가 필요해지는 시점에 로드되는 방식이 런타임 동적 로딩
public class Main {
public static void main(String[] args) {
try {
Class clazz = Class.forName("Hello");
Hello hello = (Hello) clazz.getDeclaredConstructor().newInstance();
hello.say();
} catch (Exception e) {
e.printStackTrace();
}
}
}
class Hello {
public Hello() {
System.out.println("hello??");
}
public void say() {
System.out.println("say Hello");
}
}위의 Main 클래스는 Class.forName() 메서드를 사용하여 Hello 라는 클래스의 객체를 만드려고함.
하지만, 메서드를 직접 실행하기 전까지 forName()내의 “Hello”는 그냥 String 임.
즉, Hello 클래스 정보를 바탕으로 인스턴스를 만들 수 있는 시기는 런타임 때 가능하다는 뜻.
어처럼 런타임 동적 로딩은 컴파일 시기에는 해당 클래스에 대한 정보를 로드하지 않고 코드가 실행될 때 클래스 정보를 로드할 수 있을 경우를 의미함.
3.4. 지연로딩
지연 로딩은 JVM에서 동작하는 특수한 동적로딩
클래스 파일을 로드할 때, 메서드 등에서 객체 인스턴스를 만들 때 사용하는 클래스들이 있을 것이다.
JVM 입장에서 하나의 클래스 파일을 로드할 때 알게되는 여러 클래스들이 있을 것인데, 이 클래스를 한꺼번에 로드하기보다 해당 클래스가 호출되는 시점에 로드하는 지연 로딩 방식을 사용한다.
이는 메모리를 효율적으로 관리하기 위함
public class Main {
public static void main(String[] args) {
System.out.println("hello");
Test test = new Test();
}
}
class Test {
public Test() {
System.out.println("maked Test");
}
}위의 Test 클래스는 Main 클래스가 로드될 때 함께 로드되지 않음
“hello”를 출력한 이후의 코드를 만나면 Test 클래스를 로드하고 이를 이용하여 인스턴스를 생성함.
시리즈 내의 다음 게시물은 JVM의 실행 엔진에 대해 다뤄보도록 하겠다.
질의 응답
질문 #1: 파이썬과 자바의 런타임에서의 상속과 오버로딩의 차이 + 개발시 고려해야할 차이점
1.1. 파이썬의 클래스 메모리 적재 흐름
일단 파이썬에서 클래스가 어떻게 메모리에 적재되는지 알아보겠습니다.
파이썬은 소스코드를 컴파일을 통해 해석한 바이트코드를 인터프리터를 통해서 각 플랫폼에 맞는 기계어로 해석하여 실행을 하는데요.
이러한 특성 때문에, 파이썬도 컴파일 시점에서부터 모든 클래스들을 메모리에 적재하지 않고, 인터프리터가 한 줄 씩 해석하여 실행하면서 만난 클래스들만 바로 메모리에 적재합니다.
예를들면 다음과 같습니다.
class MyClass:
def __init__(self):
self.value = 42
# 이 시점에서 MyClass는 메모리에 올라간다 (네임스페이스에 등록됨).위 코드에서 MyClass 라는 클래스는 코드가 실행되는 순간. 즉, 파이썬 인터프리터가 class MyClass: 줄을 만나면 그 즉시 클래스 정의가 메모리에 올라갑니다.
이 클래스 정의는 메모리의 메타데이터 영역에 저장되며, 이는 클래스 자체에 대한 정보(메서드, 속성 등)를 담고 있습니다.
이 떄의 클래스는 인스턴스가 아직 생성되지 않아 힙 영역에는 저장되지 않고, 클래스의 정의 정보는 네임스페이스에 등록되어 관리됩니다.
그 후, MyClass 의 인스턴스가 생성이 되면, 생성된 객체는 메모리의 힙 영역에 할당됩니다.
따라서, 파이썬의 클래스가 메모리에 적재되는 과정은 마치 자바처럼 런타임에 동적으로 할당하는 것과 큰 관점에서 동일한 흐름을 갖는다고 볼 수 있습니다.
1.2. 자바와의 클래스 메모리 적재 차이점
큰 흐름은 두 언어 모두 컴파일이 아닌 런타임 시점에 클래스를 로드한다는 점에서 일치하다는 것을 살펴보았습니다.
하지만, 좀 더 깊이 본다면 큰 차이가 있습니다.
첫번째로는 클래스 로더의 유무에 따른 차이입니다.
파이썬의 경우 클래스 로더 없이 클래스 정의에 관한 코드를 바로 메모리에 적재하는데 이는, 자바의 클래스 로더를 통한 방식보다 간단하나, 클래스 간의 참조나 의존성에 대한 사전 검증이 부족합니다.
이는 런타임 오류로 이어질 수 있으며, 대규모 시스템에서 안정성이 떨어질 수도 있다고 하네요
반면에 자바는 클래스 로더를 통한 검증과 링킹을 통해 클래스 파일을 검증하고 참조를 연결하는 등의 과정을 거쳐 상호 참조와 의존성을 미리 확인하여 안정성을 높입니다. 하지만, 이러한 복잡한 과정으로 인해 초기 지연이 발생할 수 있다고 하네요.
두번째로는 클래스 로딩 시점의 차이입니다.
파이썬의 경우 클래스 정의 코드를 만나면 그 즉시 메모리의 적재된다고 말씀드렸는데요.
이는 해당하는 클래스가 외부로부터 정적 참조를 당하거나, 인스턴스를 아직 생성하지 않는 등 아직 사용되지 않는 클래스 임에도 불구하고 매모리에 적재되는 것을 의미합니다.
즉, 자바와 달리 지연 로딩을 수행하지 않고 즉시 로딩을 수행한다고 볼 수 있습니다.
이러한 즉시 로딩(eager loading)은 매모리 낭비 가능성이 있지만, 코드 구조가 간단해지고 성능이 예측 가능하며, 클래스가 항상 준비된 상태인 등의 장점이 있습니다.
반면에 자바의 지연 로딩은 메모리를 효율적으로 관리하여 리소스를 필요할 때만 로드함으로써 성능을 최적화할 수 있습니다. 이는 특히 대규모 데이터베이스나 네트워크 요청이 많은 시스템에서 유용하다고 하네요.
1.3. 상속을 구현한 클래스의 실행순서
앞에서 파이썬과 자바의 클래스가 적재되는 과정에서의 공통점과 차이점에 대해 살펴보았습니다.
이번에는 이를 기반으로 두 언어가 상속을 구현한 클래스를 실행할 때 어떤 차이점이 있는지 살펴보겠습니다.
파이썬에서의 순서
- 파이썬 인터프리터가 클래스를 정의하는 줄을 만나면, 해당 클래스는 즉시 메모리에 적재됩니다.
- 부모 클래스가 먼저 메모리에 올라가며, 그 후 자식 클래스가 메모리에 올라가 정의되면 부모 클래스를 참조하여 상속 관계가 설정됩니다.
- 자식 클래스에서 부모 클래스의 메서드를 오버라이딩할 경우, 자식 클래스의 메서드가 부모 클래스의 동일한 이름의 메서드를 덮어씁니다.
- 파이썬에서는 상속 관계나 오버라이딩된 메서드도 모두 객체로 취급되며, 해당 클래스가 정의되면 네임스페이스에 등록됩니다.
이후 인스턴스를 생성할 때 힙 영역에 객체가 할당되고, 이 객체는 상속받은 속성과 메서드를 포함하게 됩니다.
자바에서의 순서
- JVM은 프로그램 실행 중 필요할 때(
new키워드를 통한 인스턴스 생성 혹은 정적 필드/메서드를 참조할 때) 부모 클래스를 먼저 로드한 후 자식 클래스를 로드합니다.
이는 클래스 정의 코드가 보이면 바로 메모리에 적재했던 파이썬과 차이를 보입니다. - JVM은 부모 클래스와 자식 클래스를 로드한 후 링킹 과정을 통해 두 클래스를 연결하고, 초기화 과정을 거쳐 정적 필드와 초기화 블록을 실행합니다.
- 오버라이딩된 메소드의 경우 런타임 시점에 실제로 호출되는 메서드는 자식 클래스의 것이 됩니다.
- 자바에서도 객체가 생성될 때 힙 영역에 객체가 할당되며, 이 객체는 부모와 자식 클래스에서 정의된 모든 속성과 메서드를 포함하게 됩니다.
이 밖에도 상속이라는 개념 구현에서 두 언어는 다른 점이 있습니다.
대표적으로 파이썬은 다중 상속을 지원하고, 자바는 단일 상속만 지원한다는 점입니다.
이러한 기능적 차이를 알아두는 것도 어플리케이션 설계에 어떤 프로그래밍 언어를 채택할 것인지 정하는 지표 중 하나가 될 것입니다.
1.4. 오버로딩의 실행 과정
일단 오버로딩은 파이썬에서는 사실 기본적으로 지원되는 기능은 아닙니다.
오버로딩은 정적 타이핑 언어에서 지원하는 기능으로 동적 타이핑 언어인 파이썬에서는 이를 직접적으로 지원하지는 않습니다.
대신 가변 인자나 조건문 등을 활용해 유사한 기능을 구현할 수 있습니다.
이러한 사항들을 고려하여 실행과정을 비교하면 다음과 같습니다.
자바에서의 오버로딩 실행 과정
자바는 정적 타이핑 언어로 컴파일 시점에 어떤 메서드가 호출될지 결정됩니다.
즉, 메서드 호출시 컴파일러가 매개변수의 타입과 개수를 기준으로 적절한 메서드를 미리 선택합니다.
아래는 컴파일 후, JVM이 컴파일된 바이트 코드를 실행하는 과정입니다.
- 자바에서는 클래스가 처음으로 사용될 때 클래스 로더가 해당 클래스를 메모리에 적재합니다.
이 때 클래스에 정의된 오버로딩된 메서드를 포함한 모든 메서드가 메모리에 적재됩니다. - 클래스가 메모리에 적재된 후, JVM은 링킹 과정을 통해 클래스의 모든 메서드를 검증하고 참조를 연결합니다.
오버 로딩된 메서드는 컴파일 시점에 매개변수의 타입과 개수를 기준으로 구분되어, 링킹 과정에서 각 메서드가 올바르게 연결됩니다. - 프로그램 실행 중 특정 메서드가 호출될 떄, JVM은 컴파일 시점에 결정된 매개변수 정보에 따라 적절한 오버로딩 메서드를 실행합니다.
이 과정에서 추가적인 런타임 결정 없이 바로 해당 메서드가 실행됩니다.
파이썬에서의 오버로딩 실행 과정
파이썬은 엄밀하게 따지면, 자바와 동일한 개념의 오버로딩을 지원하지 않습니다.
파이썬은 동적 타이핑 언어이기 때문에 동일한 이름의 함수를 여러 번 정의하면 마지막에 정의된 함수만 남게됩니다.
대신 파이썬에서는 가변인자(*args, kwargs), 타입 힌트와 조건문 사용 등을 통해 오버로딩을 구현할 수 있습니다.
예를 들면 다음과 같습니다.
class Calculator:
# 가변 인자를 사용하여 다양한 경우 처리
def add(self, *args):
if len(args) == 2 and all(isinstance(i, int) for i in args):
return args[0] + args[1]
elif len(args) == 2 and all(isinstance(i, float) for i in args):
return args[0] + args[1]
elif len(args) == 3 and all(isinstance(i, int) for i in args):
return sum(args)
else:
raise ValueError("Invalid arguments")
calc = Calculator()
print(calc.add(1, 2)) # 두 개의 정수
print(calc.add(1.0, 2.0)) # 두 개의 실수
print(calc.add(1, 2, 3)) # 세 개의 정수위 코드는 파라미터 갯수와 타입에 따라서 다양한 입력에 대해 다른 동작을 수행합니다.
이러한 방식으로 구현했을 때, 파이썬에서 오버로딩 메소드의 실행 과정은 다음과 같습니다.
- 파이썬에서는 코드를 실행하면서 클래스 정의 코드를 만나는 순간 그 클래스와 내부의 모든 메서드들이 즉시 네임스페이스에 등록되고 메모리에 적재됩니다.
이는 클래스 정의와 동시에 해당 클래스 내 모든 함수가 바로 사용 가능한 상태라는 것을 의미합니다. - 함수 호출시 전달 받은 인자의 개수나 타입에 조건을 두어 다른 동작을 수행하게 됩니다.
1.5. 개발시 고려해야할 언어간의 다양한 차이점들
위에서 파이썬과 자바의 클래스 메모리 적재 방식과 실행 순서에 따른 차이점들을 살펴보았습니다.
따라서, 이런 차이점들을 고려하여 개발을 진행하면 될 것 같습니다.
예를 들어, 파이썬은 동적 타이핑, 자바는 정적 타이핑 언어로 각자의 장단점이 있습니다.
동적 타이핑 언어는 코드가 간결해지고, 개발 속도가 빨라지며 변수내에 다양한 타입의 요소들을 집어넣는 등의 유연성을 제공하지만, 위에서 언급했듯이 오버로딩 메소드의 경우 런타임 시점에 전달받은 인자의 타입과 개수를 확인하여 처리하여 성능 저하의 가능성이 있습니다.
반대로 자바는 정적 타이핑 언어로 오버로딩 메소드는 이미 컴파일 시점에 최적화가 되어 비교적 성능 저하 가능성이 낮다고 볼 수 있습니다.
다른 예시로는 클래스 로더 유무에 따른 안정성의 문제를 고려해볼 수 있겠습니다.
위에서 언급했듯이 클래스 로더는 클래스를 단순히 적재하는 것 뿐만 아니라 링킹 과정을 통해 클래스를 검증하고, 참조들을 연결하여 안정성을 높입니다.
따라서, 이러한 클래스 로더가 있는 자바가 파이썬보다 대규모 어플리케이션에서 안정적이다 라고 볼 수 있겠습니다.
제 개인적인 생각으로는 이런 이유들 덕분에 하둡이 JVM 위에서 동작하는 것이 아닌가 싶네요
마지막으로는 lazy loading 과 eager loading 차이에 따른 차이도 고려해볼 수 있겠습니다. 지연 로딩을 통한 리소스의 효율적인 사용은 대규모 데이터베이스와 네트워크 애플리케이션에 유리하다고 하네요.
반면에 즉시 로딩은 코드의 구조가 간단해지고, 클래스의 구성 요소가 항상 준비된 상태로 있어 성능 예측이 비교적 쉬워진다는 점이 있습니다.
질문 #2: 지연로딩이 Java에서만 활용되는 특징인 이유
2.1. 지연 로딩 방식의 단점과 다른 언어는 기본적으로 지원하지 않는 이유
단점 1: 성능 및 복잡성
Java의 동적 클래스 로딩(지연로딩)은 메모리 공간을 필요할 때만 할당하여 효율적으로 관리할 수 있게하나, 그만큼 복잡성과 성능 저하가 따릅니다.
동적 로딩은 런타임에 클래스를 찾아서 메모리에 로드하고, 이를 안전하게 사용하기 위해서는 링킹 과정을 통한 검증과 메모리 단에서의 준비, 초기화 등의 추가 과정이 필요합니다.
이 과정은 시스템 자원을 더 많이 소모할 수 있어서 성능 저하를 초래할 수 있습니다.
C/C++의 경우에는 이러한 복잡성을 피하기 위해 정적 클래스 로딩을 선호합니다.
이들은 대부분의 경우 컴파일 시점에 필요한 모든 라이브러리를 링크하고, 런타임에 추가적인 클래스를 로드하는 방식은 제한적으로 사용됩니다.
이는 성능의 최적화와 코드 예측 가능성을 높이는 데 기여한다네요.
따라서, 성능을 최우선으로 두는 언어의 경우 이러한 동적 로딩보다는 정적 로딩을 선호한다고 볼 수 있겠습니다.
단점 2: 보안 및 안정성의 문제
동적 로딩은 악의적인 코드가 시스템에 침투할 수 있는 경로가 될 수 있어 보안상의 위험도 있습니다.
Java는 이를 해결하기 위해 강력한 보안 모델을 제공한다고 합니다.
또한 런타임에 로드된 클래스는 타입 안정성을 보장하기가 어렵습니다.(컴파일 시점에 알 수 없으므로 예측을 하기가 어려움)
때문에, Java에서는 다양한 방법을 통해 타입 안정성 문제를 해결하는 매커니즘을 제공합니다.
- 클래스 로더 위임 모델
- 부모 클래스 로더가 먼저 로딩을 수행하도록 기회를 위임
- 이를 통해 서로 다른 클래스로더가 동일한 클래스를 로드하는 것을 방지함
(같은 클래스더라도 여러 클래스로더가 로드하면, 서로 다른 타입으로 인식하는 문제가 있기 때문)
- 이를 통해 서로 다른 클래스로더가 동일한 클래스를 로드하는 것을 방지함
- 세부 내용은 본문 https://velog.io/@jy016011/Java-클래스-로더#32-계층형-클래스로더-구조의-동작-방식 참조
- 부모 클래스 로더가 먼저 로딩을 수행하도록 기회를 위임
- ClassCastException 및 런타임 타입 검사
- 런타임 타입 검사를 통해 동적 로드된 클래스의 타입을 검사하고, 맞지 않을 경우 “ClassCastException”을 발생시킵니다.
- 강력한 네임스페이스 관리
- 각 클래스 로더가 관리하는 네임스페이스를 엄격하게 구분하여 동일한 이름의 클래스라도 서로 다른 네임스페이스에서 독립적으로 관리될 수 있도록 함.
다음은 JVM의 클래스 로더에 대해 다루는 논문인데요. 이 답변을 작성하는데 많은 참고가 된 자료입니다.
설명이 잘 되어 있으니 시간 나실 때 보시는걸 추천드립니다.
https://dl.acm.org/doi/pdf/10.1145/286942.286945
2.2. 그럼 왜 자바에서는 동적 로딩을 쓸까?
네트워크 기반 애플리케이션 지원을 위함
Java는 처음부터 네트워크 기반 애플리케이션을 염두에 두고 설계되었다고 합니다.
때문에 동적 로딩은 필수적일 수 밖에 없었다고 하는데요. 예를 들어, 웹 브라우저에서 애플릿(플러그인의 일종)을 실행할 때 필요한 클래스를 서버로부터 다운받아 실행하는 것이 가능해야 했습니다.
확장 가능성을 위함
또한, Java는 플러그인, JDBC 드라이버와 같은 확장 가능한 애플리케이션을 염두에 두고 설계되었다고 합니다.
이러한 시스템에서는 런타임에 새로운 모듈이나 드라이버를 쉽게 추가할 수 있어야하므로 동적 클래스 로딩이 매우 유용합니다.
만일 동적 로딩을 하지 않는다면, 플러그인이나 드라이버 추가시 애플리케이션 코드를 다시 수정하고 컴파일해야 하며, 동적 로딩은 이러한 과정 없이 런타임에 추가적인 소프트웨어 구성 요소들을 설치할 수 있게 해줍니다.
질문 #3: 각 클래스 로더들의 분류 기준
3.1. 부트스트랩 클래스 로더
여기서 로드하는 클래스들은 자바의 기본적으로 제공하는 API 등과 같은 표준 JDK 클래스들을 로드합니다.
예를들어 java.lang.Object는 자바의 기본 클래스로 자바의 모든 클래스 계층 구조의 최상위에 위치하는 루트 클래스입니다.
조금 더 세부적인 내용은 다음과 같으며 자바 8버전과 그 이후의 버전을 기준으로 그 내용이 살짝 다릅니다.
Java 8
Bootstrap 클래스 로더는
jre/lib/rt.jar와$JAVA_HOME/jre/lib에 있는 코어 라이블러리들을 포함한 JDK의 내부 클래스들을 로딩한다.
Java 9
rt.jar가 사라지면서 안에 있던 내용들이 모듈화 되어jre/lib폴더 안에 저장된다. Bootstrap ClassLoader가 로딩할 수 있던 클래스의 범위가 줄어들었다.
3.2. 확장 클래스 로더
확장 클래스 로더는 주로 JDK의 확장 디렉토리에 있는 클래스를 로드하는 데 사용되며, 주로 보안 확장 기능의 클래스들이 많이 들어간다고 하네요.
조금 더 세부적인 내용은 다음과 같으며 자바 8버전과 그 이후의 버전을 기준으로 그 내용이 살짝 다릅니다.
Java 8
jre/lib/ext폴더나java.ext.dirs환경 변수로 지정된 폴더에 있는 클래스 파일 로딩한다.
Java 9
이름이 Platform ClassLoader로 변경되었으며, 더이상
java.ext.dirs와lib/ext를 지원 하지 않는다. Extension 클래스들을 사용하길 원한다면 class path에 JAR파일들을 놔야한다.
3.3. 어플리케이션 클래스 로더
어플리케이션 클래스 로더는 외부 라이브러리나, 개발자가 작성한 코드(혹은 클래스, 자바는 기본적으로 클래스 단위로 코드가 작성되고 저장됩니다.)를 로드하는데 사용됩니다.
질문 #4: JVM 기반 어플리케이션 최적화
JVM 기반 어플리케이션은 크게 자바 객체에 대해 발생하는 직렬화/역직렬화 과정 최적화와 가비지 컬렉션 최적화로 나눌 수 있겠습니다.
4.1. 직렬화/역직렬화 최적화
직렬화/역직렬화 과정은 객체가 파일로 저장되거나, 네트워크 환경으로 전송될 때 주로 일어나게 됩니다.
이 과정은 CPU와 메모리 사용량에 영향을 미치는데요.
특히, 자바의 기본 직렬화는 느리고 비효율적입니다. 자바의 기본 직렬화는 클래스의 메타데이터를 포함하여 큰 직렬화 결과물을 생성하며, 이는 네트워크 전송 및 저장 시 불필요한 오버헤드를 발생시킵니다.
또한, 역직렬화 과정에서도 마찬가지로 시간이 걸리겠죠.
때문에, 이러한 직렬화와 역직렬화를 최적화하는 방안들을 고민해봐야할 것입니다.
4.1.1. Java “Externalizable” 인터페이스 사용
자바의 기본 직렬화를 사용할 경우, Serializable 대신 Externalizable 인터페이스를 구현하여 성능을 개선할 수 있습니다. Externalizable 은 객체의 어떤 필드를 직렬화할지 개발자가 직접 제어할 수 있어 불필요한 데이터 직렬화를 방지할 수 있습니다.
4.1.2. Kryo 직렬화 사용
Kryo 직렬화는 자바 기본 직렬화보다 훨씬 뻐르고 효율적입니다.
Kryo는 더 작은 크기의 직렬화된 데이터를 생성하며, 특히 대규모 데이터셋을 다룰 때 성능 향상을 제공합니다.
Spark와 같은 시스템에서는 기본적으로 자바 직렬화를 사용하지만, 성능 최적화를 위해 Kryo 직렬화를 사용하는 것이 권장됩니다.
Kryo는 자바 직렬화보다 최대 10배 빠를 수 있으며, 더 작은 메모리 공간을 차지합니다.
// Spark에서 Kryo 직렬화를 활성화하는 예시
val conf = new SparkConf().set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val spark = new SparkContext(conf)
// 사용자 정의 클래스 등록
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))4.2. 가비지 컬렉션 튜닝
먼저, Java의 가비지 컬렉션에 대한 자세한 설명은 https://velog.io/@jy016011/Java-JVM-%EC%8B%A4%ED%96%89-%EC%97%94%EC%A7%84%EA%B0%80%EB%B9%84%EC%A7%80-%EC%BB%AC%EB%A0%89%EC%85%98-%EC%9C%84%EC%A3%BC%EB%A1%9C 를 참조해주세요
4.2.1. GC 로그 분석
먼저, GC 로그를 분석하여 어떤 방면으로 최적화를 하면 좋을지 탐색하는게 우선일 것 같습니다.
JVM 위에서 동작하는 Apache Spark를 예시로 들겠습니다.
Spark에서는 다음과 같은 옵션을 통해 GC 로그를 활성화할 수 있다네요
spark.executor.extraJavaOptions="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"이 옵션은 각 작업자 노드에서 GC가 발생할 때마다 로그를 기록하게 합니다.
이를 통해 Minor GC와 Major GC의 빈도와 소요시간을 확인할 수 있습니다.
4.2.2. 세대별 객체 관리
JVM의 힙 메모리 공간은 Young 세대와 Old 세대로 객체를 나누어 관리합니다.
- Young 세대
- Minor GC가 너무 자주 발생하면 Eden 영역이 너무 작을 수 있습니다.
- 따라서 Eden 영역을 늘려 Minor GC의 빈도를 줄일 수 있겠습니다.
- Old 세대
- Old 세대 영역의 메모리가 가득 차서 Major GC가 자주 발생하면 성능이 크게 저하될 것입니다.
- 이 경우
spark.memory.fraction값을 줄여서 캐싱에 사용되는 메모리를 줄이고, Old 세대에 더 많은 메모리를 할당할 수 있습니다.
4.2.3. 적절한 GC 알고리즘 선택
Java는 많은 GC 알고리즘을 선택하며, 사용하는 어플리케이션에 맞는 알고리즘을 선택하면 되겠습니다.
대규모 데이터 처리 시스템인 Spark의 경우에는 “G1 GC”, “ZGC”, “Shenandoah GC”와 같은 짧은 지연 시간과 높은 처리량을 제공하는 GC 알고리즘이 많이 사용된다고 하니다.
4.2.4. RDD 캐싱 관리
Spark에서는 RDD를 캐싱할 때, 캐싱된 데이터가 너무 많을 경우 Old 세대를 차지하여 Full GC가 자주 발생할 수 있다네요.
때문에, 불필요한 RDD는 명시적으로 해제하고, 필요한 경우에만 데이터를 캐싱하는 것이 중요하다고 합니다.
참조
https://inpa.tistory.com/entry/JAVA-☕-JVM-내부-구조-메모리-영역-심화편#런타임_데이터_영역_runtime_data_area
https://velog.io/@ddangle/Java-클래스-로더란
https://steady-coding.tistory.com/593
https://medium.com/@gsy4568/jvm의-첫관문-classloader-ecdf93d53a7b
수정이력
- 2024.11.12, 댓글 질문에 대한 답변 내용 추가

9개의 댓글

잘 읽었습니다 :)
지연 로딩방식이 JVM의 사용하는 경우 특수한 동적로딩인 만큼 단점은 뭔지, 다른 언어에서는 사용하지 않는 이유가 있는지 궁금합니다.

포스트 글 잘 읽었습니다.
각 클래스 로더들이 가져오는 클래스 파일들이 어떻게 구별되기에 따로 로더들을 분류했는지 궁금하네요.

포스팅 잘 읽었습니다. 자바 객체를 관리하려면 결국 직렬과/역직렬화 과정과 GC를 피할 수 없다고 알고 있는데, JVM을 기반으로 하는 여러 애플리케이션이 이런 단점을 어떻게 보완하고 성능을 높이는지 궁금해요!
좋은 글 감사합니다!
상속과 오버로딩을 구현하고 이를 실행했을 때 Python과 Java의 런타임에서의 실행 순서 차이가 궁금합니다! 그리고 이렇게 개발 시 고려해야할 또다른 차이점들이 있는지 궁금합니다.