
통계학
- 티어 : Silver 3
- 시간 제한 : 2 초
- 메모리 제한 : 256 MB
- 알고리즘 분류 : 수학, 구현, 정렬
문제
수를 처리하는 것은 통계학에서 상당히 중요한 일이다. 통계학에서 N개의 수를 대표하는 기본 통계값에는 다음과 같은 것들이 있다. 단, N은 홀수라고 가정하자.
1. 산술평균 : N개의 수들의 합을 N으로 나눈 값
2. 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
3. 최빈값 : N개의 수들 중 가장 많이 나타나는 값
4. 범위 : N개의 수들 중 최댓값과 최솟값의 차이N개의 수가 주어졌을 때, 네 가지 기본 통계값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 단, N은 홀수이다. 그 다음 N개의 줄에는 정수들이 주어진다. 입력되는 정수의 절댓값은 4,000을 넘지 않는다.
출력
첫째 줄에는 산술평균을 출력한다. 소수점 이하 첫째 자리에서 반올림한 값을 출력한다.
둘째 줄에는 중앙값을 출력한다.
셋째 줄에는 최빈값을 출력한다. 여러 개 있을 때에는 최빈값 중 두 번째로 작은 값을 출력한다.
넷째 줄에는 범위를 출력한다.
예제 입출력
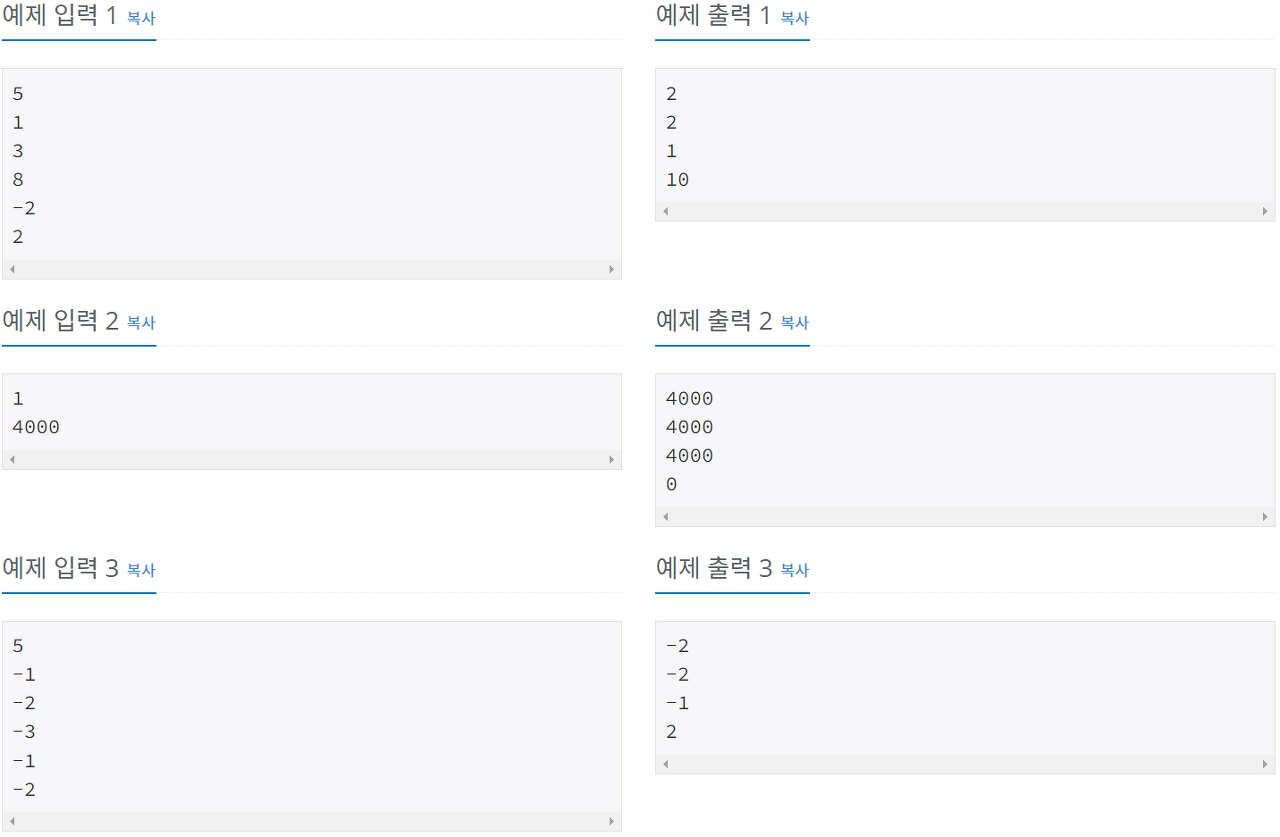
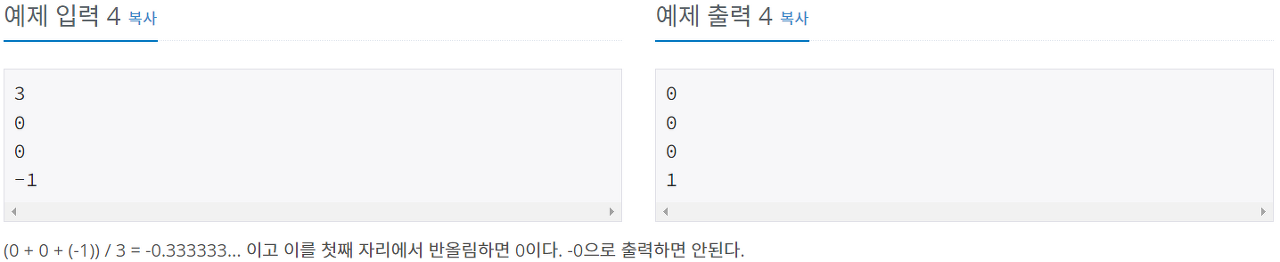
Algorithm
1. 각 숫자를 리스트에 저장
-> 음수값 나오는지 확인
2. 산술평균 = floor(sum(리스트) /N)
3. 중앙값 = 리스트 오름차순 정렬 후 list[N/2]
4. 최빈값 = 각 숫자들을 입력받을 때 Dictionary에 등장횟수와 함께 저장하고 value가 가장 큰 key를 출력
5. 범위 = 리스트[-1] - 리스트[0]시간 초과
☞ 입력 시 readline()으로 입력받아 해결
Code
import sys
input = sys.stdin.readline
# 입력
N = int(input())
nums = []
nums_dict = {}
for _ in range(N):
num = int(input())
nums.append(num)
if num not in nums_dict:
nums_dict[num] = 1
else:
nums_dict[num] += 1
# 산술평균
print(round(sum(nums)/N))
# 중앙값
nums.sort()
print(nums[N//2])
# 최빈값
max_ = max(nums_dict.values()) # 최대 등장 횟수 찾기
temp = []
for key, value in nums_dict.items():
if value == max_: # value가 최대 등장 횟수와 같은 숫자 따로 빼두기
temp.append(key)
# 최빈 값이 여러 개 인 경우
if len(temp) != 1:
# 정렬 후 두 번째로 작은 값 출력
temp.sort()
print(temp[1])
else:
print(temp[0])
# 범위
print(nums[-1] - nums[0])메모리: 51480 KB
시간: 552 ms

안녕하세요 : )