
들어가며
LMS 서비스를 운영하던 중 한 가지 문제를 발견했다. 동일한 사용자가 같은 과제에 대해 "제출" 버튼을 빠르게 두 번 누르면, 과제가 두 번 저장되는 현상이 생기는 것이다. 코드를 들여다보니 원인은 단순했다.
@Transactional
public SubmissionResponse submitAssignment(...) {
// 중복 체크
validationUtils.validateDuplicateSubmission(userId, planId);
// 저장
submissionRepository.save(submission);
}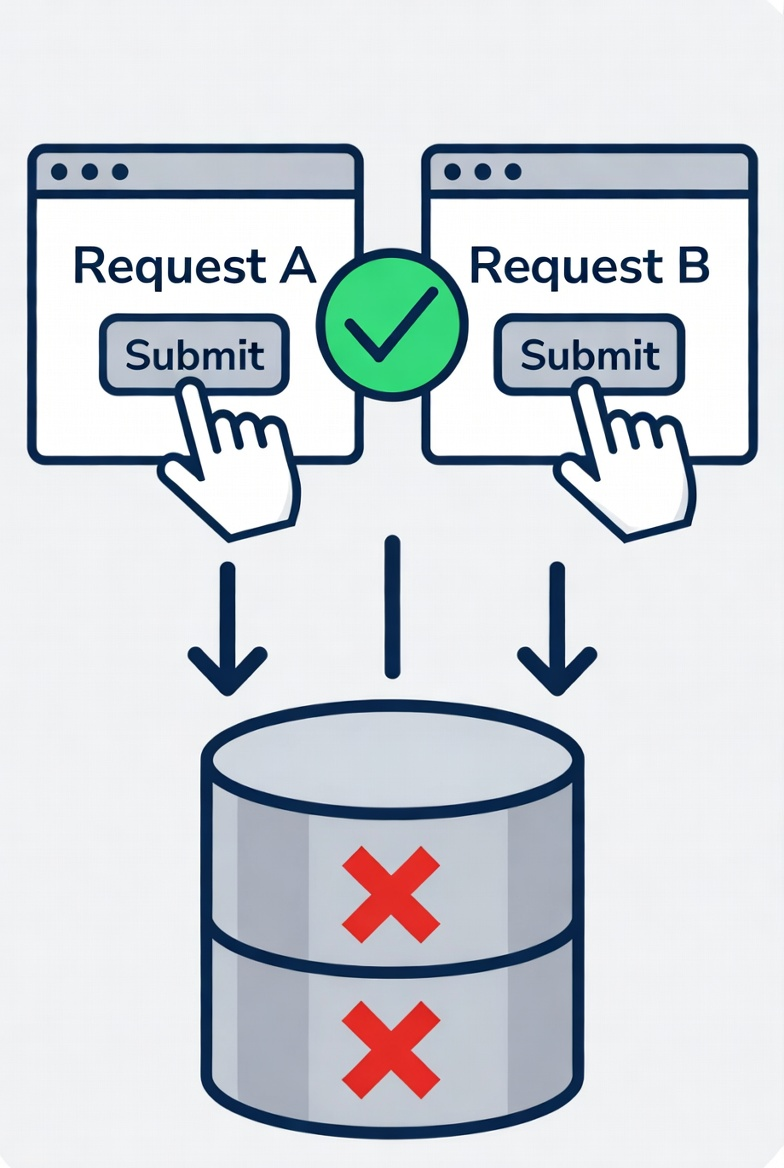
중복 체크를 통과한 뒤 저장하는 구조 자체는 자연스럽다. 문제는 요청 A와 B가 거의 동시에 들어올 때다. 둘 다 1번을 통과한 뒤 둘 다 2번을 실행한다.
전형적인 race condition이다.
이 글에서는 이 문제를 JPA의 비관적 락으로 해결하는 과정을 정리하고, 같은 종류의 문제를 이전에 Redis 분산 락으로 해결했던 경험과 비교해 두 방식이 언제 어떻게 다른지 분석해본다.
1. Race Condition이란?
경쟁 상태(Race Condition) 란 여러 요청(또는 스레드, 프로세스)이 공유 자원에 거의 동시에 접근할 때, 실행 순서에 따라 결과가 달라지는 현상을 말한다. 이름 그대로 "누가 먼저 도착하느냐의 경주(race)"가 프로그램의 정확성을 좌우하게 되는 상황이다.
핵심은 "검사와 실행 사이의 틈"
race condition이 발생하는 전형적인 패턴은 Check-Then-Act다. 어떤 조건을 검사한 뒤(Check) 그 결과를 바탕으로 동작하는(Act) 구조에서, 검사와 동작 사이에 다른 요청이 끼어들면 검사 결과가 무효가 된다.
과제 제출 코드로 돌아가보자.
validationUtils.validateDuplicateSubmission(userId, planId); // Check
submissionRepository.save(submission); // Act요청 하나만 있을 때는 아무 문제가 없다. 이미 제출한 사용자가 다시 요청하면 Check 단계에서 예외가 터지고, 처음 제출하는 사용자는 Check를 통과해 Act로 넘어간다.
그런데 요청 A와 B가 거의 동시에 들어오면 이야기가 달라진다. A가 Check를 통과하는 순간, 아직 A의 Act(INSERT)는 실행되기 전이다. 바로 그 찰나에 B도 Check를 실행하면 B 역시 "제출 기록이 없다"는 결과를 받게 된다. 그 뒤 A와 B가 각자의 Act를 실행하면 두 건의 INSERT가 모두 성공한다. 두 요청 모두 자기 기준에서는 올바르게 동작했지만, 결과적으로는 중복 row가 생긴다. 이것이 전형적인 race condition이다.
왜 코드만 봐서는 안 보이는가
race condition의 위험한 점은 단일 스레드로 코드를 읽으면 버그가 전혀 보이지 않는다는 것이다. 위 두 줄은 누가 봐도 "제출 여부를 확인하고 저장한다"는 올바른 로직이다. 문제는 이 두 줄이 원자적으로 실행되지 않는다는 점인데, 이는 코드의 문법이 아니라 실행 모델의 특성이다.
그래서 race condition은 테스트로도 잘 잡히지 않는다. 단위 테스트는 보통 한 스레드로 순차 실행하므로 틈이 생기지 않는다. 실제 운영 환경에서 트래픽이 몰릴 때만 드물게 재현되고, 재현이 어려우니 원인 파악도 까다롭다.
해결의 방향
race condition을 없애는 방법은 크게 세 가지다.
- 공유 자원 자체를 없앤다 — 각 요청이 독립된 자원을 쓰도록 설계를 바꾼다. 가능하면 가장 깔끔하지만, 중복 제출처럼 본질적으로 공유될 수밖에 없는 자원에는 적용할 수 없다.
- 원자적 연산으로 만든다 — Check와 Act를 DB 제약조건(unique index)으로 합치거나,
INSERT ... ON DUPLICATE KEY같은 원자적 구문을 사용한다. 단순한 경우에 효과적이다. - 검사-실행 구간을 직렬화한다 — Check-Then-Act 구간을 한 번에 한 요청만 들어갈 수 있도록 락으로 감싼다. 비관적 락이 바로 이 방식이다.
이 글에서 다루는 비관적 락은 세 번째 접근이다. "검사와 실행 사이의 틈"을 락으로 메워서, 한 요청이 Check와 Act를 끝낼 때까지 다른 요청이 아예 들어오지 못하게 막는다.
2. 비관적 락이란
낙관적 락과의 대비
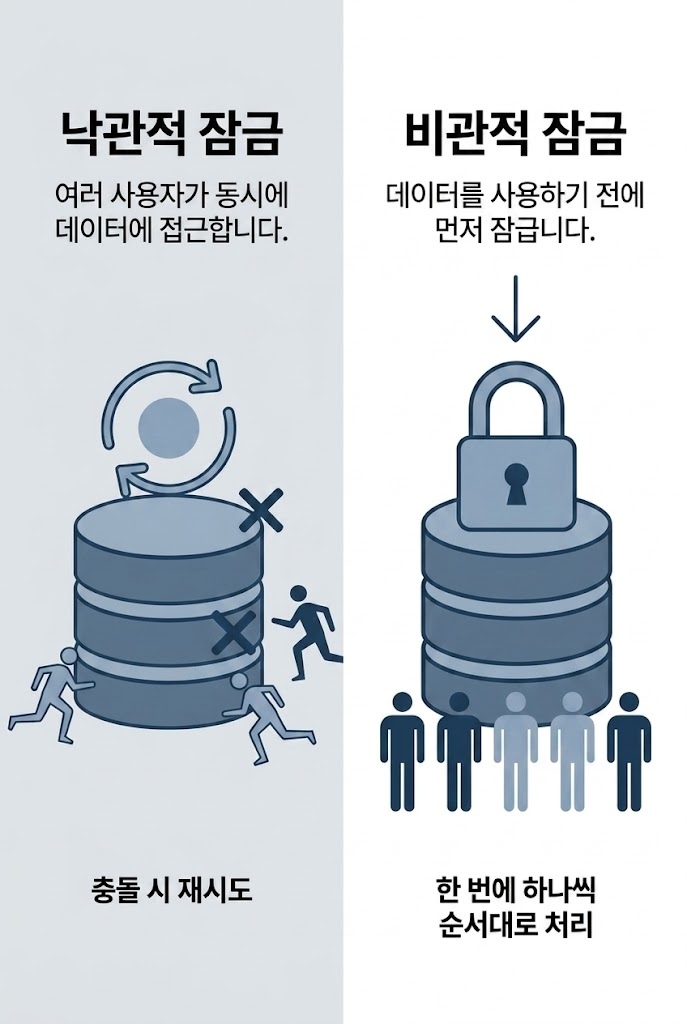
동시성 제어는 크게 두 가지 철학으로 나뉜다.
-
낙관적 락(Optimistic Lock): "충돌은 거의 일어나지 않을 것"이라 가정한다. 일단 작업을 진행하고, 커밋 시점에 version 컬럼을 비교해 충돌을 감지한다. 충돌 시 예외를 던지거나 재시도한다.
-
비관적 락(Pessimistic Lock): "충돌이 반드시 일어날 것"이라 가정한다. 데이터를 읽는 순간부터 다른 트랜잭션의 접근을 아예 차단한다.
비관적 락은 물리적으로 동시 접근을 직렬화한다. 줄을 서서 한 명씩 들어가는 것과 같다.
언제 비관적 락을 쓰는가
- 충돌 빈도가 높아서 낙관적 락의 재시도 비용이 커지는 경우
- 중복 제출, 재고 차감, 좌석 예약처럼 "두 번 통과하면 안 되는 불변식" 이 있는 경우
- 짧은 임계구역에서 강한 일관성이 필요할 때
비관적 락의 비용
공짜가 아니다. 락을 잡고 있는 동안 다른 요청은 대기해야 하므로 처리량이 떨어지고, 잘못 설계하면 데드락이 생기며, DB 커넥션을 오래 붙잡고 있어 커넥션 풀을 고갈시킬 수 있다. 그래서 락 점유 시간을 최대한 짧게 유지하는 것이 핵심 원칙이다.
2. JPA 비관적 락으로 해결하기
코드 변경 — Repository
먼저 Plan을 락과 함께 조회하는 메서드를 추가한다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Plan p WHERE p.planId = :planId")
Optional<Plan> findByIdWithPessimisticLock(@Param("planId") Long planId);@Lock(LockModeType.PESSIMISTIC_WRITE)는 하이버네이트에게 "이 쿼리를 실행할 때 SQL에 FOR UPDATE를 붙여라"라고 지시한다. 결과적으로 실제 DB에 나가는 SQL은 다음과 같다.
SELECT * FROM plan WHERE plan_id = ? FOR UPDATEFOR UPDATE가 붙은 순간 해당 Plan row에는 배타 락이 걸린다. 같은 row를 FOR UPDATE로 읽으려는 다른 트랜잭션은 현재 트랜잭션이 커밋되거나 롤백될 때까지 DB 레벨에서 대기한다.
JPA의 락 모드는 세 가지가 있다.
PESSIMISTIC_READ:SELECT ... FOR SHARE— 읽기는 공유하지만 쓰기는 차단PESSIMISTIC_WRITE:SELECT ... FOR UPDATE— 읽기/쓰기 모두 차단PESSIMISTIC_FORCE_INCREMENT: 위에 더해 version 컬럼을 강제로 증가
중복 제출 방지에는 배타적 접근이 필요하므로 PESSIMISTIC_WRITE가 적절하다.
코드 변경 — Service
서비스 메서드에서 락 획득을 중복 체크보다 앞에 배치한다.
@Transactional
public SubmissionResponse submitAssignment(Long groupId, Long planId, ...) {
User user = validationUtils.validateMenteeAccess(groupId, studentNumber);
Plan plan = validationUtils.validatePlan(planId);
// Plan 행에 비관적 락 획득 - 동시 제출 요청을 직렬화하여 중복 제출 race condition 방지
planRepository.findByIdWithPessimisticLock(planId)
.orElseThrow(() -> new RestApiException(ErrorCode.PLAN_NOT_FOUND));
// 과제 제출 중복 여부 체크
validationUtils.validateDuplicateSubmission(user.getUserId(), planId);
// 저장
AssignmentSubmission submission = ...;
return SubmissionResponse.from(submissionRepository.save(submission));
}이 코드에서 주목해야 할 점이 세 가지 있다.
(1) 락으로 가져온 Plan을 변수에 받지 않는다
findByIdWithPessimisticLock의 반환값을 변수에 담지 않고 .orElseThrow만 호출한 뒤 버린다. 이것은 의도적인 설계다. 이 쿼리의 목적은 Plan의 필드를 읽는 것이 아니라 FOR UPDATE로 락을 거는 부수효과이기 때문이다. Plan의 실제 데이터는 이미 앞 줄의 validatePlan이 가져왔다. 비관적 락 패턴을 처음 보면 어색하게 느껴지는데, "SELECT가 목적이 아니라 락이 목적"이라는 관점에서 보면 자연스럽다.
(2) 왜 Plan에 락을 거는가
중복이 생기는 단위는 "같은 Plan + 같은 User"다. 그런데 락을 AssignmentSubmission에 걸 수는 없다. 아직 존재하지 않는 row이기 때문이다(지금 막 INSERT 하려는 중). 그래서 이미 존재하는 부모 엔티티인 Plan row를 락의 게이트키퍼로 사용한다. 이는 비관적 락 설계의 자주 쓰이는 패턴이다. "새로 만들 자식이 충돌할 수 있다면, 공통된 부모 row를 잠근다."
(3) 순서가 곧 의미다
락 획득 → 중복 체크 → save. 이 순서가 뒤집히면 락의 의미가 사라진다. 만약 중복 체크를 먼저 하면 그건 락 잡기 전의 상태를 읽은 것이라 의미가 없다. 락을 먼저 잡아야 "이 시점 이후로 같은 Plan에 접근하는 모든 요청이 내 뒤에 줄 선다"가 보장되고, 그때부터 하는 중복 체크만 신뢰할 수 있다.
동시 요청 시 실제 흐름
요청 A와 B가 거의 동시에 들어온다고 하자.
- A가
findByIdWithPessimisticLock(planId)호출 → Plan row 락 획득 - B가 같은 메서드 호출 → A의 락 때문에 DB 내부에서 대기
- A가 중복 체크 통과 → save → 트랜잭션 커밋 → 락 해제
- B의 SELECT가 그제서야 풀림 → B는 A가 커밋한 데이터까지 본다 → 중복 체크에서 탈락 → 예외
FOR UPDATE는 MVCC 환경에서도 스냅샷이 아닌 최신 커밋 상태를 읽도록 강제하므로, B는 A의 결과를 반드시 본다. 이것이 비관적 락이 만드는 직렬화의 본질이다.
락 해제를 신경 쓰지 않아도 되는 이유
위 코드 어디에도 unlock() 같은 호출이 없다. @Transactional 메서드가 끝나면 정상 커밋이든 예외 롤백이든 DB가 트랜잭션을 종료하면서 잡고 있던 모든 락을 함께 해제한다. 즉 락의 생명주기 = 트랜잭션의 생명주기다. 개발자는 락 해제를 신경 쓸 필요가 없고, 중간에 예외가 터져도 락이 남지 않는다. 이 점은 뒤에서 볼 Redis 분산 락과 가장 크게 대비되는 지점이다.
3. 이중 방어선 — 집계 쿼리도 함께 수정한다
락이 완벽하게 동작해도 과거 데이터에 이미 중복이 쌓여 있을 수 있다. 락은 지금 이후의 중복만 막기 때문이다. 그래서 통계 API도 함께 손봐야 한다.
// Before: 단순 COUNT - 중복 제출이 있으면 한 사람이 여러 번 카운트됨
int submittedCount = submissionRepository
.countByPlanPlanIdAndStatus(planId, SUBMITTED);
// After: 고유 제출자 수 - 설령 중복이 섞여 있어도 인원 수로 환산됨
int submittedCount = submissionRepository
.countDistinctSubmittersByPlanIdAndStatus(planId, SUBMITTED);실제 쿼리는 다음과 같다.
@Query("SELECT COUNT(DISTINCT a.submitter.userId) FROM AssignmentSubmission a " +
"WHERE a.plan.planId = :planId AND a.status = :status")
int countDistinctSubmittersByPlanIdAndStatus(
@Param("planId") Long planId,
@Param("status") SubmissionStatus status);COUNT(*)을 COUNT(DISTINCT submitter_id)로 바꾸면 row 수가 아니라 사람 수를 센다는 불변식이 생긴다. 한 사람이 두 번 제출했더라도 통계에서는 한 명으로 카운트된다.
미제출자 계산도 함께 정비했다.
@Query("SELECT COUNT(DISTINCT a.submitter.userId) FROM AssignmentSubmission a " +
"WHERE a.plan.planId = :planId " +
"AND a.submitter.userId IN (" +
" SELECT gm.user.userId FROM GroupMember gm " +
" WHERE gm.studyGroup.studyId = :groupId " +
" AND gm.role = com.mjsec.lms.studygroup.domain.type.GroupMemberRole.MENTEE" +
")")
int countDistinctMenteeSubmittersByPlanIdAndGroupId(...);notSubmittedCount = totalMentees - submittedMentees로 계산할 때, 제출자 쪽이 "현재 그룹에 속한 멘티"로 한정되지 않으면 탈퇴한 사용자나 역할이 바뀐 사용자 때문에 미제출자 수가 음수로 나올 수도 있다. 그래서 분모(totalMentees)와 분자(submittedMentees)의 기준을 "현재 이 그룹의 멘티" 로 일치시킨 것이다.
정리하면 두 개의 방어선을 깔았다.
- 락: 앞으로 들어올 요청에서 중복이 생기는 것을 차단 (미래 방어)
- 집계 쿼리: 이미 쌓였을 수도 있는 중복이 통계를 왜곡하지 않도록 흡수 (과거 방어)
시간축 양방향으로 방어선을 친 셈이다.
4. 테스트로 못 박은 계약
락을 적용할 때는 테스트로 불변식을 명시해두는 것이 중요하다. 코드만 보고는 "락 획득 → 중복 체크" 순서가 왜 중요한지 알기 어려워서, 리팩토링 중에 순서가 뒤집히는 실수가 일어나기 쉽기 때문이다.
순서 보장 — InOrder 검증
@Test
@DisplayName("비관적 락 획득이 반드시 중복 체크보다 먼저 수행된다")
void lock_acquired_before_duplicate_check() {
// ... stubbing ...
service.submitAssignment(GROUP_ID, PLAN_ID, STUDENT_NUMBER, dto, IP_ADDRESS);
InOrder inOrder = inOrder(planRepository, validationUtils);
inOrder.verify(planRepository).findByIdWithPessimisticLock(PLAN_ID);
inOrder.verify(validationUtils).validateDuplicateSubmission(USER_ID, PLAN_ID);
}Mockito의 InOrder는 "A가 B보다 먼저 호출되었는가"를 검증한다. 이 테스트가 있으면 나중에 누가 코드를 리팩토링하다가 순서를 바꿔도 CI가 막아준다. 일종의 가드레일이다.
실패 전파 — never() 검증
@Test
@DisplayName("락 획득 실패 시 중복 체크와 저장이 수행되지 않는다")
void no_duplicate_check_or_save_when_lock_fails() {
when(planRepository.findByIdWithPessimisticLock(PLAN_ID))
.thenReturn(Optional.empty());
assertThatThrownBy(() -> service.submitAssignment(...))
.isInstanceOf(RestApiException.class);
verify(validationUtils, never()).validateDuplicateSubmission(anyLong(), anyLong());
verify(submissionRepository, never()).save(any());
}락 획득 단계에서 Plan을 못 찾으면 뒤의 중복 체크와 save가 절대 호출되지 않아야 한다. 트랜잭션 롤백이 어차피 부작용을 되돌리기는 하지만, 서비스 레이어에서 부작용 있는 메서드가 호출되는 것 자체를 막는 더 엄격한 계약이다.
단위 테스트의 한계
이 단위 테스트들은 @Mock으로 Repository를 모킹하므로 실제 DB 락이 걸리는지까지는 검증하지 못한다. "서비스 레이어에서 락 메서드를 올바른 순서로 호출하는가"까지만 확인한다. 실제 락이 DB 수준에서 동작하는지는 별도의 동시성 통합 테스트(AssignmentSubmissionConcurrencyTest)에서 CountDownLatch와 ExecutorService로 5개 요청을 동시에 던져 1개만 성공하는지 검증한다.
단위 테스트는 "계약"을, 동시성 테스트는 "실측"을 담당하는 역할 분담이다.
5. Redis 분산 락과의 비교
예전에 CTF 플랫폼에서는 같은 종류의 중복 제출 문제를 Redis 분산 락으로 해결했다. 두 방식을 비교해보면 비관적 락의 성격이 더 선명해진다.
Redis 분산 락은 보통 Redisson의 RLock 같은 라이브러리로 구현한다. 원리는 SET key value NX PX ttl 같은 원자적 명령으로 "키 선점 = 락 획득"을 구현하고, 여기에 pub/sub 기반 대기, 재진입, watchdog 자동 연장을 얹는 방식이다.
차이점 (1) — 락의 위치와 범위
- JPA 비관적 락: DB row에 직접 건다. 락 대상이 "DB에 존재하는 실제 데이터"여야 한다.
- Redis 분산 락: Redis의 논리적 key에 건다. 락 대상을 자유롭게 정의할 수 있어 DB row가 존재하지 않는 작업(외부 API 호출, 파일 처리 등)에도 락을 걸 수 있다.
차이점 (2) — 트랜잭션과의 결합
- JPA 비관적 락: 트랜잭션에 묶여 있어 자동 해제된다. 락과 데이터 변경이 원자적이다.
- Redis 분산 락: 트랜잭션과 분리되어 있다. 수동으로
unlock()해야 하고finally블록이 필수다. 더 까다로운 문제는 AOP 순서다. 락을@Transactional안에서 얻으면 트랜잭션 커밋 전에 락이 풀릴 수 있어, 다음 요청이 아직 커밋되지 않은 상태를 보고 중복 체크를 통과해버릴 수 있다. 그래서 락은 반드시 트랜잭션 바깥에서 감싸야 한다.
차이점 (3) — DB 부하와 확장성
- JPA 비관적 락: DB 커넥션을 락 동안 점유한다. 트래픽이 늘면 커넥션 풀이 고갈될 수 있다. DB가 병목이 된다.
- Redis 분산 락: DB 커넥션은 실제 쿼리 시점에만 사용한다. Redis가 대기열을 흡수하므로 DB 부하가 분산된다. 여러 서비스 / 여러 DB를 넘나드는 MSA 환경에도 적합하다. 대신 Redis 자체의 HA 구성(Redlock 알고리즘, split-brain 문제)이라는 새로운 복잡도가 생긴다.
차이점 (4) — 장애 상황
- JPA 비관적 락: 락 보유 중 애플리케이션이 죽으면 DB 연결이 끊기면서 트랜잭션이 롤백되고 락이 자동 해제된다. 안전하다.
- Redis 분산 락: 애플리케이션이 죽으면 TTL로만 해제된다. TTL이 너무 짧으면 작업 중에 락이 만료되고, 너무 길면 복구가 지연된다. Redisson의 watchdog가 이 문제를 완화하지만 완전히 없애지는 못한다.
차이점 (5) — 운영 복잡도
- JPA 비관적 락: 어노테이션 한 줄. 학습 비용이 낮다.
- Redis 분산 락: 인프라 추가, AOP 순서, TTL 설계, 장애 처리를 모두 고려해야 한다.
6. 그래서 어느 쪽을 언제 쓰는가
두 방식은 우열이 있는 게 아니라 적합한 맥락이 다르다. 판단 기준은 다음 세 가지 정도다.
충돌의 규모와 빈도
- 충돌이 드물고(한 사용자의 더블 클릭 수준) 락 경쟁이 작다면 JPA 비관적 락으로 충분하다. DB 부하가 미미하다.
- 충돌이 극심하다면(수백 명이 동일 리소스에 몰림) DB 락은 커넥션 풀을 금방 고갈시킨다. Redis로 대기열을 흡수해야 한다.
트랜잭션의 길이
- 임계구역의 트랜잭션이 짧으면 JPA 락의 점유 시간이 짧아 무리 없다.
- 트랜잭션이 길면(외부 API 호출, 파일 처리 등이 섞이면) 그 시간만큼 DB 락을 잡고 있게 되어 처리량이 급격히 떨어진다. 이때는 Redis가 유리하다.
분산 환경의 복잡도
- 단일 DB를 공유하는 모놀리스나 단순한 환경에서는 JPA 비관적 락이 가장 단순하고 안전하다.
- MSA로 여러 DB를 넘나드는 상황에서는 애초에 DB 락이 의미가 없으므로 Redis 분산 락이 사실상 유일한 선택지다.
LMS의 과제 제출은 한 사용자가 자신의 과제를 두 번 클릭하는 수준의 충돌이다. 충돌 범위가 매우 좁고(사용자별 Plan 단위) 빈도도 낮다.
반면 CTF 플랫폼은 동일 문제에 수백 명이 동시에 플래그를 제출한다. 충돌이 극심하고 DB 락을 잡으면 커넥션 풀이 터진다. 같은 팀이 두 프로젝트에서 서로 다른 선택을 한 이유가 여기에 있다.
마치며
비관적 락은 개념 자체는 단순하지만, 실제로 적용할 때는 세심하게 고려해야 할 지점이 많다. 락을 어느 엔티티에 걸 것인가, 락과 검증의 순서를 어떻게 할 것인가, 트랜잭션 범위와 어떻게 맞출 것인가, 기존에 쌓인 데이터는 어떻게 보정할 것인가, 그리고 그 계약을 테스트로 어떻게 못 박을 것인가.
락은 단순한 어노테이션 한 줄이지만, 그 한 줄이 제대로 동작하게 하려면 서비스 레이어의 호출 순서, 집계 쿼리의 재설계, 단위 테스트와 동시성 테스트의 역할 분담까지 모두 맞아떨어져야 한다.
Redis 분산 락이 더 "고급"인 것도, JPA 비관적 락이 더 "기본"인 것도 아니다. 해결하려는 문제의 규모, 트랜잭션의 성격, 인프라의 복잡도에 맞춰 가장 단순하게 작동하는 도구를 고르는 것이 가장 좋은 선택이다.
