1. 리소스 부족 대응 기술
1. 애플리케이션 튜닝 (Application Tuning)
- 동작 방식: 애플리케이션의 프로세스(쓰레드, 힙 크기 등)를 조정하여 성능을 향상함.
- 스케일링 예시: Pod(작은 프로세스) → Pod(큰 프로세스)
2. 수직적 확장 (Vertical Pod Autoscaler, VPA)
- 동작 방식: 컨테이너의 CPU, 메모리 리소스를 증가 또는 감소
- 스케일링 예시: Pod → Pod (리소스 증설)
- 특징: 애플리케이션의 문제 해결이 어렵거나 트래픽 증가 시 리소스 확장(CPU, RAM, 디스크 등) 필요
- 사용 예시: 기존 Pod의 리소스를 늘려 1 CPU 1GB RAM에서 2GB RAM으로 증설 가능
3. 수평적 확장 (Horizontal Pod Autoscaler, HPA)
- 동작 방식: Pod 수를 동적으로 조정하여 부하를 분산
- 스케일링 예시: Pod → 추가 Pod
- 특징: 부하 분산을 위해 앞단의 LB 서비스가 2개 이상의 Pod에 요청을 배분
4. 클러스터 오토스케일러 (Cluster Autoscaler, CAS)
- 동작 방식: Pod을 배포할 수 있는 Node를 추가하거나 제거
- 스케일링 예시: Node → 추가 Node
- 특징: Pod 레벨이 아닌 Node 레벨에서 동작하며, 스케줄링이 실패한 Pending Pod을 해결함.
2. 확장 방식 비교
2.1 수평 확장 (Horizontal Scaling)
-
동작 방식: 운영 환경에 더 많은 워크로드(VM, Task, Pod)를 추가하여 트래픽을 여러 워크로드에 분산하는 방식
-
특징:
- 확장성이 높고 유연함
- 비용 효율적
- Stateless 워크로드에 적합하며, 데이터 일관성 유지 필요성이 적음
- 즉각적인 부하 증가에 대응하기 용이함
2.2 수직 확장 (Vertical Scaling)
-
동작 방식: 기존 워크로드의 성능(CPU, Memory)을 향상하는 방식
-
특징:
- 하드웨어 확장에는 한계가 존재함
- 확장 과정에서 장애 위험이 존재할 수 있음
- 수평 확장보다 유연성이 부족함
- 대규모 애플리케이션의 단일 노드 운영이 필요한 경우 사용됨
3. Kubernetes Autoscaling 개요
3.1 주요 Autoscaler 종류
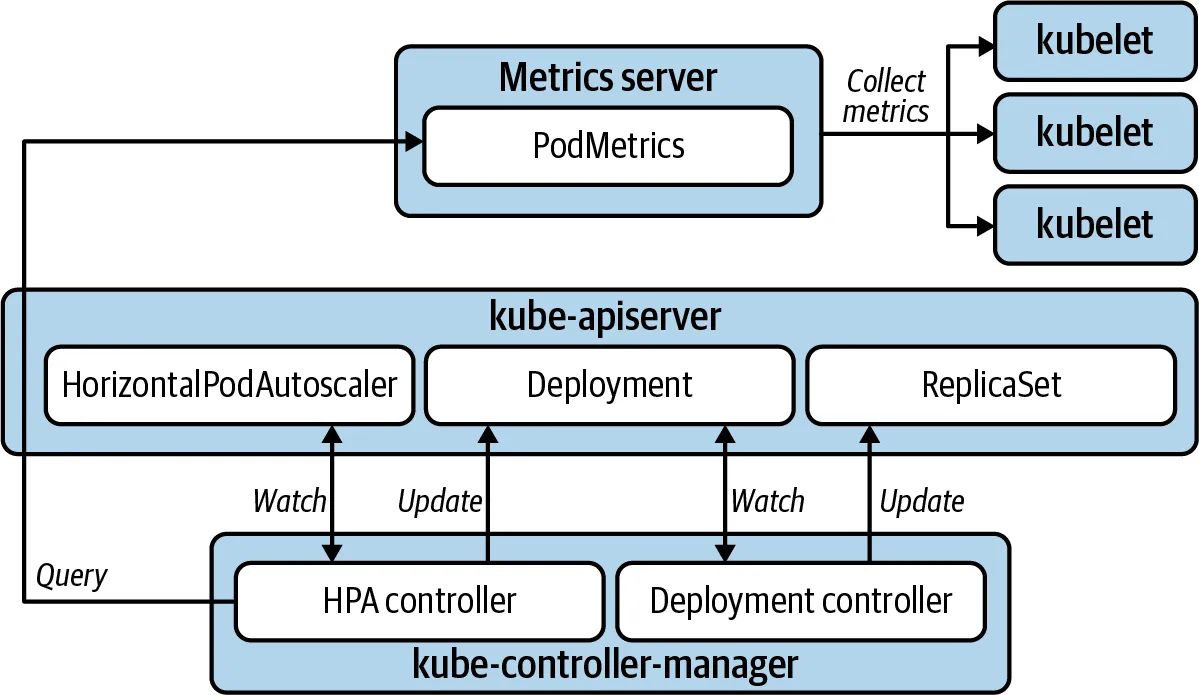
1. HPA (Horizontal Pod Autoscaler)
다수의 Pod을 추가하여 LB를 통해 부하를 분산
2. VPA (Vertical Pod Autoscaler)
기존 Pod의 리소스를 증가하여 처리 성능을 향상
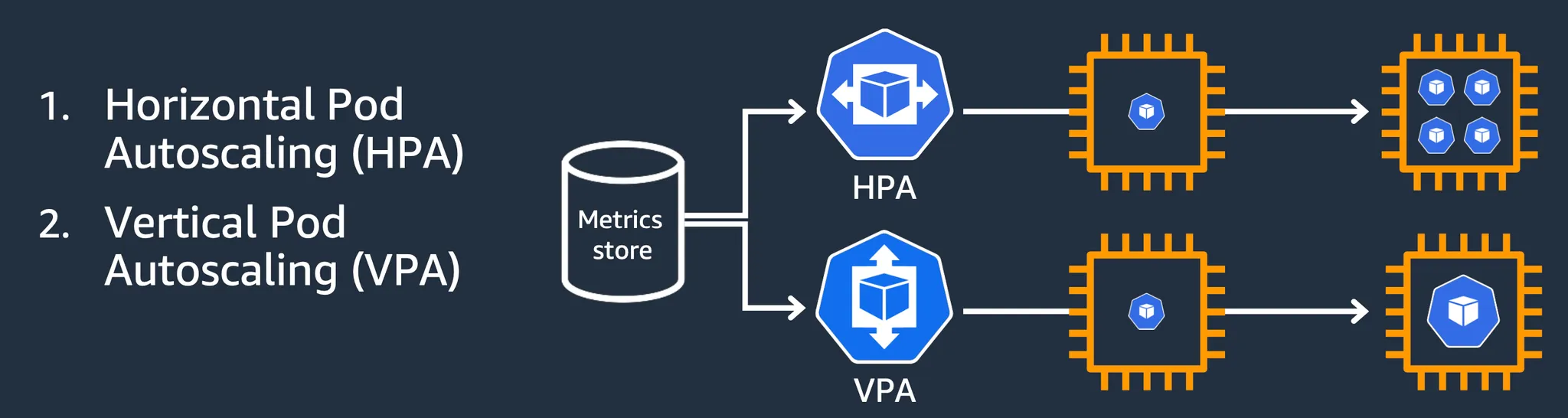
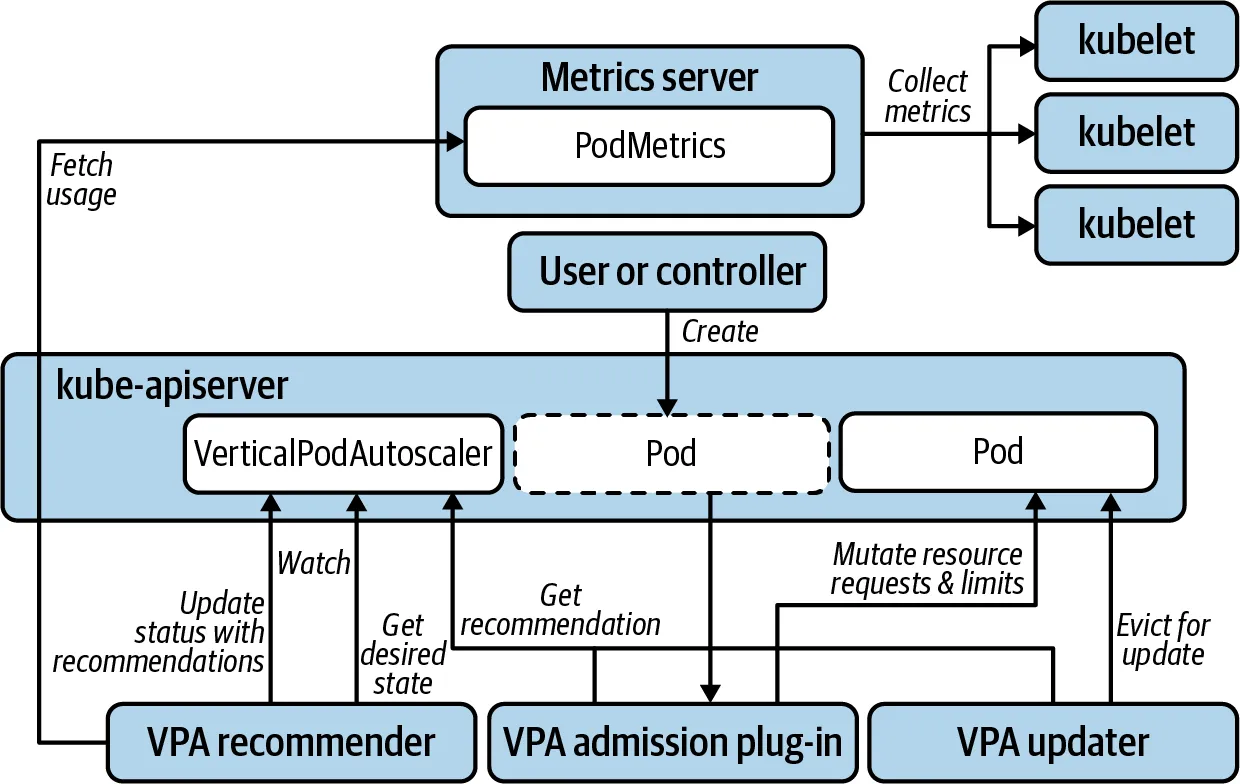
3. CAS (Cluster Autoscaler)
Unscheduled된 Pending Pod을 해결하기 위해 새로운 Node 추가
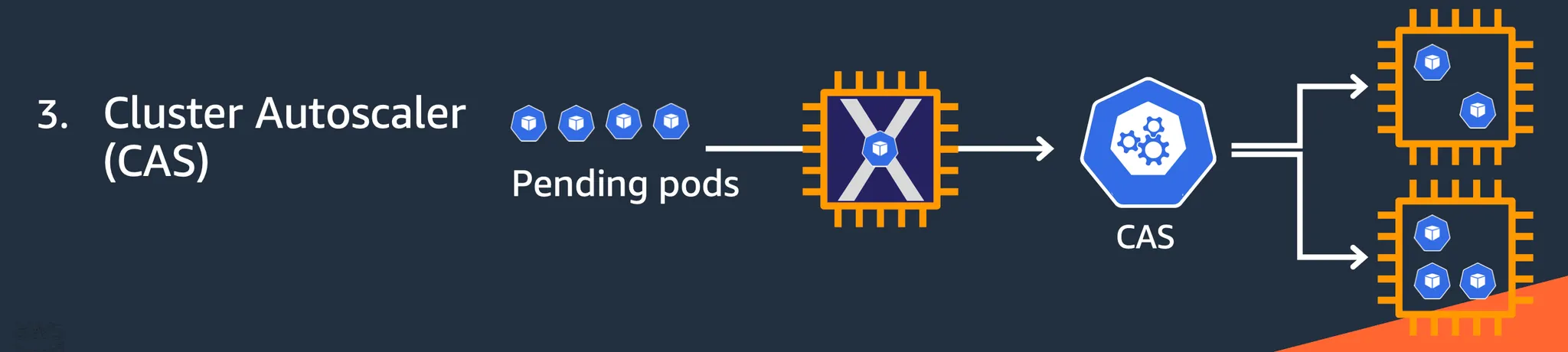
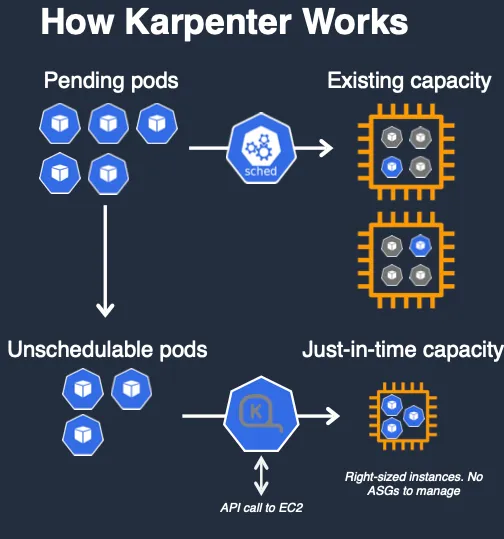
4. Karpenter
CAS의 단점을 보완하는 고성능 Autoscaler
특징: Just-in-time capacity 제공
4. AWS 및 Kubernetes 오토스케일링 정책
4.1 AWS Auto Scaling 정책
| 유형 | 특징 |
|---|---|
| Simple/Step Scaling | 수동 반응형, 동적 확장. 고객이 정의한 단계에 따라 메트릭을 모니터링하고 인스턴스를 추가 또는 제거 |
| Target Tracking Scaling | 자동 반응형, 목표 메트릭 유지. 고객이 정의한 목표 메트릭을 유지하기 위해 자동으로 인스턴스를 추가 또는 제거 |
| Scheduled Scaling | 수동 사전 계획 확장. 고객이 정의한 일정에 따라 인스턴스를 시작하거나 종료 |
| Predictive Scaling | 자동 사전 계획 확장. 과거 트렌드를 기반으로 용량을 선제적으로 시작 |
4.2 Kubernetes Auto Scaling 정책
| 확장 방법 | 적용 대상 |
|---|---|
| 컨테이너 수평적 확장 | Pod 수 증가 |
| 컨테이너 수직적 확장 | 기존 Pod 리소스 증가 |
| 노드 수평적 확장 | Node 수 증가 |
| 노드 수직적 확장 | 기존 Node 성능 향상 |
| 확장 기준 | 설명 |
|---|---|
| 컨테이너 메트릭 기반 | Pod의 CPU/Memory 사용량 기준 |
| 애플리케이션 메트릭 기반 | 서비스 요청 수, 응답 시간 기반 |
| 이벤트 기반 | 예약된 일정, 대기열 이벤트 기반 |
| 정책 유형 | 설명 |
|---|---|
| 단순 확장 | 수동으로 Pod/Node 추가 |
| 단계 확장 | 설정된 단계별로 자동 확장 |
| 목표 추적 확장 | 목표 메트릭을 기반으로 동적 확장 |
5. AWS EKS 주요 Autoscaler
- HPA: 서비스 부하 증가 시 새로운 Pod 추가
- VPA: 서비스 부하 증가 시 기존 Pod 리소스 증가
- CAS: Node 리소스 부족 시 새로운 Node 추가
- Karpenter: Pending Pod 발생 시 새로운 Node 및 Pod 생성
6. Kubernetes HPA 아키텍처
- cAdvisor: 컨테이너의 CPU/메모리 데이터를 수집.
- metrics-server: Kubelet을 통해 수집된 데이터를 API 서버에 등록.
- HPA: 15초마다 CPU/메모리 사용률을 확인하여 확장 여부를 결정.
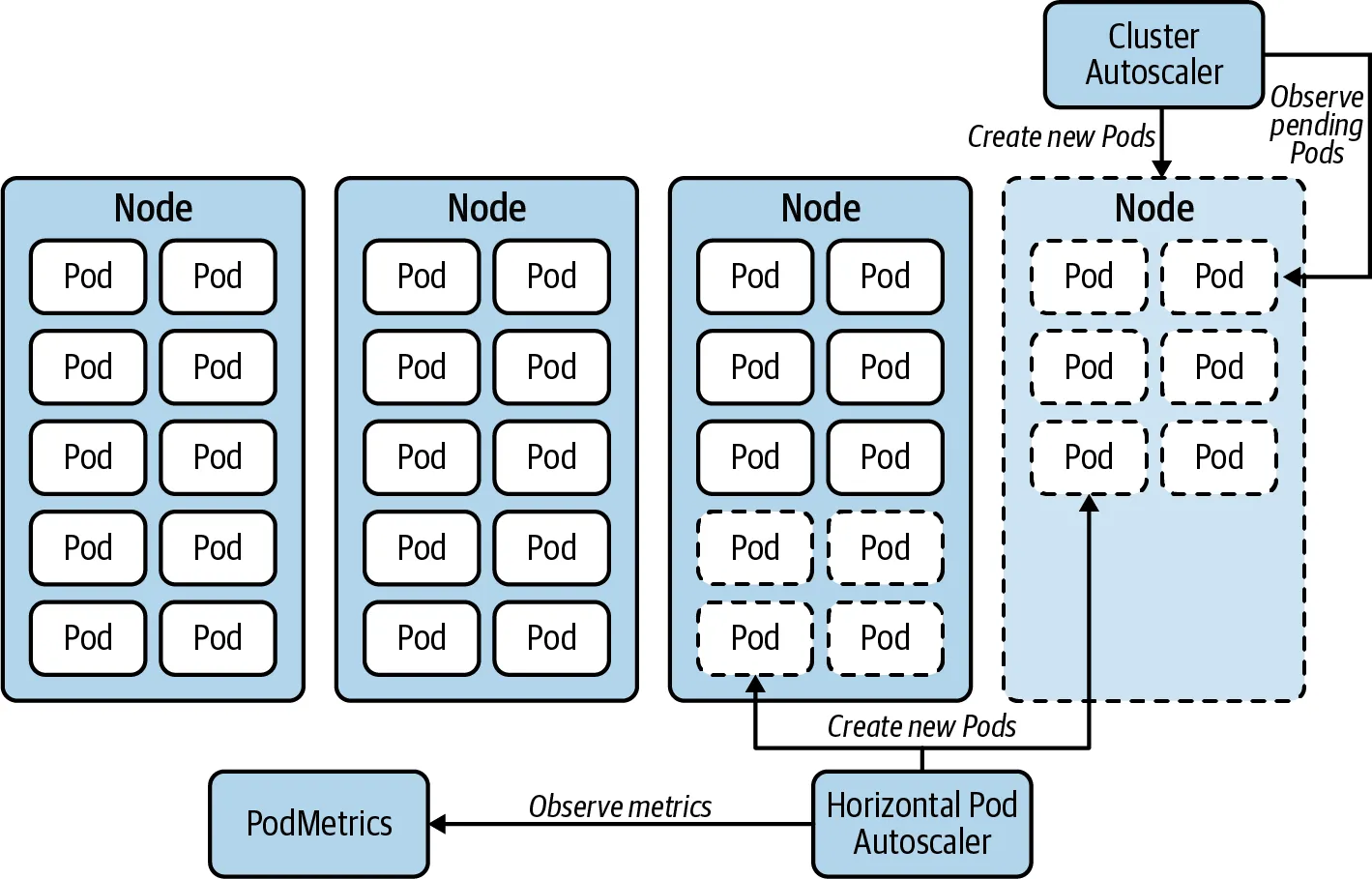
7. AWS Cluster Autoscaler
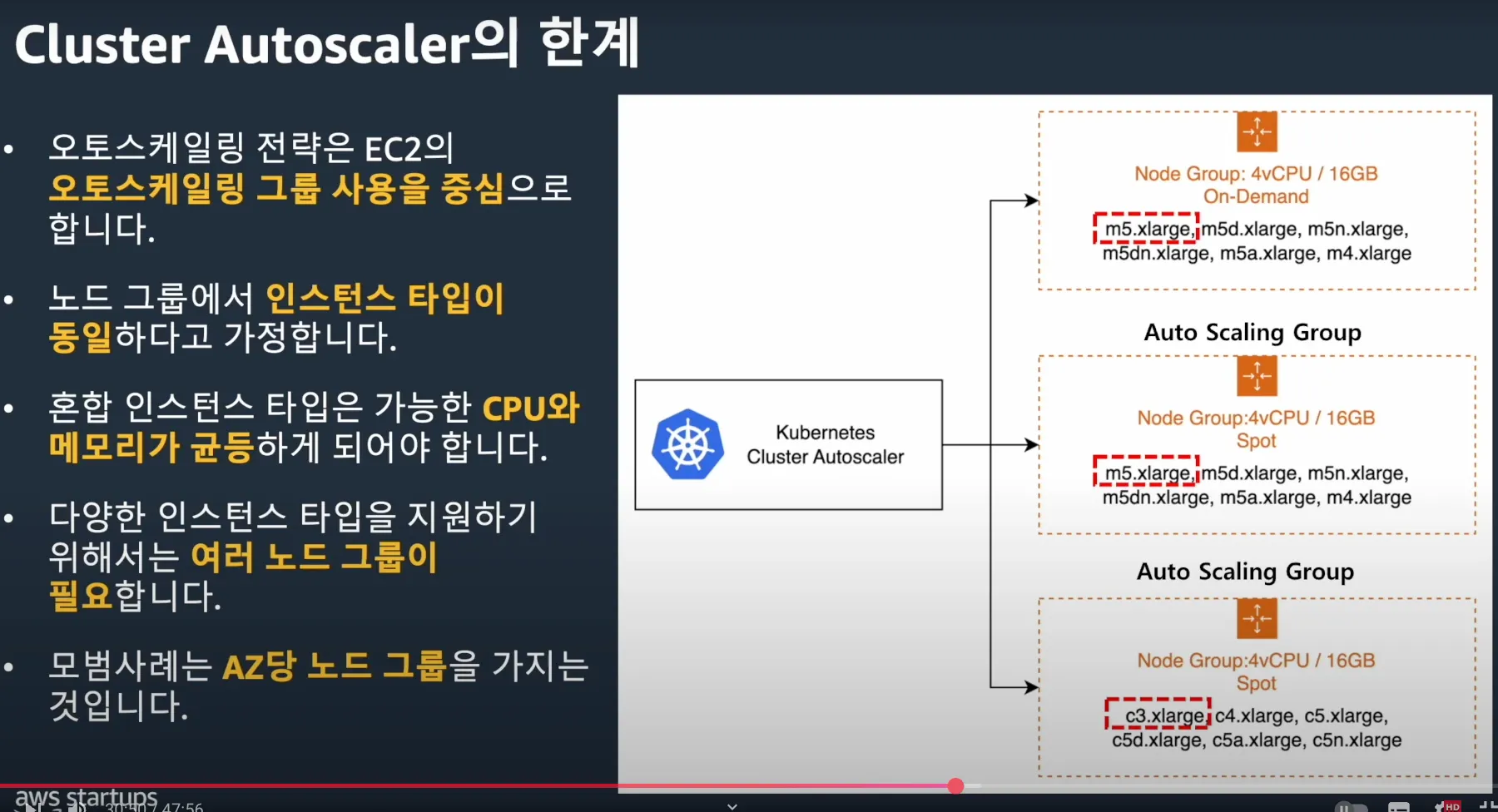
7.1 AWS Auto Scaling 한계점
https://www.youtube.com/watch?v=jLuVZX6WQsw
- 관리 복잡성 증가
- 최적화 설정 어려움
- 비용 관리 어려움
- 노드 그룹 내에서 인스턴스 타입이 동일하다고 가정하기 때문에 서로 다른 인스턴스 타입을 사용하려면 별도의 노드 그룹을 생성해야 합니다. 다양한 인스턴스 타입을 지원하려면 여러 개의 노드 그룹을 구성해야 합니다.
- 각 가용 영역(AZ)당 하나의 노드 그룹을 유지하는 것이 모범 사례이므로, 여러 가용 영역에 걸쳐 노드 그룹을 생성해야 합니다.
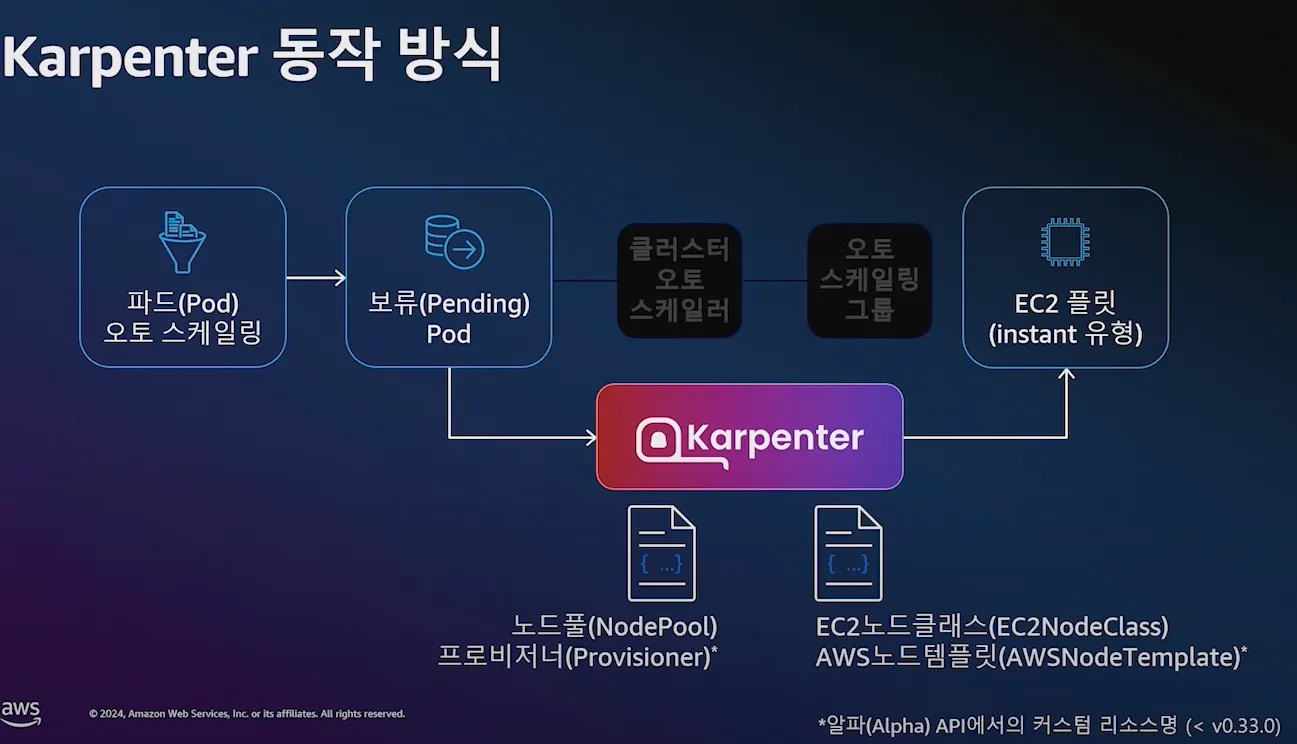
7.2 동작 방식
-
파드(Pod) 오토 스케일링 → 보류(Pending) Pod → 클러스터 오토 스케일러 → 오토 스케일링 그룹 → EC2 플릿(instant 유형)
-
단계별 동작 흐름:
- 파드(Pod) 오토스케일링 발생 → 보류(Pending) Pod 생성
- 클러스터 오토스케일러가 감지 후 오토 스케일링 그룹 호출
- 오토 스케일링 그룹이 EC2 플릿(Instant 유형) 호출하여 신규 노드 추가
- 새로운 노드가 클러스터에 등록되면서 Pending Pod가 할당됨
-
특징:
- 클러스터 오토스케일러는 반응 속도가 느린 편입니다.
- 즉각적인 대응이 어려울 수 있으며, Pending Pod이 생길 가능성이 높습니다.
8. Karpenter의 동작 방식
8.1 주요 특징
- 유연한 노드 프로비저닝
- 빠른 스케일링 및 비용 최적화
- 똑똑한 통합 관리 및 간소화된 설정
- 향상된 리소스 활용 및 확장성
- EC2 Fleet API를 활용하여 적절한 인스턴스 자동 프로비저닝
- 쿠버네티스 네이티브 아키텍처 (Watch API, Labels, Finalizers 활용)
- Over Provisioning을 통한 트래픽 스파이크 대비 가능
- Consolidation 기능을 통해 클러스터 내 리소스 최적화
8.2 기본 동작 흐름
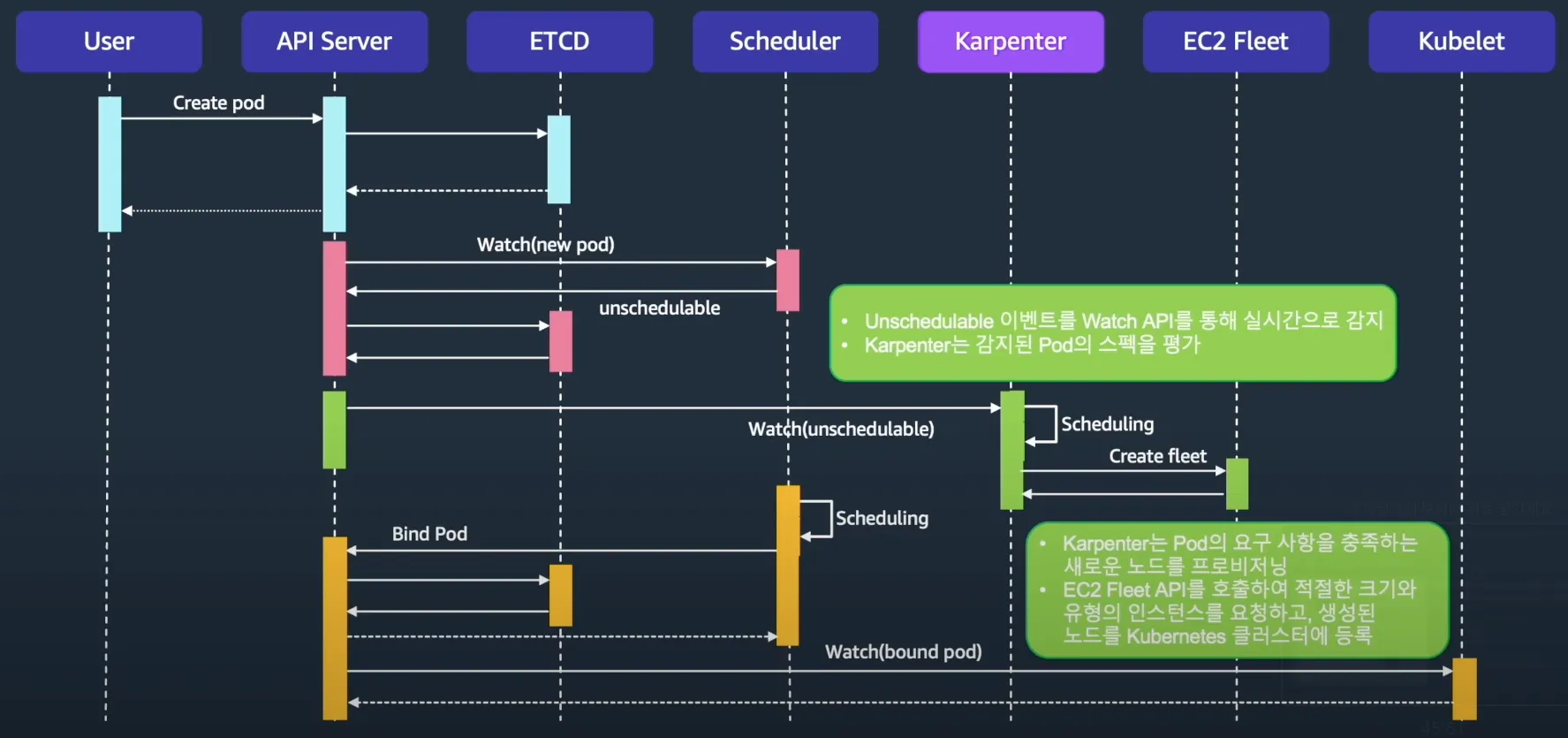
https://www.youtube.com/watch?v=jLuVZX6WQsw
- 파드(Pod) 오토 스케일링 → 보류(Pending) Pod → Karpenter → EC2 플릿(instant 유형)
- Pending Pod 발생 → Karpenter가 감지
- Karpenter가 Pod 스펙 평가
- 적절한 크기 및 유형의 EC2 인스턴스를 생성
- 신규 노드를 Kubernetes 클러스터에 등록
- Kube-scheduler가 새로운 Node에 Pod 스케줄링
- 특징:
- 반응 속도가 빠른 편이라 1분 이내에 노드 증설이 가능합니다.
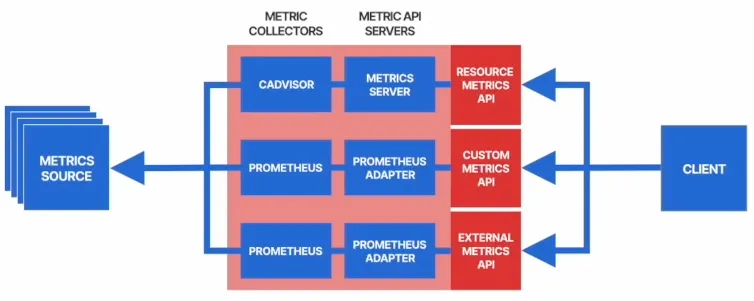
9. Custom Metric 기반 Auto Scaling
9.1 Metric 종류
| Metric 유형 | 설명 |
|---|---|
| Resource Metric API | CPU, 메모리 기반 Pod 스케일링 (metrics.k8s.io) |
| Custom Metric API | 클러스터 내부 정의된 메트릭 기반 스케일링 (custom.metrics.k8s.io) |
| External Metric API | 외부 서비스 기반 스케일링 (external.metrics.k8s.io) |
10. KEDA (Kubernetes Event-driven Autoscaling)
-
특징:
- 이벤트 기반 오토스케일링을 수행하며, HPA와 연계되어 작동합니다.
- 다양한 트리거(예: Cron, 메시지 대기열 등)를 활용하여 스케일링을 수행합니다.
- ScaledObject 오브젝트를 통해 스케일링 동작을 정의할 수 있습니다.
- Karpenter와 통합하여 클러스터 수준의 오토스케일링을 지원합니다.
-
Metrics Server:
- KEDA는 외부 메트릭 서버(External Metric API)를 사용합니다.
- External Metric API (external.metrics.k8s.io)를 호출하여 데이터를 수집합니다.
- 기존 HPA와 협력하여 메트릭 기반의 동적 스케일링을 지원합니다.
참고
