이 글은 CloudNet@팀의 AWS EKS Workshop Study(AEWS) 3기 스터디 내용을 바탕으로 작성되었습니다.
AEWS는 CloudNet@의 '가시다'님께서 진행하는 스터디로, EKS를 학습하는 과정입니다.
EKS를 깊이 있게 이해할 기회를 주시고, 소중한 지식을 나눠주시는 가시다님께 다시 한번 감사드립니다.
이 글이 EKS를 학습하는 분들께 도움이 되길 바랍니다.
1. EKS란?
Amazon Elastic Kubernetes Service(EKS)는 '완전 관리형 Kubernetes 서비스'로, 사용자가 Kubernetes 컨트롤 플레인(Control Plane)과 노드(Nodes)를 직접 설치, 운영 및 유지보수할 필요 없이 Kubernetes 클러스터를 실행할 수 있도록 지원합니다.
EKS는 기본적으로 AWS의 인프라 위에서 실행되며, AWS 서비스와 긴밀하게 통합됩니다.
2. 주요 특징
✔ 고가용성(High Availability)
Amazon EKS는 여러 AWS 가용 영역에 걸쳐 컨트롤 플레인을 자동으로 배포하고 크기를 조정하여 높은 가용성을 보장합니다.
컨트롤 플레인은 인스턴스의 크기를 자동으로 조정하고, 비정상적인 컨트롤 플레인 인스턴스를 감지하여 교체합니다.
버전 업데이트 및 패치 관리 자동화를 지원하여 Kubernetes 클러스터 유지보수를 간소화합니다.
✔ AWS 서비스와 긴밀한 통합
Amazon EKS는 다양한 AWS 서비스와 기본적으로 통합되며, 이를 통해 보다 효율적인 클러스터 운영이 가능합니다.
✔ Kubernetes 생태계와의 호환성
Amazon EKS는 오픈 소스 Kubernetes의 최신 버전을 실행하므로, Kubernetes 커뮤니티에서 사용되는 모든 기존 플러그인과 도구를 그대로 활용할 수 있습니다.
표준 Kubernetes 애플리케이션을 코드 수정 없이 EKS로 쉽게 마이그레이션할 수 있습니다.
3. 추가적인 강점
✔ 보안 및 규정 준수
Amazon EKS는 AWS Fargate(서버리스 컴퓨팅 옵션)와 통합되어 서버리스 Kubernetes 클러스터를 운영할 수 있습니다.
AWS PrivateLink를 사용하여 VPC 내부에서 완전한 네트워크 격리 환경을 유지할 수 있습니다.
EKS는 보안 및 규정 준수를 준수하는 기업 환경에 적합합니다.
✔ 자동 확장(Autoscaling) 기능
Kubernetes의 Cluster Autoscaler를 지원하여 노드 풀을 자동으로 확장/축소할 수 있습니다.
Horizontal Pod Autoscaler(HPA) 및 Vertical Pod Autoscaler(VPA)와 연동하여 워크로드에 따라 리소스를 동적으로 조정할 수 있습니다.
✔ 하이브리드 및 멀티클라우드 지원
AWS 외부에서도 Kubernetes 클러스터를 실행할 수 있도록 Amazon EKS Anywhere를 지원합니다.
AWS Outposts와 연동하여 온프레미스 환경에서도 EKS를 활용할 수 있습니다.
4. 아키텍처
💡 Amazon EKS는 크게 두 부분으로 구성됩니다:
✔ 컨트롤 플레인(Control Plane) → AWS가 완전히 관리
✔ 데이터 플레인(Data Plane, Worker Nodes) → 사용자가 직접 관리
💡 클러스터의 네트워크 통신 방식은 EKS Cluster Endpoint 설정에 따라 달라집니다:
✔ Public
✔ Public & Private
✔ Private
이제 각 요소를 자세히 살펴보겠습니다.
4-1. 컨트롤 플레인(Control Plane)
✅ 역할: Kubernetes 클러스터의 핵심 컴포넌트를 관리하며, 클러스터 전체를 조율하는 역할을 함
✅ 특징: AWS에서 완전 관리되며, 여러 가용 영역에 걸쳐 자동으로 배포되어 고가용성 보장
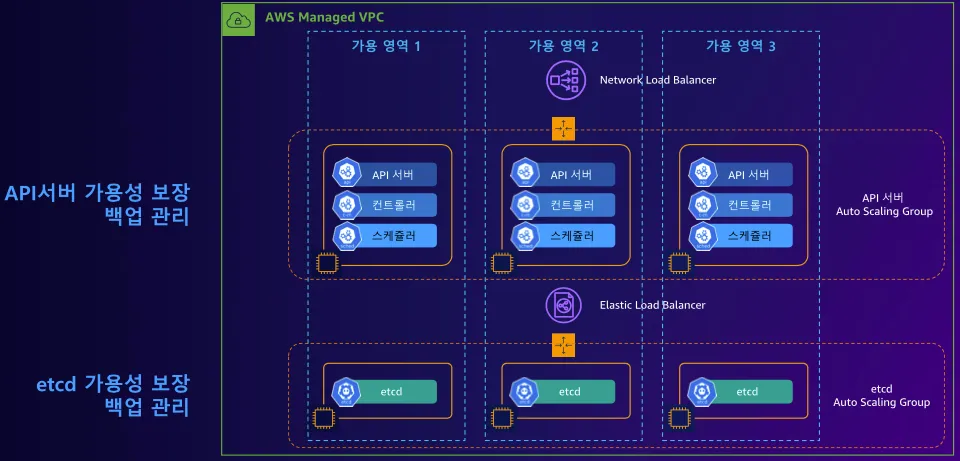
🛠 구성 요소
| 구성 요소 | 설명 |
|---|---|
| API 서버 (kube-apiserver) | Kubernetes의 중앙 허브 역할을 하며, 클러스터의 모든 요청을 받아들이고, 인증 및 유효성 검사를 수행하며 다른 컨트롤 플레인 컴포넌트와 통신 |
| 컨트롤러 매니저 (kube-controller-manager) | 클러스터의 상태를 모니터링하고, 여러 개의 컨트롤러(노드 컨트롤러, 레플리케이션 컨트롤러 등)를 실행하며, 클러스터의 원하는 상태가 유지되도록 자동 조정 |
| 스케줄러 (kube-scheduler) | 새로운 Pod가 생성될 때 적절한 워커 노드에 배치 |
| etcd | 클러스터의 모든 상태 정보를 저장하는 분산 키-값 저장소 |
| 클라우드 컨트롤러 매니저 (cloud-controller-manager) | AWS와 같은 클라우드 공급자와의 통합을 관리하여, 로드 밸런서 생성, 노드 정보 동기화 등의 기능 수행 |
🔹 특이점:
✔ EKS의 컨트롤 플레인은 여러 가용 영역에 자동으로 배포되어 고가용성(HA)를 보장
✔ 사용자는 직접 관리할 필요 없이 AWS에서 자동으로 패치 및 업그레이드를 제공
✔ 클라우드 컨트롤러 매니저가 존재하여 AWS와 Kubernetes 리소스 간 연동을 담당
4-2. 데이터 플레인(Data Plane) = 워커 노드(Worker Nodes)
✅ 역할: 실제 컨테이너(Pods)가 실행되는 노드(서버)
✅ 특징: 사용자가 직접 관리해야 하며, EC2 인스턴스, AWS Fargate, EKS Auto Mode, Hybrid Nodes에서 실행 가능
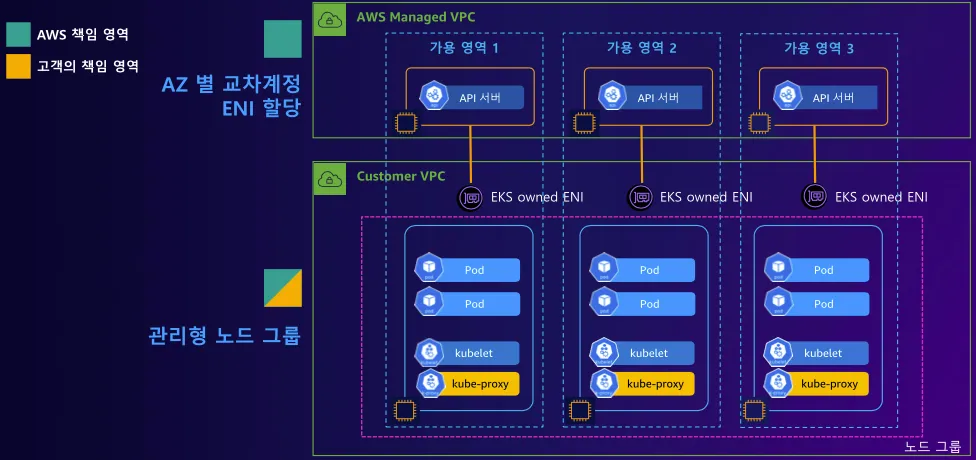
🛠 구성 요소
| 구성 요소 | 설명 |
|---|---|
| 워커 노드 (Worker Nodes) | 애플리케이션을 실행하는 물리적/가상 서버 (EC2, Fargate) |
| Kubelet | 각 노드에서 실행되는 에이전트로, API 서버와 통신하며 Pod의 상태를 모니터링 및 관리 |
| 컨테이너 런타임 (Container Runtime) | 컨테이너 실행 환경 (containerd, CRI-O 등. Docker는 공식적으로 deprecated됨) |
| CNI(Container Network Interface) | Pod 간 네트워크 연결을 담당, AWS의 VPC CNI를 기본 제공 |
| kube-proxy | 클러스터 내 네트워크 트래픽을 관리하며, Kubernetes 서비스 간 통신을 위한 프록시 역할 수행 (iptables 또는 IPVS 기반) |
🔹 특이점:
✔ 사용자는 EC2 인스턴스 기반 노드 그룹 또는 Fargate 기반 서버리스 노드 중 선택 가능
✔ Cluster Autoscaler 및 Karpenter를 사용하여 노드 자동 확장 가능
✔ 각 워커 노드는 Kubelet을 통해 API 서버와 지속적으로 통신하며, Pod 상태를 관리
✔ kube-proxy가 각 노드에서 실행되어 서비스 트래픽을 적절히 분배
✔ 노드 로컬 컴포넌트(예: kube-proxy, 로깅 에이전트)가 추가적으로 실행될 수 있음
📌 EKS 데이터 플레인 운영 방식
| 운영 방식 | 설명 |
|---|---|
| Managed Node Groups | AWS에서 관리하는 최신 EKS Optimized AMI를 사용하는 노드 그룹. AWS가 노드 패치 및 업그레이드를 자동 수행 |
| Self-Managed Nodes | 사용자가 직접 커스텀 AMI를 사용하고, Auto Scaling Group(ASG)을 관리하며, OS 패치를 직접 수행 |
| AWS Fargate (서버리스) | 사용자가 노드를 직접 운영하지 않고, AWS가 Pod 단위의 Micro VM을 제공하는 서버리스 실행 환경 |
| EKS Hybrid Nodes | 온프레미스 및 엣지 인프라를 Amazon EKS 클러스터의 노드로 활용할 수 있도록 지원하는 기능 |
| EKS Auto Mode | AWS가 컨트롤 플레인뿐만 아니라 데이터 플레인까지 자동 관리하는 완전 관리형 EKS 모델 |
| Karpenter | Kubernetes 클러스터의 유연한 자동 확장 기능을 제공하며, 애플리케이션 부하에 따라 최적화된 인프라를 동적으로 프로비저닝 |
4-3. EKS Owned ENI란?
- ENI: Elastic Network Interface
- AWS EKS는 관리형 컨트롤 플레인을 제공하며, 사용자의 AWS 계정 내에서 네트워크 인터페이스(ENI)를 생성하여 컨트롤 플레인과 통신합니다.
- 이 네트워크 인터페이스를 "EKS Owned ENI"라고 하며, 사용자의 VPC 안에 생성됩니다.
- EKS 클러스터가 처음 생성될 때 자동으로 프로비저닝되며, EKS 컨트롤 플레인과 클러스터 내의 노드(데이터 플레인) 간 통신을 담당합니다.
4-4. EKS Cluster Endpoint 모드
EKS 클러스터의 엔드포인트 설정은 Public, Public-Private, Private 세 가지 모드로 나뉘며,
각 설정은 EKS Owned ENI, Internet Gateway, Public/Private Hosted Zone, VPC Endpoint 등과 함께 동작 방식이 다릅니다.
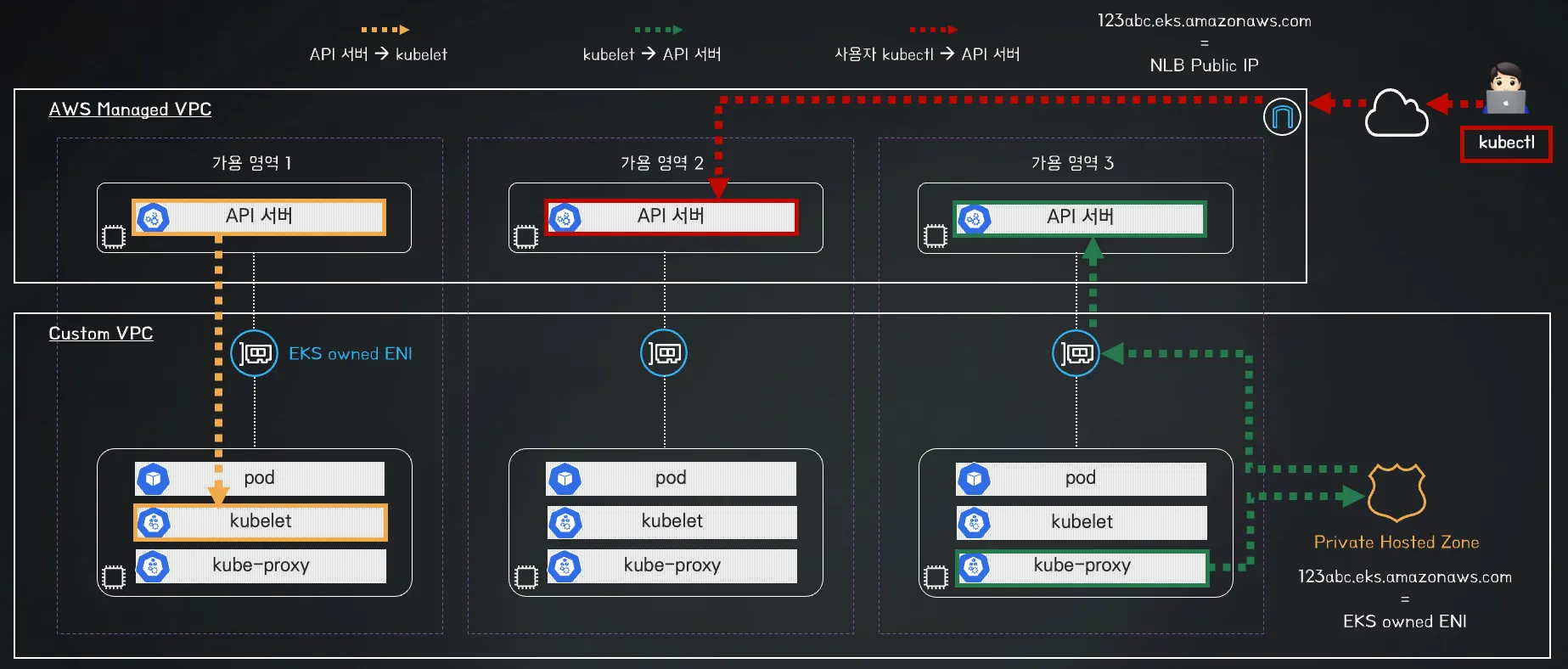
1️⃣ Public Cluster Endpoint Access 아키텍처
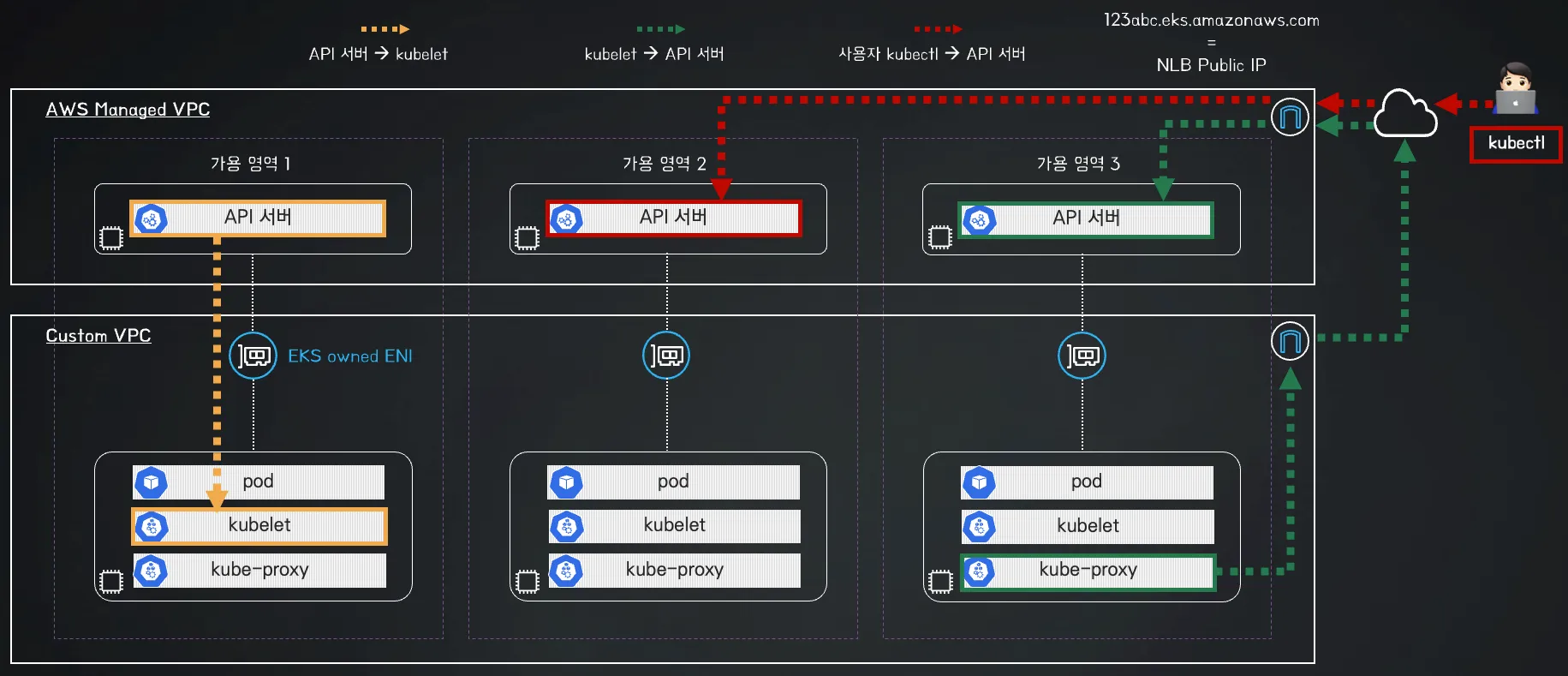
- api-server → kubelet [private 통신]
- kubectl-host → api-server [public 통신]
- kubelet / kube-proxy → api-server [public 통신]
📌 특징
✅ 클러스터의 제어부(Control Plane)는 퍼블릭 도메인을 통해 접근 가능
✅ EKS Owned ENI를 통해 워커 노드와 제어부 간 통신 수행
✅ 워커 노드는 퍼블릭 도메인을 통해 API 서버에 접근 가능
✅ kubectl 등의 클라이언트도 퍼블릭 도메인을 통해 접근 가능
📌 네트워크 구성
| 컴포넌트 | 통신 방식 |
|---|---|
| 제어부(Control Plane) → 워커 노드 Kubelet | EKS Owned ENI (AWS 내부 ENI) |
| 워커 노드 → 제어부(Control Plane) | 퍼블릭 도메인 (AWS 제공 API 서버 도메인) |
| 사용자(kubectl 등) → 제어부(Control Plane) | 퍼블릭 도메인 (AWS 제공 API 서버 도메인) |
📌 연계된 네트워크 리소스
✔ EKS Owned ENI → 컨트롤 플레인과 워커 노드 간 내부 통신 담당
✔ Internet Gateway (IGW) → 퍼블릭 도메인을 통한 API 서버 접근을 가능하게 함
✔ Public Hosted Zone → API 서버의 퍼블릭 엔드포인트를 제공
📌 장점
설정이 간단하며, 인터넷을 통해 어디서든 API 서버에 접근 가능
kubectl 사용이 쉬움 (추가적인 네트워크 설정 없이 접근 가능)
📌 단점
보안 리스크 존재 (공격자가 퍼블릭 엔드포인트를 통해 접근 가능)
제어부 접근이 인터넷 의존적 (VPC 내부 전용 통신이 불가능)
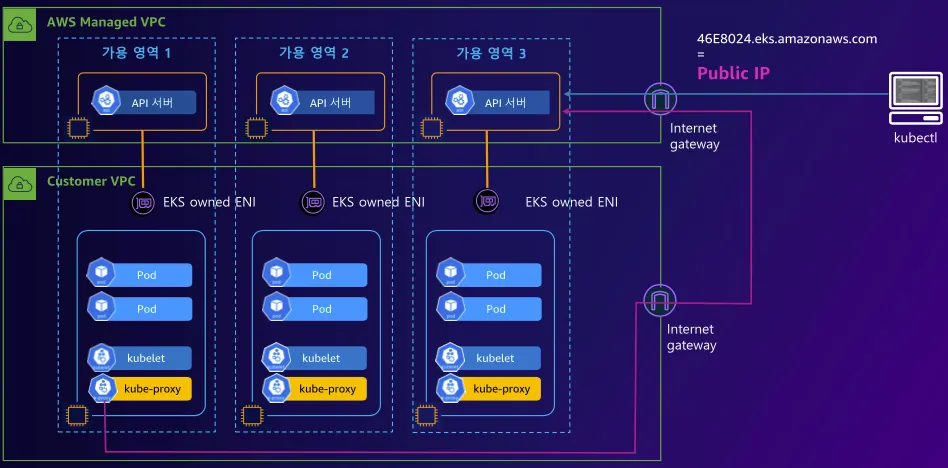
2️⃣ Public & Private Cluster Endpoint Access 아키텍처
- api-server → kubelet [private 통신]
- kubectl-host → api-server [public 통신]
- kubelet / kube-proxy → api-server [private 통신]
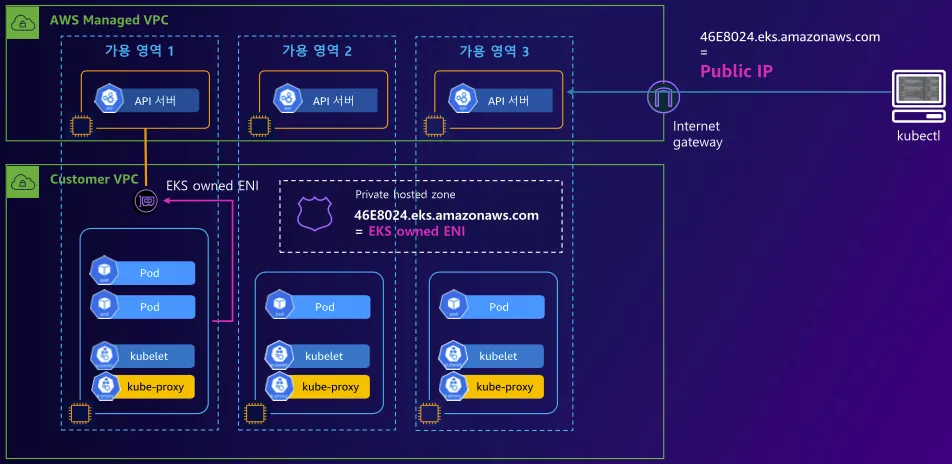
📌 특징
✅ 클러스터 제어부는 퍼블릭 + 프라이빗 도메인을 동시에 사용
✅ EKS Owned ENI를 통해 워커 노드와 제어부 간 통신 수행
✅ 워커 노드는 퍼블릭 도메인이 아닌 프라이빗 도메인(EKS Owned ENI)을 통해 API 서버에 접근
✅ kubectl 클라이언트는 여전히 퍼블릭 도메인 사용 가능
📌 네트워크 구성
| 컴포넌트 | 통신 방식 |
|---|---|
| 제어부(Control Plane) → 워커 노드 Kubelet | EKS Owned ENI (AWS 내부 ENI) |
| 워커 노드 → 제어부(Control Plane) | 프라이빗 도메인(EKS Owned ENI) |
| 사용자(kubectl 등) → 제어부(Control Plane) | 퍼블릭 도메인 (AWS 제공 API 서버 도메인) |
📌 연계된 네트워크 리소스
✔ EKS Owned ENI → 컨트롤 플레인과 워커 노드 간 내부 통신 담당
✔ Internet Gateway (IGW) → kubectl의 퍼블릭 엔드포인트 접근을 가능하게 함
✔ Public Hosted Zone → 사용자(kubectl)에서 퍼블릭 도메인으로 API 서버에 접근 가능하도록 설정
✔ Private Hosted Zone → 내부 워커 노드가 API 서버에 프라이빗 도메인으로 접근 가능하도록 설정
📌 장점
워커 노드의 API 서버 접근이 프라이빗 네트워크에서만 이루어짐 → 보안 강화
kubectl은 여전히 퍼블릭 도메인을 사용 가능하므로 접근이 편리함
📌 단점
퍼블릭 엔드포인트가 그대로 존재하므로, 보안상 공격 가능성이 있음
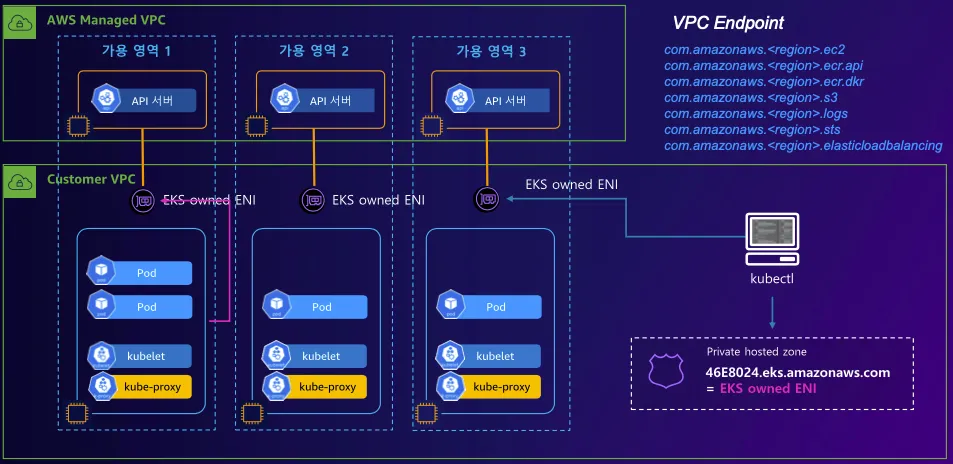
3️⃣ Private Cluster Endpoint Access 아키텍처
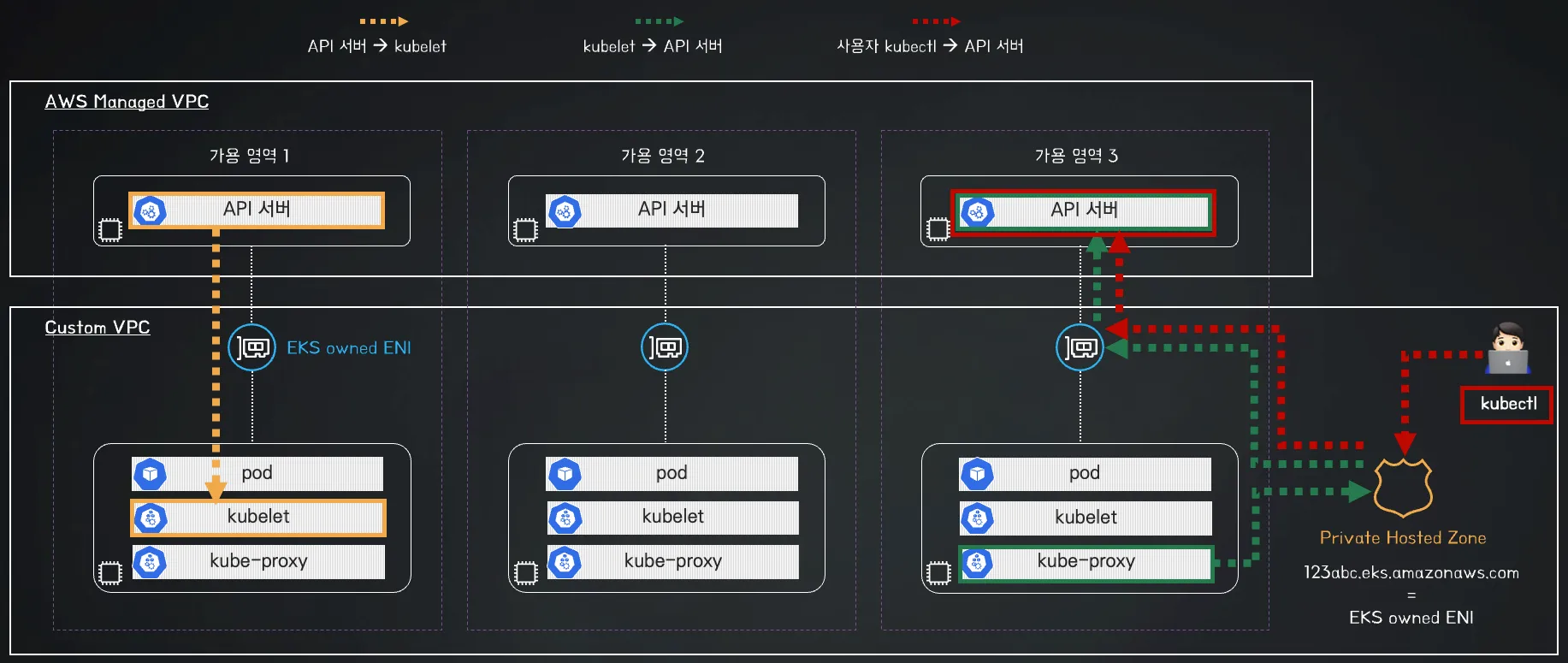
- api-server → kubelet [private 통신]
- kubectl-host → api-server [private 통신]
- kubelet / kube-proxy → api-server [private 통신]
📌 특징
✅ 클러스터 제어부는 오직 프라이빗 도메인에서만 접근 가능
✅ EKS Owned ENI를 통해 워커 노드와 제어부 간 통신 수행
✅ kubectl도 퍼블릭 도메인을 사용할 수 없으며, VPC 내에서만 API 서버 접근 가능
✅ 외부에서 접근하려면 VPN, AWS Direct Connect, Bastion Host 필요
📌 네트워크 구성
| 컴포넌트 | 통신 방식 |
|---|---|
| 제어부(Control Plane) → 워커 노드 Kubelet | EKS Owned ENI (AWS 내부 ENI) |
| 워커 노드 → 제어부(Control Plane) | 프라이빗 도메인 (EKS Owned ENI) |
| 사용자(kubectl 등) → 제어부(Control Plane) | 프라이빗 도메인 (EKS Owned ENI), VPC Endpoint |
📌 연계된 네트워크 리소스
✔ EKS Owned ENI → 컨트롤 플레인과 워커 노드 & 사용자(kubectl) 간 내부 통신 담당
✔ VPC Endpoint → VPC 내부에서 API 서버에 접근할 수 있도록 설정
✔ Private Hosted Zone → 내부에서만 API 서버 도메인 확인 가능
📌 장점
완벽한 보안 → 퍼블릭 접근이 차단되므로, 외부 공격 가능성 없음
내부 통신 전용 → API 서버와 노드 간 트래픽이 인터넷을 거치지 않음
📌 단점
kubectl 사용이 불편 → 외부에서 접근하려면 VPN, Direct Connect, Bastion Host 필요
네트워크 설정이 복잡
🚀 최종 정리
| EKS Cluster Endpoint | 제어부 → 워커노드 | 워커노드 → 제어부 | 사용자(kubectl) → 제어부 | 네트워크 리소스 |
|---|---|---|---|---|
| Public | EKS Owned ENI | 퍼블릭 도메인 | 퍼블릭 도메인 | Internet Gateway, Public Hosted Zone |
| Public & Private | EKS Owned ENI | 프라이빗 도메인 (EKS Owned ENI) | 퍼블릭 도메인 | Internet Gateway, Public Hosted Zone, Private Hosted Zone |
| Private | EKS Owned ENI | 프라이빗 도메인 (EKS Owned ENI) | 프라이빗 도메인 (EKS Owned ENI, VPC Endpoint) | VPC Endpoint, Private Hosted Zone |
🔗 참고: EKS Cluster Endpoint Access
4-5. EKS 아키텍처 흐름
1️⃣ 사용자가 EKS 클러스터를 생성하면 AWS가 컨트롤 플레인을 자동으로 배포
- 사용자가 EKS 클러스터를 생성하면 AWS가 관리형 컨트롤 플레인을 자동으로 프로비저닝
- 컨트롤 플레인 구성 요소(API 서버, etcd, 컨트롤러 매니저, 스케줄러 등)는 AWS 관리 하에 여러 가용 영역에 걸쳐 분산 배포됨
- 컨트롤 플레인은 퍼블릭 또는 프라이빗 엔드포인트 설정에 따라 접근 방식이 달라짐
- 컨트롤 플레인은 EKS Owned ENI를 생성하여 데이터 플레인과 내부 통신 수행
2️⃣ 컨트롤 플레인은 클러스터의 상태를 관리하며, API 요청을 처리하고 etcd에 저장
- 사용자가 kubectl 명령어를 실행하면 API 서버(kube-apiserver)가 이를 처리
- API 서버는 모든 요청을 받아들이고, etcd에 클러스터 상태를 저장
- API 요청이 발생하면 컨트롤러 매니저(kube-controller-manager)가 이를 감지하고 적절한 조치를 수행
- 스케줄러(kube-scheduler)는 새롭게 생성된 Pod을 적절한 워커 노드에 배치
- API 서버는 EKS Owned ENI를 통해 데이터 플레인과 직접 통신
3️⃣ 데이터 플레인(워커 노드)은 EC2 또는 Fargate에서 실행되며, 애플리케이션을 실제로 실행
- 워커 노드는 EC2 인스턴스 또는 AWS Fargate에서 실행됨
- 워커 노드에는 Kubelet이 실행되며, 컨트롤 플레인으로부터 명령을 받아 Pod를 관리
- 컨테이너 런타임이 Pod를 실행하고 관리
- Kubernetes CNI를 사용하여 네트워크가 설정됨
- kube-proxy가 네트워크 트래픽을 관리하며, 클러스터 내 서비스간 라우팅을 수행
4️⃣ 노드 간 네트워크 연결은 AWS VPC CNI를 사용하여 설정
- EKS에서는 AWS VPC CNI를 기본적으로 사용하여 Pod 간 네트워크를 설정
- Pod는 VPC 내부에서 직접 IP를 할당받아 통신 가능 (AWS VPC 네트워크와 동일한 방식)
- kube-proxy는 서비스 트래픽을 관리하고, Pod 간 통신을 최적화
- 클러스터 내부 통신은 EKS Owned ENI를 통해 워커 노드와 제어부 간 이루어짐
- 필요 시 ELB(NLB, ALB)를 이용하여 외부 트래픽을 수용 가능
5️⃣ 로드 밸런싱, 보안 및 모니터링은 AWS 서비스와 통합하여 운영 가능
- AWS Load Balancer Controller를 사용하여 ALB/NLB를 프로비저닝 가능
- Kubernetes Ingress Controller를 사용하여 트래픽 라우팅 가능
- AWS CloudWatch, AWS X-Ray, AWS OpenTelemetry를 활용한 모니터링 가능
- AWS IAM을 활용하여 Kubernetes RBAC과 연동 가능
- AWS KMS와 Secret Manager를 이용하여 보안 강화 가능
4-6. EKS 컨트롤 플레인의 부하 분산 및 통신
💡 EKS API 서버 앞단에서 NLB를 사용하는 이유
EKS 컨트롤 플레인의 API 서버 앞단에 NLB(Network Load Balancer)를 사용하는 주된 이유는 속도와 연결 안정성 때문입니다.
✅ NLB가 선택된 이유
- 낮은 지연 시간 (Low Latency)
- API 서버는 클러스터 내부에서 가장 많은 요청을 처리하는 핵심 요소
- NLB는 L4(TCP) 기반으로 동작하며, 패킷을 즉시 전달 → API 서버 응답 속도 향상
- 반면, ALB는 L7(HTTP) 요청을 처리해야 하므로 오버헤드 발생
- Kubernetes API 요청은 HTTP 기반이긴 하지만, AWS 내부에서 빠른 처리 속도를 유지하기 위해 L4 부하 분산이 필요할 수 있다.
- 고성능 및 대량 트래픽 처리
- API 서버는 클러스터의 모든 리소스 요청을 처리 → 대량의 요청을 효율적으로 분산해야 함
- NLB는 초당 수백만 개의 동시 연결을 처리할 수 있도록 설계됨
- Hyperplane 기반 아키텍처
- AWS Hyperplane은 초당 수억 개의 연결을 지원하며, 메모리 기반 부하 분산으로 초저지연 제공
- 확장성과 가용성이 뛰어나, API 서버처럼 트래픽이 많은 서비스에 적합
✅ ALB가 적절하지 않은 이유
- LB(Application Load Balancer)는 L7에서 동작하며, HTTP 경로 기반 라우팅 및 세션 관리 기능을 제공
- 하지만, API 서버는 기본적으로 고속의 단순한 TCP/HTTP 요청 처리가 필요하며, 별도의 L7 경로 기반 라우팅이 필요하지 않기 때문에 ALB가 오히려 불필요한 부하를 발생시킬 수 있음
- 또한, 인증 및 권한 부여(RBAC, IAM 등)는 Kubernetes 내부에서 처리되므로, ALB의 인증 기능도 필요하지 않음
📌 결론:
- EKS API 서버는 빠른 요청 처리가 핵심이므로, L4 부하 분산이 가능한 NLB를 선택
- NLB는 대규모 트래픽 처리, 낮은 지연 시간, 고성능을 제공하여 EKS API 서버에 최적화됨
- ALB는 HTTP 라우팅이 필요한 경우 적합하지만, API 서버에는 불필요한 오버헤드 발생
💡 EKS API 서버 ↔ etcd 간 통신 방식
📌 초기 EKS 아키텍처 (CLB 사용)
초기에 AWS는 etcd 앞단에서 CLB(Classic Load Balancer)를 사용하여 트래픽을 부하 분산했었음

📌 CLB가 선택됐던 이유
- AWS의 기본 부하 분산 아키텍처 활용
- AWS는 초기부터 부하 분산을 위해 CLB를 기본 사용
- EKS가 처음 출시될 당시(2018년), 기존 AWS 서비스들이 CLB를 활용한 사례가 많았고, 기존 인프라와 호환성을 고려
- 기존 AWS 관리형 서비스에서도 CLB가 일반적인 내부 부하 분산기로 사용되었을 가능성이 큼
- etcd는 강력한 세션 유지(Persistent Connection)가 필요
- etcd는 gRPC 기반의 Raft Consensus Algorithm을 사용하여 데이터 일관성을 유지
- Raft 알고리즘 특성상, etcd 노드 간의 지속적인 세션 유지(Session Persistence)가 중요
- CLB는 기본적으로 Connection Stickiness(세션 유지) 기능을 제공하므로, 안정적인 etcd 클러스터 운영에 적합
- NLB와 CLB 모두 L4(TCP) 부하 분산을 수행하지만, NLB는 단순히 요청을 분산하는 역할을 하며, CLB는 기본적인 연결 유지 기능을 제공
- NLB의 초기 헬스체크 문제
- 초기 NLB는 헬스체크가 느렸음 → NLB의 최소 헬스체크 타임은 19초, 반면 CLB는 9초
- etcd는 빠른 장애 감지 및 리더 선출이 중요하기 때문에, 상대적으로 빠른 CLB의 헬스체크가 더 적합했을 가능성 큼
- 🔗 출처: NLB 헬스체크 문제
📌 CLB 사용 시 문제점
- 네트워크 홉 증가 → 지연(latency) 증가
- API 서버 → CLB → etcd 구조에서 CLB를 거치면서 불필요한 네트워크 홉 증가
- CLB 자체의 확장성 문제
- etcd 트래픽이 증가하면 CLB의 확장도 필요 → 추가적인 관리 비용 발생
- 추가적인 의존성
- CLB 자체가 하나의 독립적인 관리 요소가 됨 → 운영 복잡성 증가
📌 개선된 EKS 아키텍처 (CLB 제거)
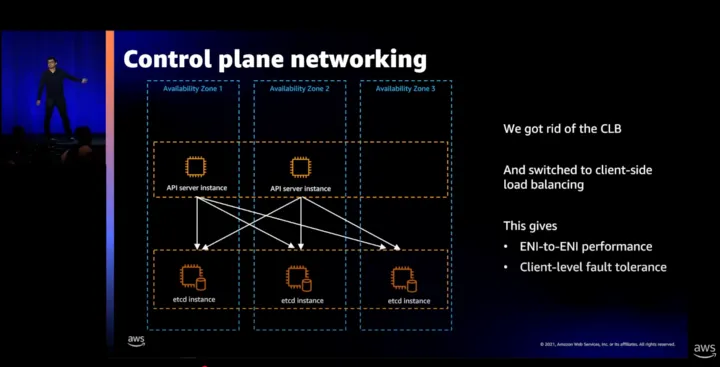
✅ AWS는 CLB를 제거하고 API 서버가 직접 etcd와 통신하는 방식으로 변경
✅ API 서버 ↔ etcd 간 ENI-to-ENI 직접 연결
✅ API 서버가 자체적으로 Client-Side Load Balancing 수행
✅ 각 API 리소스 유형(Pods, Nodes, Secrets 등)마다 독립적인 etcd 클라이언트 연결 생성
📌 CLB 제거 후 장점
- Latency 감소
- 불필요한 네트워크 홉 제거 → API 서버가 etcd에 직접 연결하여 응답 속도 향상
- 더 나은 성능
- ENI-to-ENI 직접 연결을 통해 etcd 성능 최적화
- 향상된 가용성
- API 리소스별 개별 etcd 연결 유지 → 장애 대응 능력 향상
📌 결론:
- 초기에는 CLB가 세션 유지성과 빠른 헬스체크 속도로 인해 선택됨
- CLB가 불필요한 네트워크 홉을 추가하면서 성능 저하 문제 발생
- API 서버가 ENI-to-ENI 직접 연결 & 자체 부하 분산(Client-Side Load Balancing) 수행하도록 변경
🔗 참고
