1. 멀티 스레드 개념
프로세스
실행 중인 하나의 프로그램으로 하나의 프로그램은 다중 프로세스를 만들기도 함
프로그램 A에서 프로세스 A', B' 생성됨
멀티태스킹
두 가지 이상의 작업을 동시에 처리하는 것으로 독립적으로 프로그램들을 실행하고 여러가지 작업을 처리하는 것은 멀티프로세스, 한 개의 프로그램을 실행하고 내부적으로 여러가지 작업을 처리하는 것은 멀티스레드
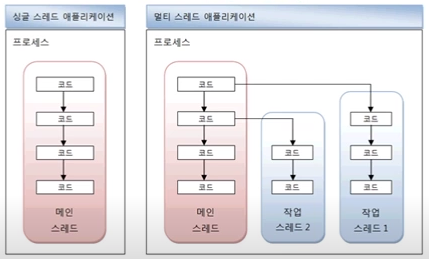
하나의 프로세스에 여러 개의 스레드 : 멀티 스레드
하나의 프로세스에 하나의 스레드 : 싱글 스레드
여러 개의 프로세스 동작 : 멀티 프로세스
메인 스레드
모든 사바 프로그램은 메인 스레드가 main()을 실행하면서 시작되어 메소드의 첫 코드부터 아래로 순차적 실행하며 마지막 코드 실행하거나 return 문을 만나면 실행이 종료됨
main 스레드는 작업 스레드를 만들어 병렬로 코드 실행 가능하기 때문에 멀티 스레드를 생성해 멀티 태스킹을 수행함
프로세스의 종료
싱글 스레드의 경우 메인 스레드가 종료하면 프로세스도 같이 종료되며, 멀티 스레드의 경우 실행 중인 스레드가 하나라도 있다면, 프로세스는 종료되지 않음
2. 작업 스레드 생성과 실행
병렬로 실행할 작업의 수 결정
메인 스레드
ㄴ 스레드 1 (네트워킹)
ㄴ 스레드 2 (드로잉)
작업 스레드 생성 방법
Thread 클래스로부터 직접 생성
class Task implements Runnable{
public void run(){
//run code
}
}
//how1
Runnable task = new Task();
Thread thread = new Thread(task);
//how2
Thread thread = new Thread(new Runnable(){
public void run(){
//thread code
}
});
//how3
Thread thread = new Thread( () -> {
//thread code
});
thread.start();
beep음과 beep 출력을 동시에 같이 하는 프로그램
public class BeepPrintExample {
public static void main(String[] args){
//how1
/*Runnable beepTask = new BeepTask();
Thread thread = new Thread(beepTask);
*/
//how2
/*Thread thread = new Thread(new Runnable() {
@Override
public void run(){
Toolkit toolkit = Toolkit.getDefaultTookKit();
for(int i = 0 ; i < 5 ; i++){
toolkit.beep();
try{Thread.sleep(500);}catch(Exception e){}
}
}
});*/
//how3
Thread thread = new Thread( () -> {
Toolkit toolkit = Toolkit.getDefaultToolkit();
for(int i = 0 ; i < 5 ; i++){
toolkit.beep();
try{Thread.sleep(500);}
catch(Exception e){}
}
});
thread.start();
for(int i = 0 ; i < 5 ; i++){
System.out.println("beep");
try{ Thread.sleep(500);}
catch(Exception e){}
}
}
}
public class BeepTask implements Runnable{
@Override
public void run(){
Toolkit toolkit = Toolkit.getDefaultToolkit();
for(int i =0 ; i < 5 ; i++){
toolkit.beep();
try{ Thread.sleep(500); }
catch(Exception e) {}
}
}
}Thread 하위 클래스로부터 생성
//직접 상속
public class WorkerThread extends Thread{
@Override
public void run(){
//Thread code
}
}
Thread = new WorkerThread();
//익명객체
Thread thread = new Thread(){
public void run(){
//Thread code
}
}
thread.start();beep음과 beep 출력을 동시에 같이 하는 프로그램
public void BeedThread extends Thread{
@Override
public void run(){
Toolkit toolkit = Toolkit.getDefaultToolkit();
for(int i = 0 ;i < 5 ; i++){
toolkit.beep();
try{Thread.sleep(500);} catch(Exception e){}
}
}
public class Main{
public static void main(String[] args){
//how1
Thread thread = new BeepThread();
//how2
Thread thread = new Thread(){
@Override
public void run(){
Toolkit toolkit = Toolkit.getDefaultToolkit();
for(int i =0 ; i < 5 ; i++){
toolkit.beep();
try{Thread.sleep(500);} catch(Exception e){}
}
}
}
thread.start();
for(int i = 0 ; i < 5 ; i++){
System.out.println("beep");
try{Thread.sleep(500);} catch(Exception e){}
}
}스레드 이름
메인 스레드 이름은 main, 작업스레드의 이름은 Thread-n
thread.getName() : 스레드 이름 얻기
thread.setName("threadName"); : 작업 스레드 이름 변경
Thread thread = Thread.currentThread(); : 코드 실행하는 스레드의 참조 얻기
3. 스레드 우선 순위
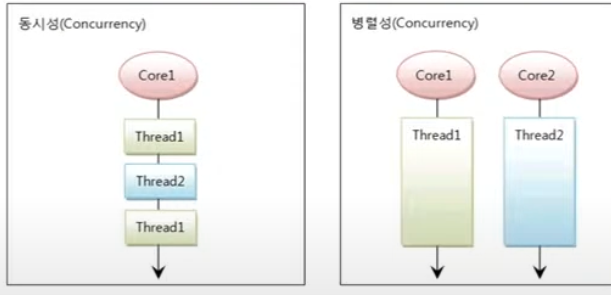
동시성(Concurrency)
멀티 작업을 위해 하나의 코어에서 멀티 스레드가 번갈아가며 실행하는 성질
병렬성(Parrallelism)
멀티 작업을 위해 멀티 코어에서 개별 스레드를 동시에 실행하는 성질
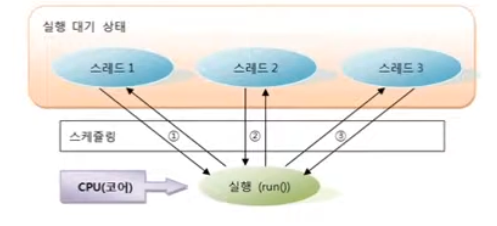
스레드 스케쥴링
스레드의 개수가 코어의 수보다 많을 경우 어떤 순서로 스레드를 동시성으로 실행할 지 결정하는 것
스레드 스케쥴링에 의해 스레드들은 번갈아 가면서 run() 메소드를 조금씩 실행함
자바의 스레드 스케쥴링
우선순위 스케쥴링
우선 순위가 높은 스레드가 실행상태를 더 많이 가지도록 스케쥴링
순환 할당(Round-Robin)
시간 할당량(Time Slice)을 정해서 하나의 스레드를 정해진 시간만큼 실행
스레드 우선 순위
스레드들이 동시성을 가질 경우 우선적으로 실행할 수 있는 순위로 1(낮음)에서부터 10(높음)까지 부여함
단, 모든 스레드들은 기본적으로 5의 우선 순위를 할당하며 thread.setPriority()를 통해 우선 순위를 변경함
우선순위 변수
Thread.MAX_PRIORITY,Thread.NORM_PRIORITY,THREAD.MIN_PRIORITY
우선순위 효과
싱글코어
우선 순위가 높은 스레드가 실행기회를 더 많이 가지기 때문에 더 빨리 계산 작업을 끝냄
멀티코어
쿼드 코어의 경우 4개의 스레드가 병렬성으로 실행될 수 있기 때문에 4개 이하의 스레드를 실행할 경우에는 우선 순위의 영향이 크지 않고, 5개 이상의 스레드가 실행될 경우 우선순위 영향을 받음
4. 동기화 메소드와 동기화 블록
공유 객체 사용할 때 주의할 점
멀티 스레드가 하나의 객체를 공유하기 때문에 발생하는 오류가 있음
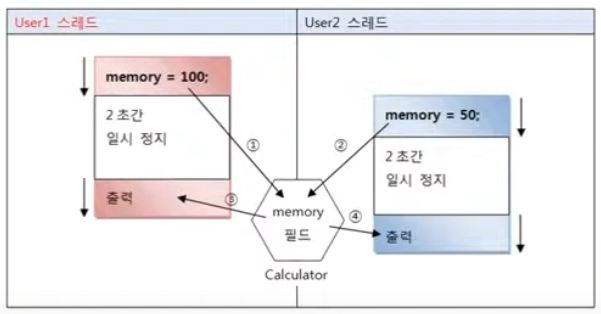
공유 객체에 서로 값을 쓰려는 경우 각 스레드에서 사용하던 값이 유지되지 않을 수 있음
3의 단계에서 50이 출력되는 문제
동기화 메소드 및 블록 (Synchronized)
단 하나의 스레드만 실행할 수 있는 메소드 또는 블록으로 다른 스레드는 메소드나 블록의 실행이 끝날 때까지 대기해야함
//동기화 메소드
pulbic synchronized void method(){
임계영역
}
//동기화 블록
public void method(){
//여러 스레드 실행 가능 영역
synchronized(공유객체){
임계영역 //단 하나의 스레드만
}
//여러 스레드 실행 가능 영역
}Example
public class Calculator{
private int memory;
public int getMemory(){
return memory;
}
public synchronized void setMemory(int memory){
this.memory = memory;
try{
Thread.sleep(2000);
}catch(InterruptException e){}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
}
}5. 스레드 상태
스레드 상태
객체 생성
NEW
스레드 객체가 생성되고 아직 start() 메소드가 호출되지 않은 상태
실행 대기
RUNNABLE
실행 상태로 언제든지 갈 수 있는 상테
일시정지
BLOCKED
사용코자하는 객체의 lock이 풀릴 때까지 기다리는 상태
WAITING
다른 스레드가 통지할 때까지 기다리는 상태
TIMED_WAITING
주어진 시간동안 기다리는 상태
종료
TERMINATED
실행을 마친 상태
6. 스레드 상태 제어
상태 제어
실행 중인 스레드의 상태를 변경하는 것을 ㅗ상태 변화를 가져오는 메소드의 종류
일시정지 to 실행대기
interrupt(), notify(), notifyAll()
실행 to 실행 대기
yield()
실행 to 일시정지
sleep(), join, wait()
sleep()
주어진 시간 동안 일시정지하여 얼마동안 정지상태로 있을 지 1/1000 단위로 지정할 수 있고, 일시 정지 상태에서 interrupt() 메소드가 호출되면 InterruptException 발생함
yield()
다른 스레드에게 실행을 양보하게 됨
join()
다른 스레드의 종료를 기다리게 하여 계산 작업을 하는 스레드가 모든 계산 작업을 마쳤을 때 결과값을 받아 이용하는 경우에 사용됨
스레드 간 협업(waii, notify, notifyAll)
동기화 메소드 또는 블록에서만 호출 가능한 object 메소드로 두 개의 스레드가 교대로 번갈아가며 실행해야할 경우 주로 사용됨
wait()
호출한 스레드는 일시 정지되며 다른 스레드가 notify(), notifyAll() 호출하면 실행 대기 상태가 됨
wait(long timeout), wait(long timeout, int nanos)
notify() 호출되지 않아도 시간 지나면 스레드가 자동적으로 실행 대기 상태 됨
스레드의 안전한 종료 (stop flag, interrupt())
경우에 따라서는 실행 중인 스레드를 즉시 종료할 필요가 있ek.
stop() 메소드의 경우 스레드를 갑자기 종료하게 되면 사용 중이던 자원들이 불안전한 상태로 남겨지기 때문에 deprecated되고, stop flag를 이용하여 메소드의 정상 종료를 유도
public class XXXThread extends Thread{
private boolean stop;
public void run(){
while(!stop){
//스레드 반복 실행 코드
}
// 스레드 사용 자원 정리
}
}interrupt()
일시 정지 상태일 경우 InterruptedException 발생시키지만 실행대기, 실행상태에서는 InterruptedException 발생하지 않음
일시 정지 상태 만들지 않고 while문 나오는 방법
boolean status = Thread.interrupted();
boolean status = objThread.isInterrupted();7. 데몬 스레드
주 스레드의 작업을 돕는 보조적인 역할을 수행하는 스레드로, 주 스레드가 종료되면 데몬 스레드는 강제적으로 자동 종료되는 것
예시로는 워드프로세서의 자동 저장, 미디어 플레이어의 동영상 및 음악 재생, 가비지 컬렉터 등이 있음
데몬 스레드 설정
public static void main(String[] args){
AutoSaveThread thread = new AutoSaveThread();
thread.setDaemon(true);
thread.start();
}주 스레드가 데몬이 될 스레드의 setDaemon(true)를 호출하여 데몬 스레드 설정하며, start() 선언 전에 호출해야함
8. 스레드 그룹
관련된 스레드를 묶어서 관리할 목적으로 이용하며 계층적으로 하위 스레드 그룹을 가질 수 있음
자동 생성되는 스레드 그룹
- System 그룹 : JVM 운영에 필요한 스레드들을 포함
- System/main 그룹 : 메인 스레드를 포함
스레드는 반드시 하나의 스레드 그룹에 포함되며 기본적으로 자신을 생성한 스레드와 같은 스레드 그룹에 속하게 되며 명시적으로 스레드 그룹에 포함시키지 않으면 기본적으로 system/main 그룹에 속하게 됨
스레드 그룹 이름 얻기
ThreadGroup group = Thread.currentThread.getThreadGroup();
String groupName = group.getName();스레드 그룹 생성
ThreadGroup tg = new ThreadGroup(String name);
ThreadGroup tf = new ThreadGroup(ThreadGroup parent, String name);부모 그룹을 지정하지 않으면 현재 스레드가 속한 그룹의 하위 그룹으로 생성되며, 스레드를 그룹에 명시적으로 포함시키는 방법은 다음과 같다
Thread t = new Thread(ThreadGroup group, Runnable target);
Thread t = new Thread(ThreadGroup group, Runnable target, String name);
Thread t = new Thread(ThreadGroup group, Runnable target, String name, long stackSize);
Thread t = new Thread(ThreadGroup group, String name);스레드 그룹의 일괄 Interrupt()
스레드 그룹의 interrupt() 호출하게 되면 소속된 모든 스레드의 interrupt()가 호출됨
9. 스레드 풀(ExecutorService)
스레드 폭증
병렬 작업 처리가 많아지면 스레드의 개수가 증가하고, 스레드 생성과 스케쥴링으로 인한 CPU, 메모리 사용량 증가하여 애플리케이션의 성능 급격한 저하 발생
스레드 풀(Thread Pool)
작업 처리에 사용되는 스레드를 제한된 개수만큼 미리 생성하여 작업 큐에 들어오는 작업들을 하나씩 스레드가 맡아 처리하고, 작업 처리가 끝난 스레드는 작업 결과를 애플리케이션으로 전달함으로써 스레드는 다시 작업큐에서 새로운 작업을 가져오는 구조
ExecutorService 인터페이스와 Executors 클래스
스레드 풀을 생성하고 사용할 수 있도록 java.util.concurrent 패키지에서 제공하는 것으로 Executors의 정적 메소드를 이용해 ExecutorSerivce 구현 객체를 생성함
Thread Pool = ExecutorService 객체
ExecutorService 동작 원리
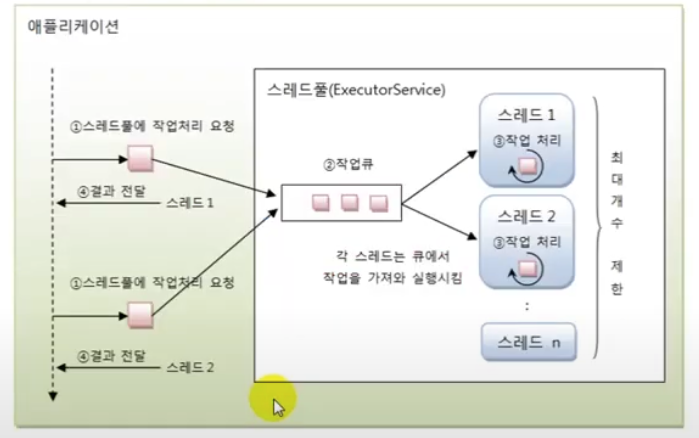
Thread Pool 생성
- newCachedThreadPool()
초기 스레드 수 0, 코어 스레드 수 0, 최대 스레드 수 Integer.MAX_VALUE
운영 체제의 상황에 따라 최대 스레드 수 달라질 수 있으며 1개 이상의 스레드가 추가되었을 때 60초동안 추가된 스레드가 아무 작업을 하지 않으면 추가된 스레드를 종료하고 pool에서 제거
- newFixedThreadPool(int nThreads)
초기 스레드 수 0, 코어 스레드 수 nThreads, 최대 스레드 수 nThreads
스레드가 작업을 처리하지 않고 놀고 있더라도 스레드의 개수가 줄지 않음 - ThreadPoolExecutor 이용한 직접 생성
내부적으로 newCachedThreadPool(), newFixedThreadPool(int nThreads)가 생성되며 스레드의 수를 자동으로 관리하고 싶은 경우에 직접 생성하여 사용함
ExecutorService threadPool = new ThreadPoolExecutor(
3, // 코어 스레드 개수
100, // 최대 스레드 개수
120L, //놀고 있는 시간
TimeUnit.SECONDS, //놀고 있는 시간 단위
new SynchronousQueue<Runnable> //작업큐
);스레드풀 종료
스레드 풀의 스레드는 기본적으로 데몬 스레드가 아니므로 main 스레드가 종료되더라도 스레드풀의 스레드들은 작업을 처리하기 위해 계속 실행되는 중임
따라서 스레드풀을 종료해서 모든 스레드를 종료시켜야 함
void shutdown()
현재 처리중인 작업 뿐만 아니라 작업큐에 대기하고 있는 모든 작업을 처리한 뒤에 스레드 풀을 종료List<Runnable> shutdownNow()
현재 작업 처리 중인 스레드를 interrupt해서 직접 중지를 시도하고 스레트풀을 종료시키며, 리턴값은 작업 큐에 있는 미처리된 작업의 목록awaitTermination(long timeout, TimeUnit unit)
shutdown() 메소드 호출 이후, 모든 작업 처리를 timeout 시간 내에 완료하면 true, 완료하지 못하면 작업 처리 중인 스레드를 interrupt 하고 false를 리턴
작업 생성
하나의 작업은 Runnable, Callable 객체로 표현하며 두 객체의 차이점은 작업 처리 완료 이후 리턴값의 유무이다
Runnable task = new Runnable(){
@Override
public void run(){
}
}
Callable<T> task = new Callable<T>{
@Override
public T call() throws Exception{
return T;
}
}스레드 풀에서 작업 처리
작업 큐에서 Runnable/Callable 객체를 가져와 스레드로 하여금 run()과 call() 메소드를 실행토록 하는 것
작업 처리 요청
ExecutorSerivce 의 작업 큐에 Runnable/Callable 객체를 넣는 행위로 작업 처리 요청을 위해 ExecutorService는 execute(Runnable command),Future<?> submit(Runnable task), Future<V> submit(Runnable task, V result), Future<V> submit(Callable<V> task)를 제공함
execute() : Runnable 을 작업큐에 저장하여 작업 처리 결과를 받지 못하여 예외가 발생할 경우 해당 스레드 종료되며 제거되고, 스레드 풀은 다른 작업 처리를 위해 새로운 스레드를 생성함
submit() : Runnable / Callable 을 작업 큐에 저장해 리턴된 Future를 통해 작업 처리 결과 얻을 수 있으며 스레드가 종료되지 않고 다음 작업을 위해 재사용됨
Future
작업 결과가 아닌 지연 완료 객체로 작업이 완료될 때까지 기다렸다가 최종 결과를 얻기 위해 get() 메소드를 사용함
Future.get()은 UI 스레드에서 호출하게 되면 작업 완료 전까지 UI 변경 및 이벤트 처리가 불가능하므로 호출해서는 안됨
다른 메소드
boolean cancel(boolean mayInterruptIfRunning)
작업 처리가 진행 중일 경우 취소
boolean isCancelled()
작업이 취소되었는지 여부
boolean isDone()
작업 처리 완료되었는지 여부
작업 완료순 통보 받기
작업 요청 순서대로 작업 처리가 완료되는 것이 아니기 때문에 작업 처리가 완료되는 것부터 결과는 얻어 이용하는 것이 좋음 (여러 작업 순차적 처리 필요 없고, 처리 결과도 순차적 이용 필요 없는 경우에 한해)
처리 완료된 것만 통보 받는 방법
CompletionService는 처리 완료된 작업만 가져오는 메소드 poll(),take() 제공
Future<V> poll()
완료된 작업의 Future 가져오며 완료된 작업이 없는 경우엔 null 리턴Future<V> poll(long timeout, TimeUnit unit)
완료된 작업의 Future 가져오며 완료된 작업이 없다면 Timeout까지 블로킹Future<V> take()
완료된 작업의 Future를 가져오며 완료된 작업이 있다면 생길때까지 블로킹Future<V> submit(Callable<V> task)
스레드 풀에 Callable 작업 처리 요청Future<V> submit(Runnable task, V result)
스레드 풀에 Runnable 작업 처리 요청
작업 처리 요청 방법
poll(), take() 이용해 처리 완료된 작업의 Future 얻으려면 CompletionService의 submit() 메소드로 작업 처리 요청 해야함
ExecutorSerivce executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors()
);
CompletionService<V> completionService = new ExecutorCompletionService<V>(executorService);
completionService.submit(Callable<V> task);
completionService.submit(Runnable task, V result);완료된 작업 통보받기
executorSerivce.submit(new Runnable(){
@Override
public void run(){
while(true){
try{
Future<Integer> future = completionService.take();
int value = future.get();
System.out.println("result : " + value);
}catch (Exception e){
break;
}
}
}
});take() 메소드 반복 실행해서 완료된 작업을 계속 통보받을 수 있도록 함
콜백 방식의 작업 완료 통보 받기
콜백
애플리케이션이 스레드에게 작업 처리 요청한 후 다른 기능 수행할 동안 스레드가 작업 완료한 경우 애플리케이션의 메소드를 자동 실행하는 기법으로 자동 실행되는 메소드를 콜백 메소드 라고 함
작업 완료 통보 : 블로킹 vs 콜백
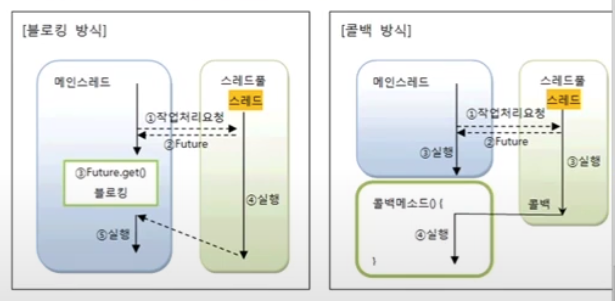
콜백 객체와 콜백
콜백 객체
CompletionHandler<V, A> callback = new CompletionHandler<V, A>(){
@Override
public void completed(V result, A attachment){
}
@Override
public void failed(Throwable exc, A attachment){
}
};콜백 메소드를 가지고 있는 객체
콜백
Runnable task = new Runnable(){
@Override
public void run(){
try{
V result = ...;
callback.completed(result, null);
} catch(Exception e){
callback.failed(e, null);
}
}
};