Image as Set of Points (ICLR, 2023)
논문링크
연구목적
- 최근의 vision models의 발전은 CNN, ViT 혹은 CNN + ViT 구조에 집중되어 있음
- 하지만, 이외에도 순수 MLP 기반의 모델이나 graph 기반의 모델도 제안되고 있으며 새로운 insight를 제공하고 있음
- 따라서, 본 논문에서도 visual representation을 학습하기 위해 매우 클래식한 알고리즘인 clustering에 집중하고자 함
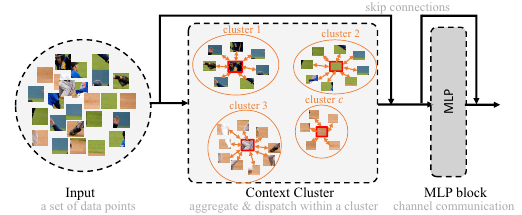
- 즉, 하나의 이미지를 여러 data points의 집합으로 보고 모든 points가 적절한 cluster로 그룹화함 (Context Cluster, CoC)
- 하나의 픽셀을 5차원의 data point로 생각: RGB값 + 위치값(x,y)
- 다시 말해 이미지를 point clouds의 집합으로 변환하여 point cloud 분야에서 제안된 방법을 적용하여 visual representation을 학습함
- CoC는 CNN, ViT와 차별화되지만 이들의 좋은 특징들을 일부 공유함
- CoC는 RGBD images, point clouds와 같은 다른 data domain에 잘 일반화될 수 있으며 각 레이어마다 clustering 결과를 확인할 수 있으므로 레이어 별로 어떤 특징들을 학습하고 있는지 쉽게 확인할 수 있음
접근법
- 입력 이미지의 모든 픽셀을 RGB값, position값의 5차원 데이터로 구성
- 모델의 아키텍처는 여러 context cluster blocks을 stack하여 구성
- Points가 주어지면 연산량을 줄이기 위해 points를 수를 줄임
- 인접한 k개의 points를 concat하여 linear projection함
- 최종 분류를 위해 last block의 모든 points를 평균하여 FC layer에 입력함
- Context cluster blocks에서는 context clustering을 수행
- c개의 (고정된)cluster centers를 정의: SuperPixel 방법인 SLIC을 통해 공간상에 c개의 중심을 균등하게 배치하고 k개의 인접 points를 평균하여 center feature 설정
- Projected된 points와 cluster centers와의 cosine similarity를 계산하여 모든 points를 가장 유사한 center로 배정함
- 이후 한 cluster의 모든 points를 center point와의 유사도를 기준으로 집계함
- 집계된 feature를 기준으로 각 points를 업데이트함
실험결과
- 제안하는 CoCs를 mage classification, point cloud classification, object detection, instance segmentation, semantic segmentation tasks에서 검증함
- SOTA 성능을 목표로 하지 않았지만 몇몇 벤치마크에서 CNN, ViT와 매우 비슷하거나 능가하는 성능을 보여줌
의견
