- Principles of network
- Web & HTTP
- E-mail, SMTP, IMAP
- DNS
- P2P applications
- Video streaming and CDNs
- Socket programming with UDP & TCP
Principles of network
네트워크 어플리케이션들은 end system 위에서 동작하며, network-core 장치들을 위해 소프트웨어가 필요하지 않다. 이때, end system 중 무엇과 통신을 수행하는지에 따라 대표적인 두 가지 체제가 존재한다.
- client-server paradigm
- peer-to-peer paradigm
Client-Server paradigm
-
Server
- Client로부터 언제 통신이 올지 알 수 없어 항상 켜져있다.- 영구적인 IP address를 가져, 쉽게 찾을 수 있다.
- 종종 data center에 존재한다.
-
Client
- Dynamic IP address를 가지고 있다.- Client간에는 직접적으로 통신하지 않는다.
Client와 server는 소프퉤어적으로 분리되며, client-server paradigm을 따르는 방식으로 HTTP, IMAP, FTP 등이 있다.
Peer-to-Peer structure (P2P)
- P2P 통신에선 서버가 항상 켜져 있지 않다.
- 임의의 end system들이 직접적으로 통신할 수 있다.
- peer는 다른 peer로부터 서비스를 요청할 수 있으며, 서비스를 반환값으로 전해줄 수 있다.
- 이를 self scalability를 가진다고 표현한다. (새로운 서비스를 필요로 할 때, 새로운 peer에게 그 서비스 용량을 할당시킬 수 있다는 것. 즉 특정 작업의 부하를 다른 peer에게 분배함으로써 비용에 매우 효율적인 구조이다.) - peer는 서로 상호 연결되어 있으며, IP address가 바뀔 수 있다.
- 따라서 복잡한 관리 체계가 요구된다.
P2P 통신의 대표적인 예제가 바로 P2P sharing 방식을 따르는 토렌트 등이 있다. P2P 구조에서는 각 host가 스스로 server process이자 client process로 동작하는 것으로 이해하면 된다.
Processes communicating
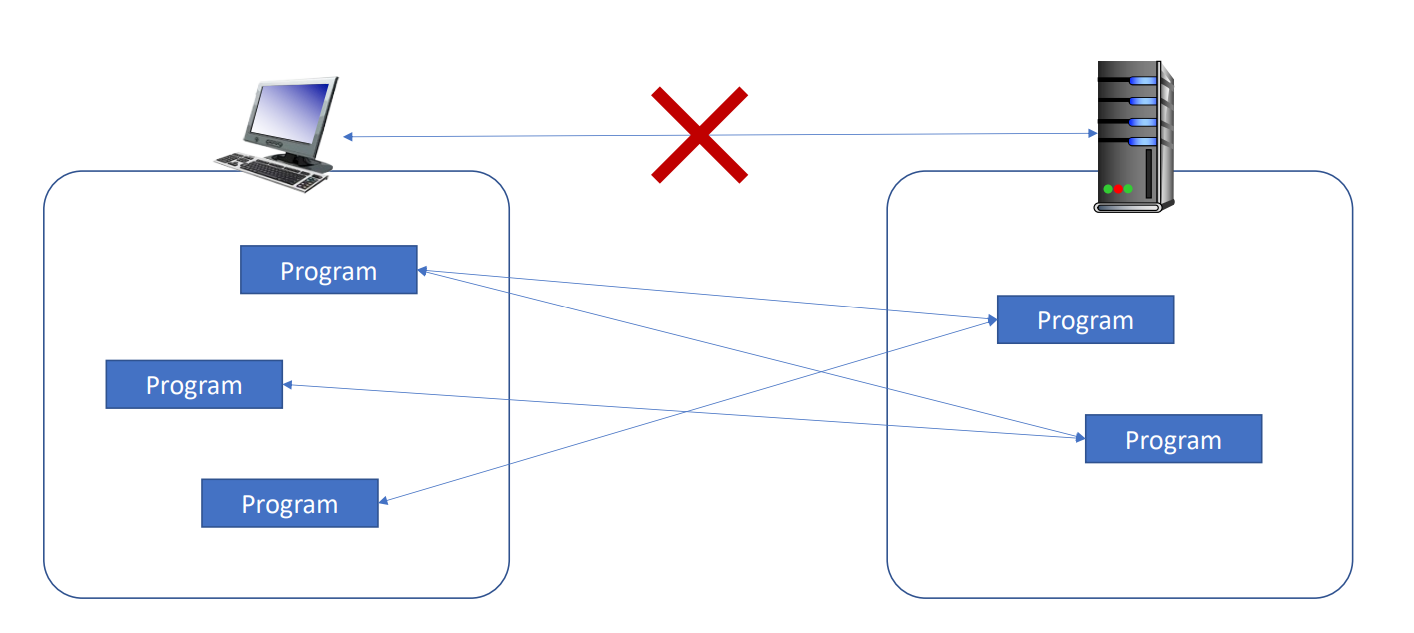
Host 간에 통신이 이루어질 때 중요한 점은 process가 주체가 되어 일어난다는 것이다. 즉, 하나의 기기가 한 번에 하나의 통신만 가능한 것이 아니라, 기기가 가지고 있는 프로그램의 수에 맞춰 각각 개별적으로 통신이 수행된다는 것이다.
- process : host에서 실행하고 있는 program
- 같은 host에 존재하는 process간에는 OS에 의해 정의되는 inter-process communication을 통해 연결하게 된다.
- 다른 host에 존재하는 process간에는 message를 교환하며 연결하게된다.
Client process는 연결을 시작하는 process를, server process는 연결이 오기를 기다리는 process로 구분하면 된다.
Socket
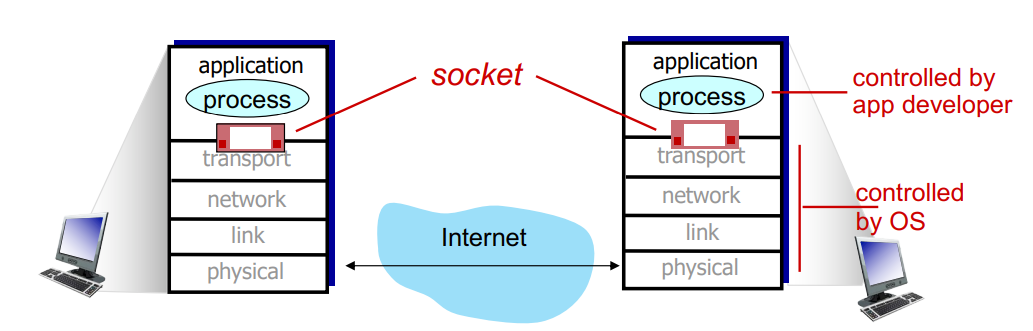
Socket이라는 개념은 process가 메세지를 주고 받는 과정에서 사용하는 인터페이스를 지칭한다. Socket은 application layer와 transport layer 사이에 메세지가 전달될 때 지나가게 된다. Application layer는 앱 개발자에 의해 결정되지만, 나머지 layer는 OS에 의해 결정되기 때문에 socket API 또한 OS에 따라 다르게 존재한다.
Addressing proccesses
Process에서 message를 수신하기 위해선, identifier가 필요하다. Identifier는 IP address와 port number로 이루어지며, Host 장치마다 unique한 32-bit의 IP address를 가지게 된다. 그러나, 하나의 host에서도 여러 process가 실행될 수 있기 때문에 port를 이용해서 구분하게 된다.
- default port number
- HTTP server : 80
- HTTPS server : 443
- mail server : 25
- ssh : 22
예를 들어, IPv4 address값을 분석해보자. Host가 고유하게 141.223.65.44의 값을 가지게 되고, 사용하고자 하는 서비스에 따라 80, 22, 25 등의 port number를 조합하게 된다. Web page의 경우 HTTP protocol을 따르니 port 80을 이용하면 된다.
+) 추가로, port number는 user가 임의로 사용할 수 없는 0 ~ 1023, 1024 ~ 49151 범위와 dynamic하게 사용할 수 있는 49152 ~ 65535의 port가 있다.
Application-layer protocol defines
- 교환되는 메세지 종류 ( request, response )
- 메세지 syntax ( 메세지 내부 field 서술법 )
- 메세지 semantic ( 각 field 의미 )
- process의 메세지 전송, 수신 rule
- open protocol - RFC에 의해 정의되며 모두가 접근할 수 있는 interoperability를 위해 있는 것 ( HTTP, SMTP )
- proprietary protocol ( Skype, Kakaotalk )
App이 필요로하는 transport service
- data integrity
- File transfer, email 등의 몇몇 앱은 100% 신뢰할 수 있는 데이터 전송과정을 요구
- 다른 앱은 데이터 일부가 소실되어도 됨 - timing
- 인터넷 전화, 상호작용 게임등은 낮은 딜레이를 요구함 - throughput
- multimedia같은 앱은 throughput이 최소가 되길 요구함
- 그 외의 탄성적인 앱들은 throughput에 영향 안받음 - security
- encryption, data integrity 등
Internet transport protocol services
앞서 application layer에서 HTTP, SMTP 등의 protocol을 사용함을 봤고, 이젠 transport layer에서 사용하는 protocol에 대해 알아보자.
TCP service
- reliable transport
- flow control을 통해 sender가 receiver가 수용 가능한 양을 넘치지 않게 한다.
- congestion control : 네트워크가 과부하 상태일 때 sender를 억압시킨다.
- timing, minimum throughput guarantee, security 등을 제공하지 않는다.
- connection-oriented : client & server process 사이에 setup 요구(이로 인해 비용, delay 증가)
UDP service
- unreliable transport
- reliability, flow control, congestion control, timing throughput guarantee, security, connection setup을 모두 지원하지 않는다.
- 그럼에도 빠르다는 장점이 있다.
Securing TCP
- Vanilla TCP & UDP socket
- encryption이 없으며, 이로 인해 비밀번호가 socket을 통해 인터넷 상에 그대로 돌아다니게 된다. - Transport Layer Security (TLS)
- encrypted TCP connection을 지원한다.
- data integrity
- end-point authentication - TLS는 application layer에 구현되어있으며, app들이 TLS 라이브러리를 사용하고, TLS socket API를 통해 encryption을 수행한다.
Web & HTTP
Web page는 여러 object들의 모음으로, 각각의 object는 서로 다른 Web server 상에 저장될 수 있다. Object는 HTML file, JPEG 이미지, Java applet, audio file등이 될 수 있다. Web page는 base HTML-file에 여러 개의 referenced object로 구성되며, 각각은 URL로 접근할 수 있다.
http://tomahawk.postech.ac.kr/csed353/static/bg.jpg
예를 들어 위 URL을 보면 http라는 protocol을 이용해 tomahawk.postech.ac.kr이라는 host name을 가지는 웹 서버에서 기본 port인 80으로 접근하고, csed353/static/bg.jpg라는 경로로 접근한 것이다.
HTTP overview
HTTP : hypertext transport protocol
HTTP는 웹의 application layer protocol으로, client server model을 따른다.
- Client : HTTP protocol을 이용해 web object를 요청 후 받아 전시하는 browser
- Server : HTTP protocol을 이용해 요청된 object들을 전송하는 web server
HTTP uses TCP
- Client가 TCP connection을 initiate해 socket을 만들고 server에 port 80으로 연결한다.
- Server는 client에서 요청된 TCP connection을 수락한다.
- HTTP message(application-layer protocol message)는 browser( HTTP client)와 web server(HTTP server) 사이에서 교환된다.
- TCP connection이 close된다.
HTTP is stateless
- server는 과거에 있었던 client request들에 대한 정보를 따로 저장하지 않는다. 즉, 이전에 수행되었던 행동들에 영향을 받을 수 없어 stateless라 표현한다.
+) state를 가진 protocol은 매우 복잡하다. 과거 history도 저장해야하고, server/client가 붕괴될 때 그들의 state에 추가적인 작업이 필요하기 때문.
HTTP connections : two type
Non-persistent HTTP (HTTP 1.0)
- TCP connection이 열린다.
- 최대 1개의 objefct가 전달된다.
- TCP connection이 닫힌다.
(즉, non persistent의 경우 connection이 1개의 object를 전송한 후 자동 종료되므로, 여러 개의 object를 보내기 위해선 여러 번 connection이 요구된다.)
Persistent HTTP (HTTP 1.1)
- TCP connection이 열린다.
- 여러 개의 object가 하나의 tcp connection을 통해 전달된다.
- TCP connection이 닫힌다.
Non-persistent HTTP : example


User 입장에서 URL을 입력한 행위는 HTTP 상에서 위와 같은 과정을 거친다. 총 10개의 object가 있어 1 ~ 5단계를 반복한다고 명시된 점이 특징이다.
Non-persistent HTTP : response time
- RTT : Client에서 server로 작은 packet이 왕복하는데 걸리는 시간
- HTTP response time (per object)
- TCP connection에 1RTT
- HTTP request와 초기 몇 바이트 반환에 1RTT
- object/file 자체의 transmission time
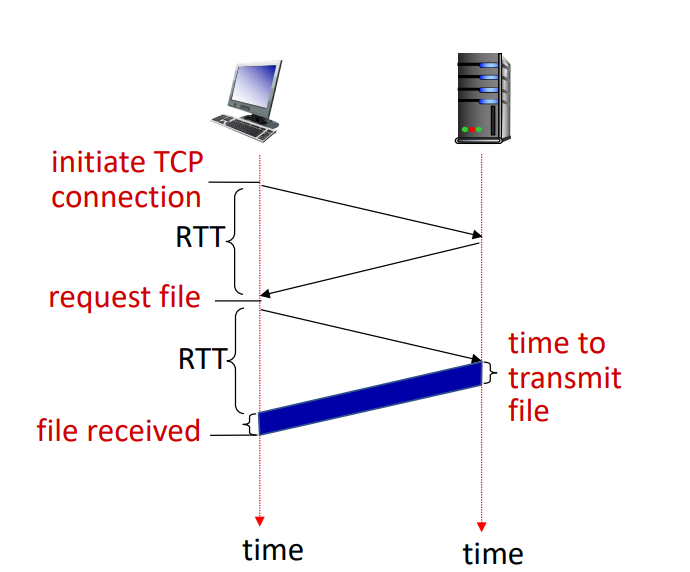
즉, Non-persistent HTTP response time = 2RTT + file transmission time 이다.
Persistent HTTP
Non-persistent HTTP의 문제점
- Object 1개당 2RTT가 요구된다. (너무 많은 시간)
- OS는 각 TCP connection에 overhead가 발생한다.
- browser는 종종 multiple parallel TCP connection을 열어서 parallel 상태의 referenced object를 접근하려고 한다.
Persistent HTTP
- 서버가 응답을 보낸 이후에도 connection을 계속 유지한다.
- 그래서 같은 client-server 사이에서 뒤이어서 보내지는 message들도 같은 connection 상에 전송된다.
- client는 referenced object를 만나자마자 request를 발송하게 된다.
- 1개의 referenced object당 최소 1 RTT의 시간이 소요된다. (non persistent 경우의 절반에 해당하는 response time)
HTTP 1.0 req vs HTTP 1.1 req
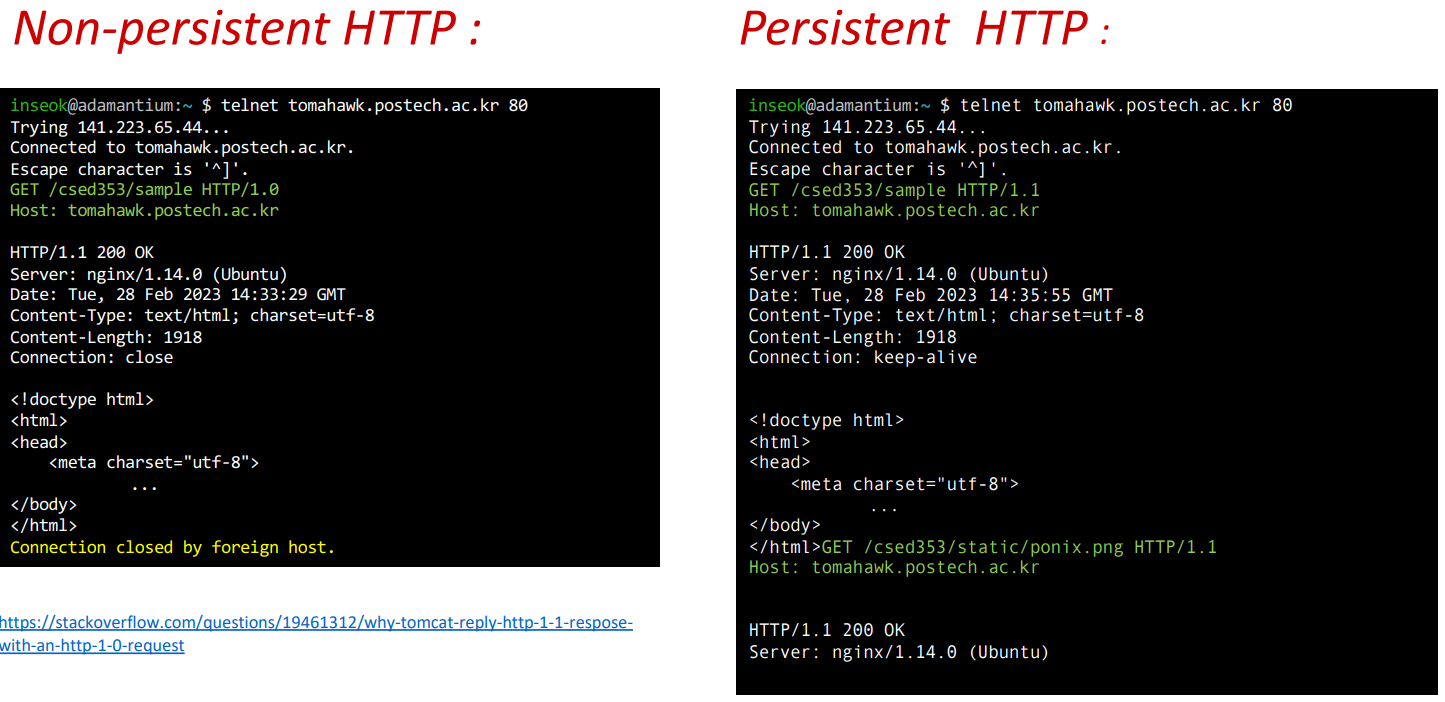
Non-persistent HTTP의 경우 client 측에서 http 1.0을 사용하는 것을 볼 수 있다. 그리고 connection:close가 자동으로 이루어지는 걸 확인할 수 있다. 이때, Server 측에서 HTTP/1.1을 보여준 것은 server가 이를 사용했다는 것이 아니라, 1.1까지 사용할 수 있음을 보여주는 것이다. (Server의 capacity를 명시)
Persistent HTTP의 경우 client 측에서 http 1.1을 사용하는 것을 볼 수 있다. 그리고 connection:keep-alive에 이어 마지막에 client의 입력을 기다리고 있음을 확인할 수 있다. 만약 종료를 원한다면 client 측에서 Connection:close를 입력해야 한다.
HTTP request message
HTTP message는 두 종류가 있다. (Request, Response)
HTTP request message는 ASCII(human-readable format)으로 구성된다.
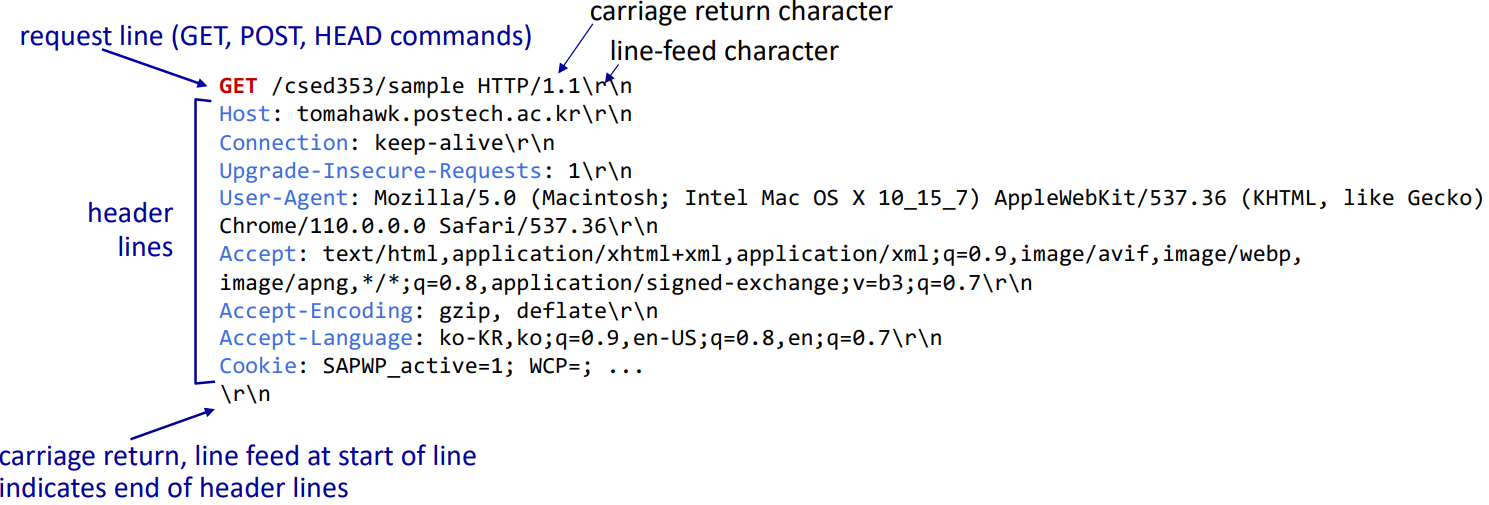
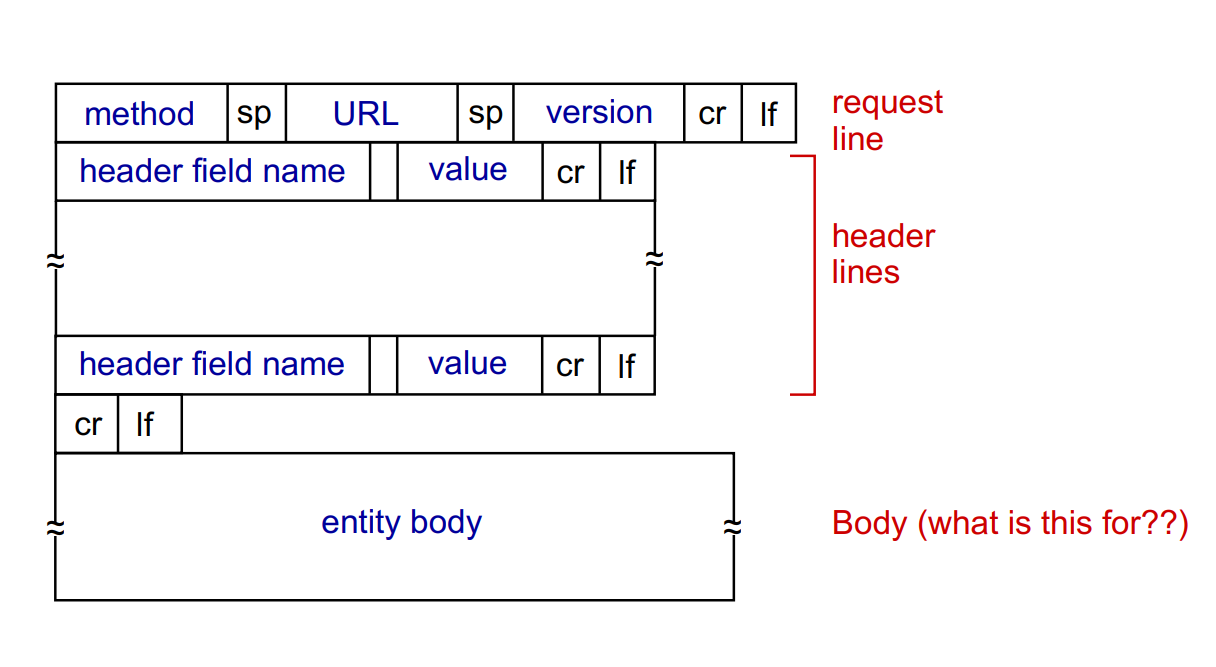
이때 보면 각 line은 carriage return(cr), line feed(lf)을 통해 공통적으로 line을 구별하고 있음을 볼 수 있다. header line이 끝났다면 cr,lf를 한 번 더 적어줘야 한다. GET command의 경우 header line 부분까지 사용하나, POST command의 경우 우리가 작성하고자 하는 내용을 보내줘야 하기 때문에 entity body가 요구된다.
여러가지 HTTP request message
POST method
- Client에서 server로 POST 메서드의 entity body에 user input을 담아 전송한다.
GET method
- GET 메서드는 URL field에 user data를 ? 뒤에 포함시켜 전송한다.
- www.somesite.com/animalsearch?monkeys&banana
HEAD method
- 특정 리소스를 GET 메서드로 요청했을 때 돌아올 header를 요청한다.
PUT method
- 새로운 file(object)을 server에 업로드 한다.
- POST 메소드의 entity body에 특정한 url로 명시된 content를 file로 대체한다.
+) 직관적 이해 : post (생성) put (수정)
HTTP response message

HTTP response status code
HTTP response message의 가장 첫 줄에 나타나는 status code는 범위에 따라 의미하는 값이 다르다.
- 200 family - 200 OK
- request가 성공하였으며 reuqest된 object가 이 메세지의 뒷부분에 포함되어 나온다. - 300 family - 301 Moved Permanently
- request된 object가 이동하엿으며, 이 메세지에 이동된 새로운 위치가 명시된다. (보통 browser가 자동으로 이 새로운 위치를 다시 찾는다) - 400 family - 400 Bad Request / 404 Not Found
- 400 : request된 메세지를 서버에서 이해하지 못함
- 404 : request된 document를 서버에서 찾을 수 없음 - 500 family - 505 HTTP Version Not Supported
HTTP 통신 직접 해보기
- telnet tomahawk.postech.ac.kr 80
- TCP connection을 tomahawk.postech.ac.kr에 port 80으로 연다.
- 이 뒤로 타이핑되는 것이 해당 서버로 전해진다.
- GET /csed353/sample HTTP/1.1
Host: tomahawk.postech.ac.kr - 위 request 이후에 전해지는 response message (Wireshark로 단계별 request/response를 capture할 수 있음)
Maintaining user/server state: Cookies
앞서 HTTP의 GET/response 상호작용이 stateless였다는 점을 떠올려보자. 이로 인해 HTTP 메세지가 Web transaction을 완료하기 위한 여러 단계들의 교환을 수행해도 어떠한 표기가 없다.
- Client와 server가 이런 여러 단계의 교환과정의 state를 tracking할 필요가 없다.
- HTTP request는 모두 서로 독립적이다.
- 부분적으로는 완료되었으나 완전히 끝나지 못한 transaction에 대해 recover할 필요가 없다.
+) transaction : multiple set of request, response
그러나 post와 같이 서버의 내용을 수정하는 과정에서 문제가 생길 경우엔 rollback하는 과정이 필요한데, 현재 HTTP 자체로는 이것이 불가능하다. 이런 statless한 protocol에 statefulness를 제공하고자 할 때 우린 cookie를 사용하게 된다.
웹사이트에 접속했을 때 사용자 동의에 따라 쿠키를 수집하는 것을 종종 봤을텐데, 이를 이용해 client browser가 transaction들 사이의 state를 maintain할 수 있게 된다.
Cookie four components
- cookie header line of HTTP response message
- cookie header line in next HTTP request message
- cookie fle kept on user's host, managed by user's browser
- back-end database at Web site
예를 들어, susan이 노트북으로 browser를 사용해 특정한 이커머스 사이트에 처음 접속한 상황이다. 이때 첫 HTTP request가 사이트에 도착하면, 사이트는 유일한 ID(즉, cookie)와 ID에 해당하는 백엔드 데이터베이스를 만들게 된다. 그 후로 이어지는 해당 사이트로의 HTTP request는 cookie ID 값을 포함하여 사이트 측에서 susan의 요청임을 구분할 수 있게 된다.
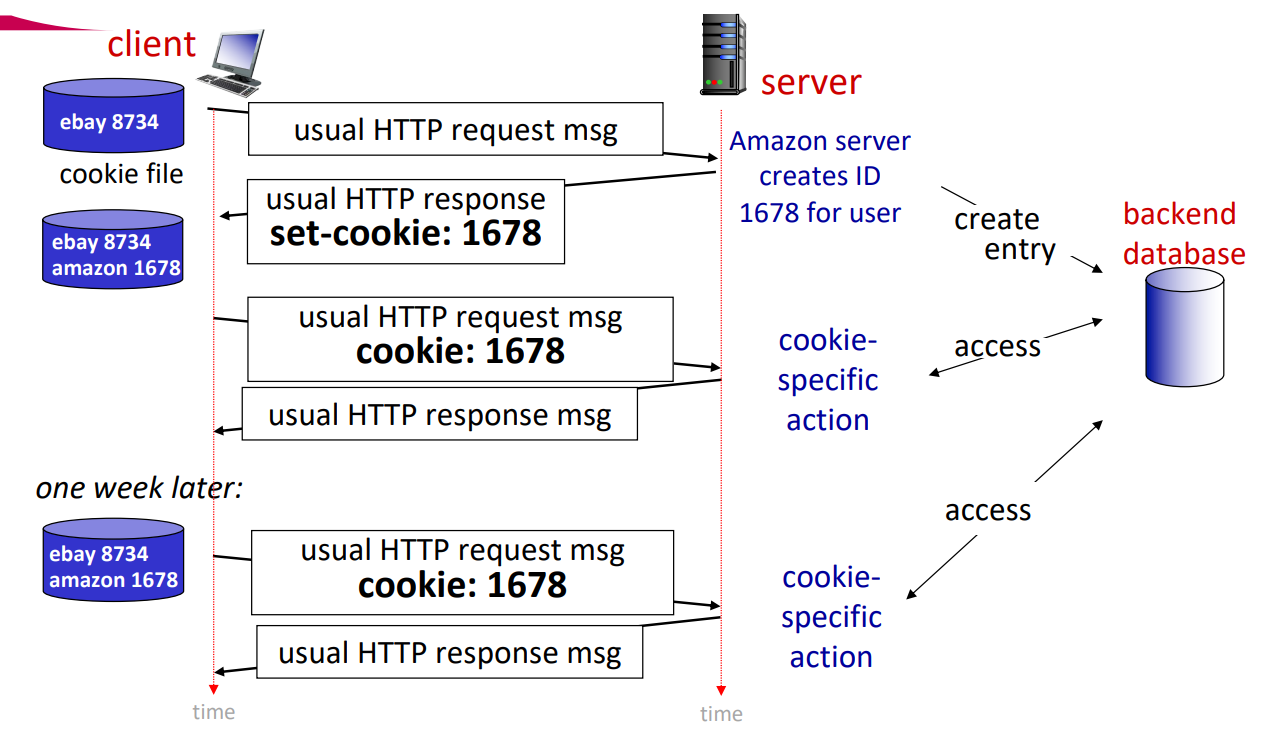
위 그림을 보면 아마존 사이트에 처음 접속하였고, 첫 request의 response에서 "set-cookie"를 받게 된다. 그 후에 요청을 할 때 헤더에 cookie값을 포함해서 보내게 되고, cookie 값을 이용해 server의 백엔드 데이터베이스에 기록을 남기게 된다.
HTTP cookies: comments
- Cookie는 무엇을 위해 사용되는가?
- authorization
- shopping cart
- recommendation
- user session state (Web-email) - Challenge : 어떻게 state를 유지하는가?
- protocol endpoints : 여러 transaction을 통해 sender/receiver의 state를 관리한다.
- cookies : HTTP message가 state를 포함한다.
+) 써드파티의 persistent cookie(tracking cookie)를 허락하면 여러 웹사이트에서 cookie 값을 추적하도록 허락하게 된다.
Web caches (proxy servers)
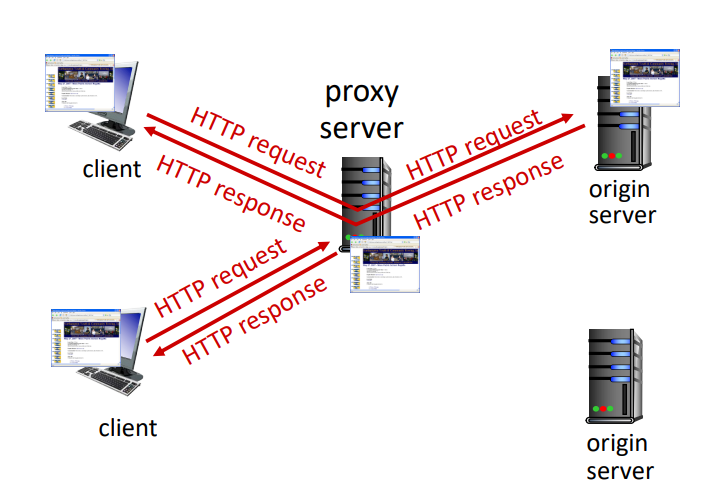
Client는 멀리 있는 origin server까지 가지 않고 가까운 proxy server의 web caches 파일에 접근하여 원하는 파일을 받아올 수 있다. 사용자는 browser를 이용해 web cache를 가리켜 HTTP request/response를 사용해 통신이 가능하다. 만약 object가 cache 안에 있으면 바로 object를 반환하고, 그렇지 않다면 origin server로 request를 보내 resposne를 받아와 다시 client로 반환하게 된다.
- Web cache는 client이자 server로 동작하는 셈.
- cache는 ISP(university, company, residential ISP)에 의해 설치된다.
- Server는 cache에게 object의 caching에 대한 정보를 response header에 담아 전달한다.
왜 Web caching을 사용하느가?
- client request에 대한 response time을 줄인다.
- 물리적으로 더 가까운 위치. - institution의 access link에 대한 traffic을 줄인다.
- internet 전체에 대한 web traffic을 줄여 applicaiton들의 퍼포먼스를 향상시킨다.
Caching 예제
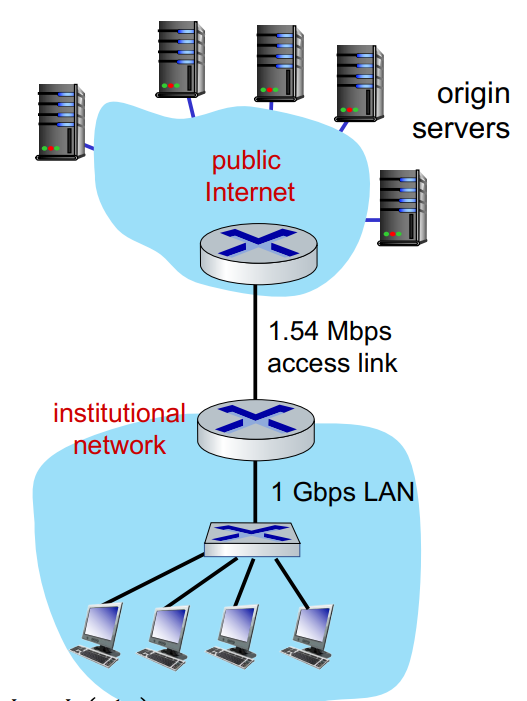
- 문제 조건
- access link rate: 1.54 Mbps
- RTT between Internet-side of access link and origin server: 2sec
- Web object size: 100K bits
- Average request rate from browsers to orgin server: 15 request/sec
- average data rate to browser: 1.50 Mbps
이때, access link의 propagation delay는 없다고 가정하자.
- end-to-end delay = Internet delay + Access link delay + LAN delay
- Internet delay = 2sec
- Access link delay = Access link transmit delay + Access link queueing delay
- Access link transmit delay = L / R
- Access link queueing delay = (L/R) * (traffic intensity/(1-traffic intesity))
- Access link delay = L / ((1 - traffic intensity)
- Traffic intensity = (L x a)/R = (0.1Mbits x 15/sec) / 1.54 Mbps = 0.97 (1에 가까워서 큰 delay가 생길 것을 알 수 있음)
- Access link delay = 2.16sec
- LAN delay = 매우 작아서 무시
- LAN traffic delay (15 request/sec) * (100Kbits/request) / 1Gps = 0.0015
+) traffic delay가 0.8 보다 작으면 delay가 msec 이하라서, 무시할 수 있는 수준이다.
- LAN traffic delay (15 request/sec) * (100Kbits/request) / 1Gps = 0.0015
Caching 예제 - 더 빠른 access link일 경우
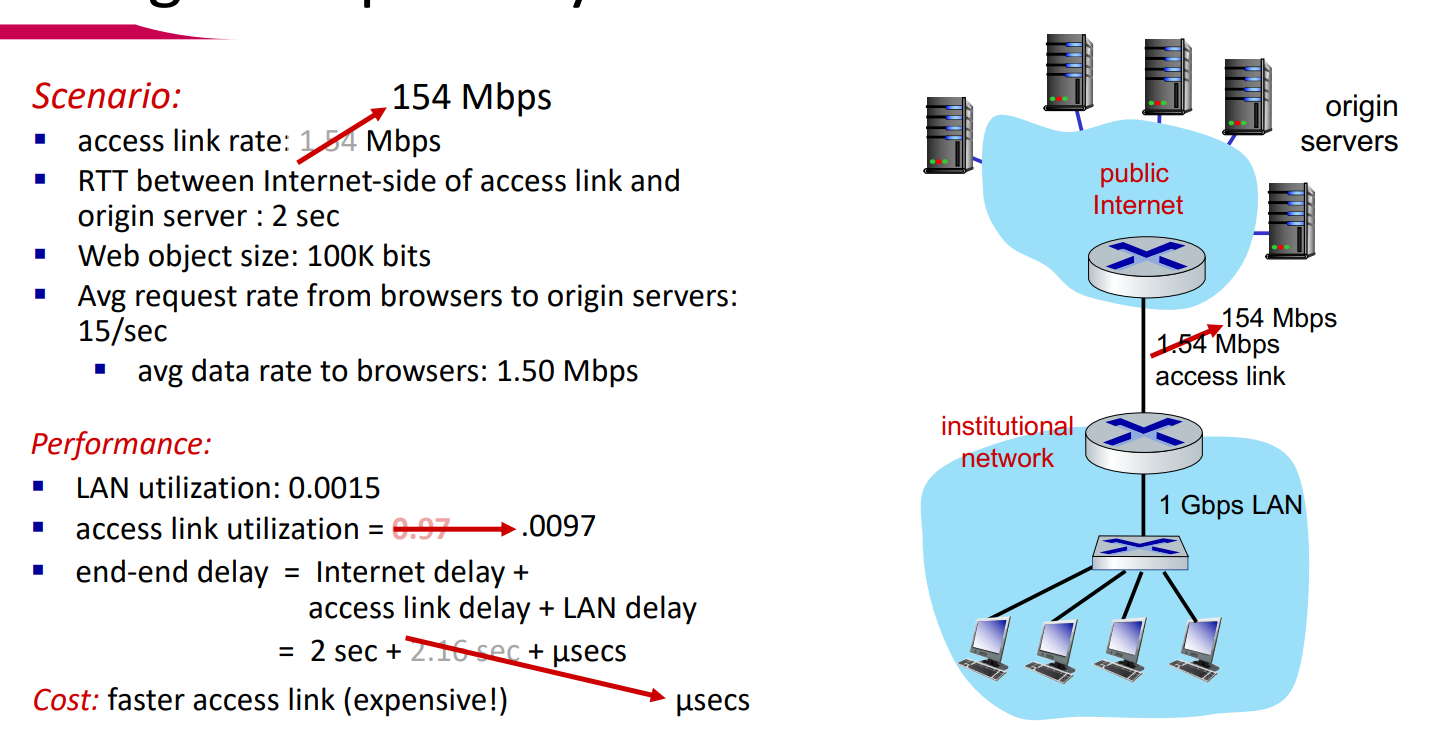
access link의 속도가 100배 빨라지면, 그에 따른 intensity가 100배 작아지게 된다. 이로 인해 access link delay가 매우 작아지게 되어 무시할 수 있어 최종 delay는 그냥 2sec이 된다. 하지만, 매우 비싸기 때문에 사용하지 않는 방법이다.
Caching 예제 - Web cache를 쓸 경우
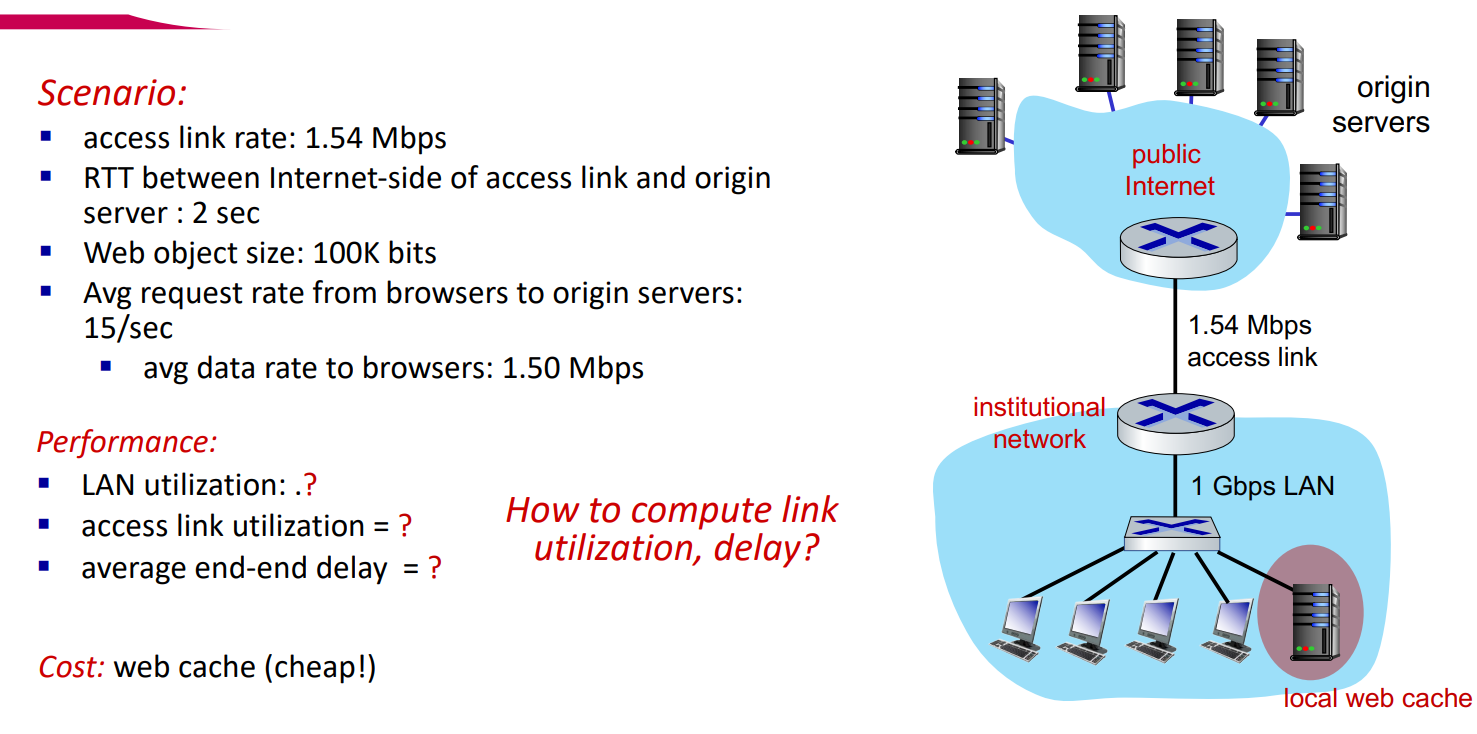
Web cache를 사용하게 되었을 때, 이때 cache의 hit rate가 40%라고 하자.
- Cache에서 40%의 request가 충족되므로, 60%의 request만 origin server에 접근한다.
- Accss link의 request rate가 15 -> 15 x 0.6 = 9 request / sec으로 바뀐다.
- 전체 delay = 0.4 x (delay when satisfied at cache) + 0.6 x (delay from origin server) = 0.6 x (2.15) = ~ 1.3sec
- delay from origin server = internet delay + access link delay = 2sec + 0.15sec = 2.15sec
- delay when satisfied at cache = ~msec (무시)
이 방법은 기존에 비해 average end-end delay도 감소하며, 비교적 저렴한 비용에 실현 가능하다!
+) 이 상황의 utilization은 traffic intensity로 대체될 수 있다. Access link나 LAN에서의 traffic intensity와 utilization은 동일한 값을 갖는 경우가 많다.
+) end-end delay를 response time이라고 물을 수도 있다.
Condition GET
cache는 이미 최신 버전의 내용을 가지고 있다면 굳이 server와 상호작용할 필요가 없다. 따라서, 이 경우엔 object transmission delay가 없어야 하고, link utilization도 낮출 수 있다.
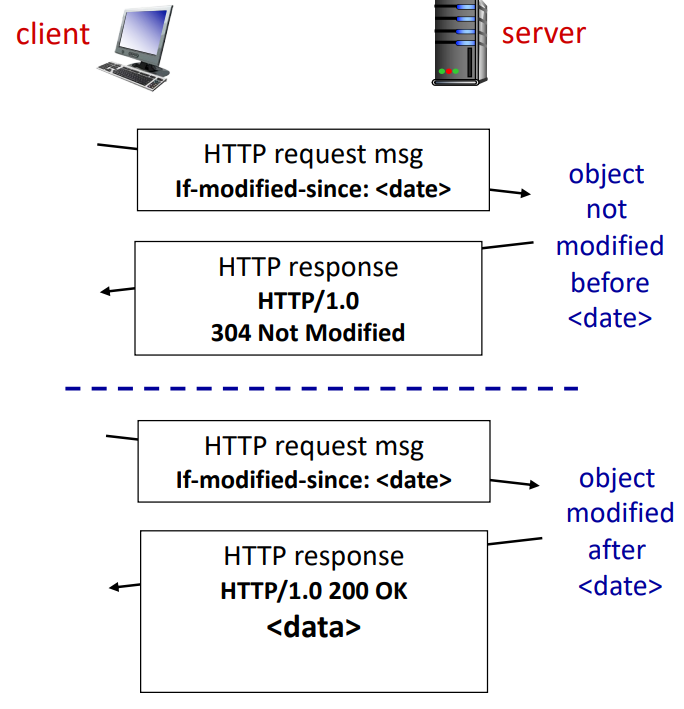
이를 위해, cache에서는 HTTP request에 cached copy의 날짜를 명시한다.
- If-modifed-since: < date >
Server에서 바라봤을 때 만약 cached copy가 이미 최신버전이라면 response에 object가 포함되지 않는다.
- HTTP/1.0 304 Not Modifed
HTTP/2
Problem of HTTP 1.1
HTTP1.1은 하나의 TCP connection 과정에서 multiple & pipelined GETs를 사용하였다. 서버는 이에 대해 in-order(FCFS: first come first served scheduling)로 respond를 보내야 했고, 이로 인해 크기가 작은 object는 큰 object에 비해 계속해서 전송이 밀리는 문제가 생겼다. (Head-of-line(HOL) blocking) 또한, 잃어버린 TCP segment들을 재전송하는 과정에서 다음 object의 전송을 stall 시켜야해서 여러 object를 전송하는 상황의 경우 많은 delay가 발생하였다.
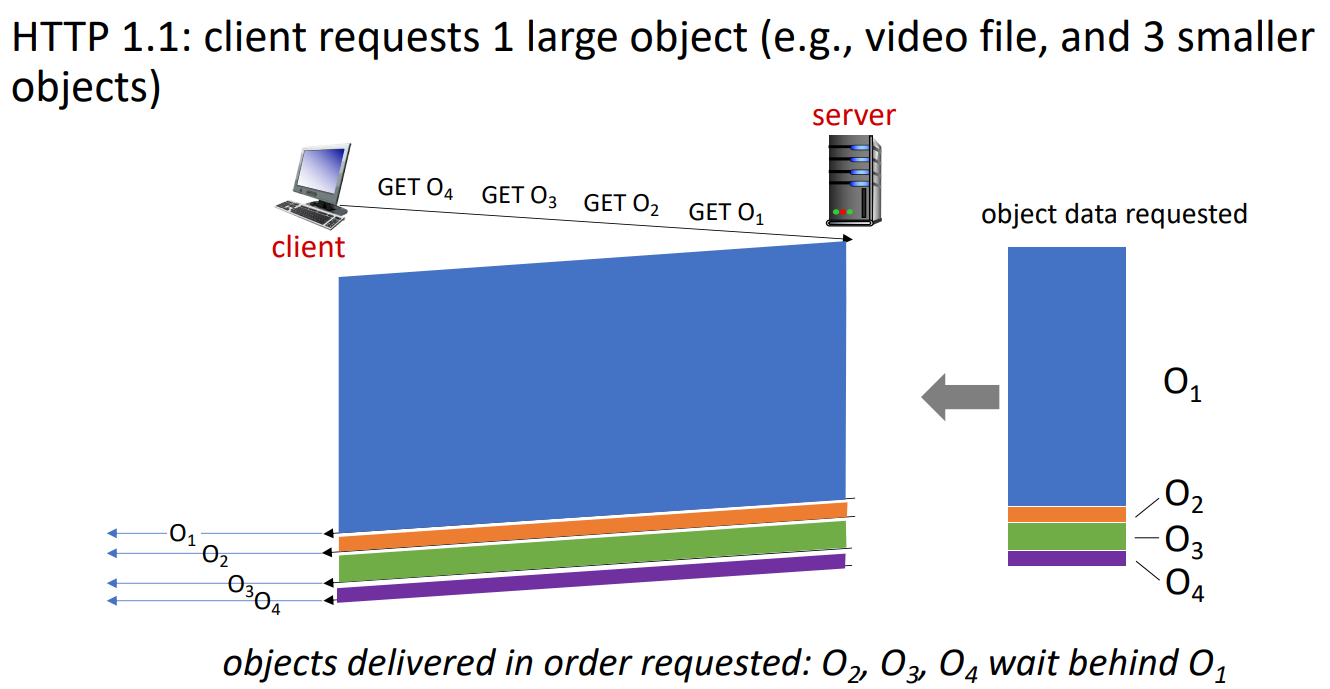
위 그림을 통해 크기가 큰 O1의 전송 때문에 O2 ~ O4가 뒤늦게 나타남을 확인할 수 있다. (즉, 로딩이 안된다..!)
HTTP/2
HTTP/2는 multi-object HTTP request의 delay를 줄이기 위해 server에서 client로 보내는 과정에 flexibility를 추가한 방법이다.
- Method, status code를 비롯한 대부분의 header field는 HTTP 1.1에 비해 바뀌지 않았다.
- 다만, request object의 전송 순서는 client에 특화된 우선순위에 따라 정해졌다. (굳이 FCFS가 아니어도 된다.)
- unrequested object도 client에 push한다.
- Object를 frame들로 나누어, HOL blocking 문제를 완화시키고자 frame단위로 scheduling한다.
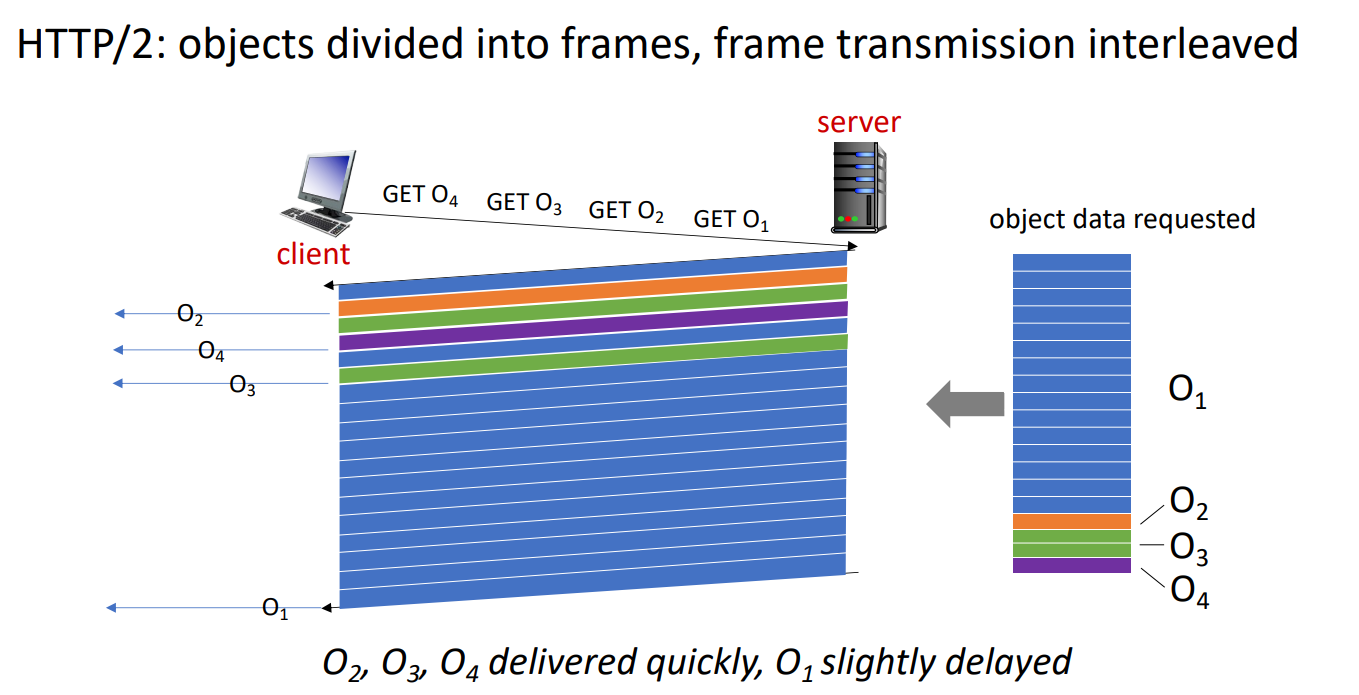
HTTP/2 to HTTP/3
HTTP/2가 등장하며 HOL blocking 문제를 완화시킬 수 있었으나, 여전히 packet loss를 회복하는 과정에서 stall에 대한 문제점이 남아있었다. HTTP/2에서는 HTTP 1.1 때와 마찬가지로 브라우져가 multiple parallel TCP connection을 수행해서 stalling을 감소하는 것이 대책이었다. 그 외에도, vanilla TCP connection 과정에서 security를 고려하지 않았다.
HTTP/3는 security를 더하고, object당 error-control, congestion-
control을 추가하여 UDP connection을 이용하여 고안된 방식이다.

{kind=link}