Reinforcement Learning
강화학습의 가장 중요한 키워드는 Interaction으로 주변 환경과 매 순간 상호작용하며 학습을 수행하는 방법론입니다.
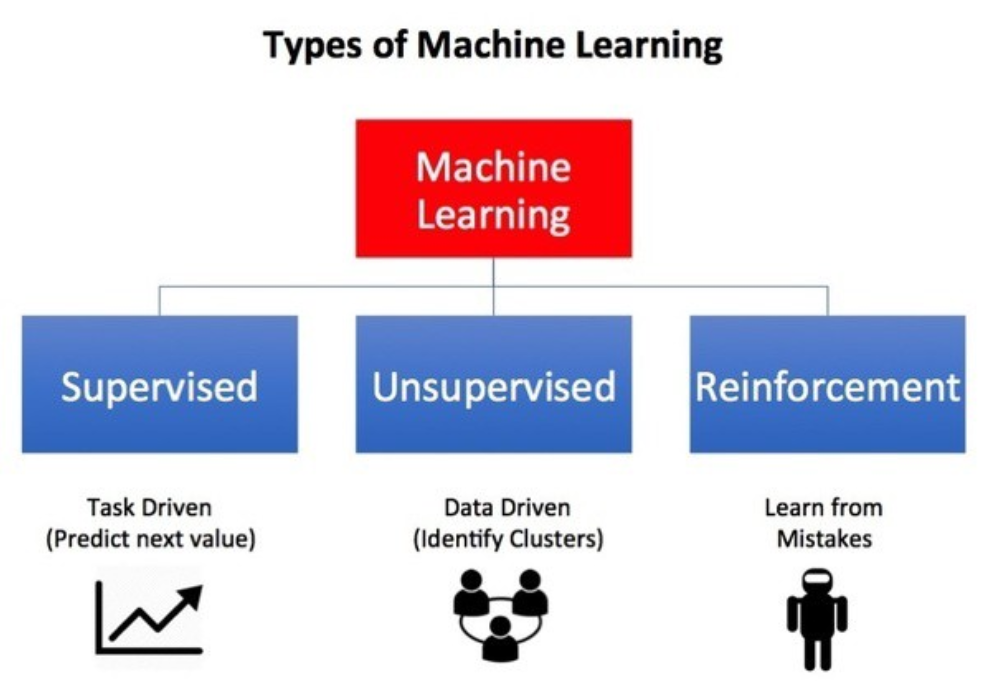
MachineLearning학습은 그 성질에 따라 여러 종류가 존재하는데 크게 Supervised Learning, Unsupervised Learning을 먼저 떠올리기 마련입니다.
-
Supervised Learning
- 지도학습(Supervised Learning)은 미리 취해야할 정답이 포함된 Training set을 통해 학습하는 방법입니다. 지도학습의 목표는 시스템의 행동을 예측하거나 일반화시켜 Training set에 포함되지 않은 상황에서 올바른 행동을 취하도록하는 것입니다.
-
Unsupervised Learning
- 비지도학습(Unsupervised Learning)은 지도학습과는 반대로 정답이 없는 Training set을 사용하는 학습 방법을 의미합니다. 비지도학습은 Data set에서 숨겨진 구조를 찾는것이 목표입니다.
- 비지도학습(Unsupervised Learning)은 지도학습과는 반대로 정답이 없는 Training set을 사용하는 학습 방법을 의미합니다. 비지도학습은 Data set에서 숨겨진 구조를 찾는것이 목표입니다.
지도학습과 비지도학습과는 사뭇 다른 성격의 제 3의 학습방법으로 불리는 강화학습이 존재합니다.
강화학습은 주어진 환경과 상호작용하며 보상을 통해 학습하는 방법으로 좀 더 자세히 알아보도록 하겠습니다.
Elements of Reinforcement Learning
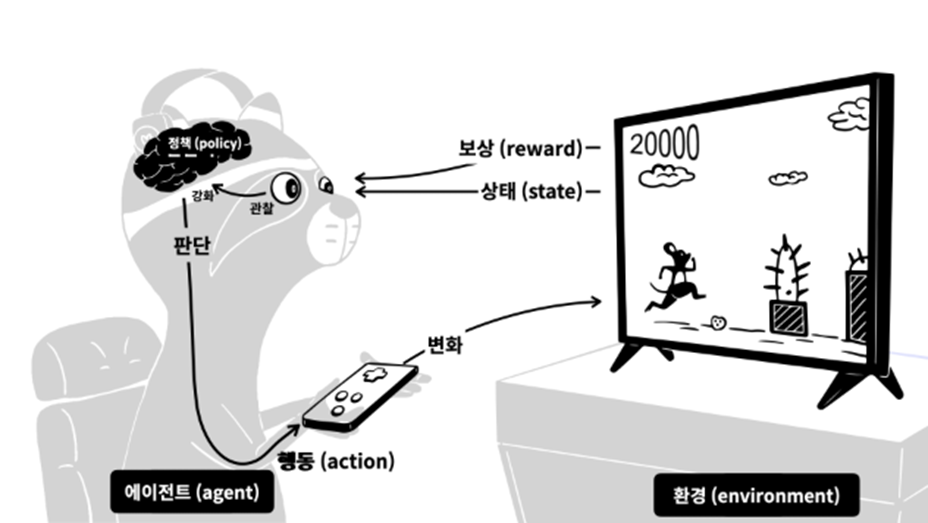
강화학습에는 Environment, Agent, State, Action, Reward, Policy, Value 라는 개념들이 존재합니다.
흔히 강화학습을 게임에 많이 빗대어 설명을 합니다.
- Environment(환경) -> 게임
- Agent(학습자)->플레이어
- State(상태)->게임속 화면
- Action(행동)->조작
- Reward(보상)->상과 벌
- Policy(정책)->주어진 화면에 대한 플레이어의 판단
- Value(가치)->예상되는 총 점수
게임의 플레이어는 가장 높은 점수를 얻는다 라는 확실한 목표를 갖고 목표를 달성하기 위해 게임을 플레이합니다. 게임 도중에 장애물을 만나 점수를 차감당하거나 코인을 획득해 점수가 오르기도 합니다. 각 상황을 여러번 경험해보면서 어떤 상황에서 어떤 행동을 취해야 목적인 가장 높은 점수를 달성 할 수 있는지 학습을 하게 됩니다.

이처럼 Agent는 Environment에서 주어지는 각 State에 대해 Action을 Policy에 근거하여 취합니다. 그에 대한 Rewards를 통해 Policy를 변경해가면서 최적의 Policy를 찾게 됩니다.
Rewards vs Value
Policy를 변경하는 과정에서 고려되는 것은 Action에 따른 Rewards와 Value입니다. Rewards는 그 순간 State에서 Action에 의해 얻게 되는 즉각적인 숫자로 표현됩니다. 그러나 Value는 그 순간부터 이후의 올 일정 기간동안 예상되는 Rewards의 총 합을 의미합니다.
어느 순간 높은 Rewards를 갖고 있지만 이후에 얻게될 Rewards들이 적은 값으로 예상된다면 Value는 낮은 값으로 추정됩니다. 반대로 낮은 Rewards를 가지고 있지만 이후 높은 Rewards들이 예상된다면 Value는 큰 값을 가지게 되는 것입니다.
Rewards의 총 합을 최대로 한다는 강화학습의 목표를 생각해 보았을때 Rewards보다는 Value를 더 많이 고려해 Policy를 변경합니다.
Exploration vs Exploitation
Exploration(탐험) vs Exploitation(활용)은 강화학습의 가장 큰 딜레마입니다.
Agent는 학습하는 동안 경험에서 높은 rewards를 얻었던 action을 선호(exploitation)해야 하지만 경험만 의존해서는 rewards의 총 합을 최대화 하는 목표를 달성할 수 없습니다. 즉 과거 경험해보지 못한 새로운 action을 시도(exploration)해봐야하는 딜레마가 존재합니다.
두 관점의 적절한 trade-off를 찾는 방법도 중요한 문제입니다.
이미지 출처: 생활코딩 강화학습 Reinforcement Learning
