Review
- 프로세스는 운영체제가 자원을 할당하는 단위
- 메모리를 할당받은 프로세스는 메모리 관리를 위해 특정 구조로 공간을 관리(Code, Data, Stack, Heap)
- CPU에 의해 프로그램 실행 -> 프로세스 생성 & 메모리에 프로세스 주소 공간 할당
프로세스 주소 공간
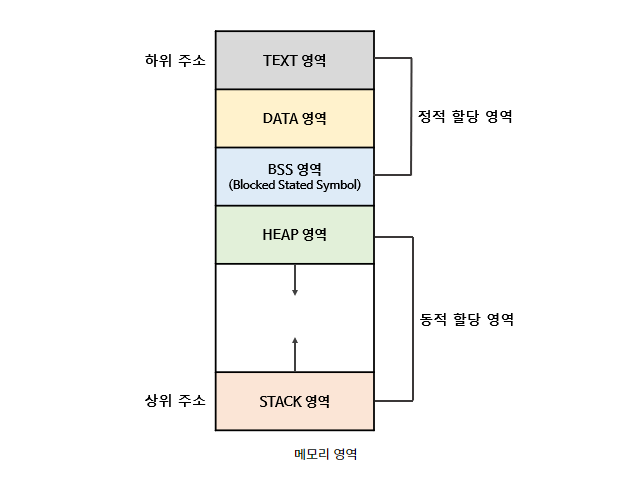
프로세스 주소 공간 구조
Code(Text) Segment
- CPU가 해석 가능한 기계어 형태로 프로그램 코드(Object file) 저장
- Read-Only (프로그램이 임의로 수정되면 안되기 때문)
Data Segment
- 전역 변수, Static local 변수 저장 -> 프로그램 컴파일 후 해당 변수를 사용하는 부분에서 Data Segment 참조
- 프로그램 시작 시 할당 / 종료 시 할당 해제
- 초기화되지 않은 변수는 Data Segment가 아닌 BSS(Blocked Stated Symbol) Segment에 저장
- Read/Write (Runtime에 변수 값이 변경될 수 있기 때문)
Stack Segment
- 함수/함수 내에서 사용되는 지역변수/매개변수 저장
- 함수 호출 시 Stack 영역에서 공간 할당 / 완료 시 할당 해제
- 메모리의 높은 주소 -> 낮은 주소로 할당
- 실제 Object는 Heap Segment에 위치하고, Stack에서는 해당 Object를 참조 => Stack Segment에 할당되는 영역이 크지 않음
- 재귀 함수의 Depth가 너무 깊거나 지역변수가 너무 많아서 Stack의 할당 가능 영역 초과 시 Stack Overflow 발생 가능
- Read/Write (Runtime에 변수 값이 변경될 수 있기 때문)
Heap Segment
- Runtime에 크기가 결정됨
- 사용자에 의해 공간이 동적으로 할당 및 해제
- 메모리의 낮은 주소 -> 높은 주소로 할당
- 참조형 데이터(클래스, 클로저 등) 저장
기본형과 참조형
기본형(Primitive Type)
- 각 데이터 당 메모리 공간 할당
- 메모리 내에 고정된 크기로 저장
- 원시 데이터 값 자체를 보관
참조형(Reference Type):
- 기본형 데이터의 집합(배열, 함수, Map, Class 등)
- 실제 값이 저장된 위치의 주소 값 할당
데이터 공유와 메모리 최적화
1. Code Segment를 별개로 두는 이유
- 컴파일 이후에는 프로그램 코드가 변경되지 않음
- 하나의 프로그램에 대해 Multi Process 방식을 사용하더라도 참조하는 코드는 모두 동일
=> 같은 프로그램에 대한 Process인 경우, Code 영역을 공유하여 불필요한 메모리 사용 방지
2. Data Segment와 Stack Segment를 구분하는 이유
- 전역 변수는 함수와 관계 없이 프로그램의 모든 위치에서 접근할 수 있으므로, Stack Segment에서 반복해서 저장하지 않고 Data Segment에 전역 변수를 모두 저장 후 필요 시 참조해서 사용 (전역 변수의 활용성)
- LIFO+함수 종료 시 모든 변수가 pop되는 Stack 자체의 특성을 고려했을 때, 특정 함수가 아닌 모든 위치에서 접근 가능해야 하는 전역 변수는 Stack에서 pop되거나 여러 번 저장되지 않도록 Data Segment에 따로 저장(Stack 구조의 특성)
3. Data Segment와 BSS Segment를 구분하는 이유
- 초기화되지 않은 변수는 프로그램 시작 시에 값을 저장할 필요가 없으며 사용 가능한 영역만 할당
- 초기화된 변수는 값을 저장하고 있어야 함
- BSS 영역(초기화되지 않은) 변수가 많아져도 프로그램의 실행 코드 사이즈가 커지지 않도록 하기 위해 Data와 BSS Segment 구분
4. Multi Thread 에서의 주소 공간 공유
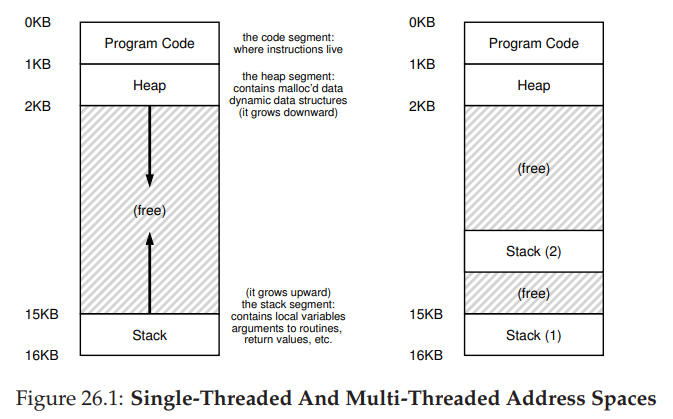
- Multi Thread 환경에서, 각 Thread는 Code, Data, Heap 영역은 모두 공유하고 Stack 영역만 각자 할당
- 따라서, Read/Write가 모두 가능한 Data 영역에서 동기화 문제 발생 가능
References
