배경
딥러닝 기반의 Object Detection System들은 Classification 모델을 Object Detection 시스템에 맞게 변형한 모델들이 주를 이루었습니다.
기존의 검출(detection) 모델은 분류기(classfier)를 재정의하여 검출기(detector)로 사용하고 있습니다. 하지만 객체 검출(object detection)은 하나의 이미지 내에서 개는 어디에 위치해 있고, 고양이는 어디에 위치해 있는지 판단하는 것입니다. 따라서 객체 검출은 분류뿐만 아니라 위치 정보도 판단해야 합니다.

대부분의 변형된 모델들은 Deformable Parts Models(DPM)이 sliding window 방법론을 사용하여 전체 이미지를 Classifier로 스캔하는 방식 형태의 방법론을 사용했습니다.
You Only Look Once
You Only Look Once(이하 YOLO)는 기존의 방법론인 Classification모델을 변형한 방법론에서 벗어나, Object Detection 문제를 regression문제로 정의하는 것을 통해서 이미지에서 직접 bounding box 좌표와 각 클래스의 확률을 구합니다.
이미지의 픽셀로부터 bounding box의 위치(coordinates), 클래스 확률(class probabilities)을 구하기까지의 일련을 절차를 하나의 회귀 문제로 재정의한 것입니다.
YOLO는 End-to-End 방식의 통합된 구조로 되어 있으며, 이미지를 convolutional neural network에 한 번 평가(inference)하는 것을 통해서 동시에 다수의 bounding box와 class 확률을 구하게 됩니다.
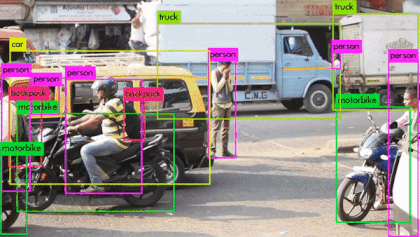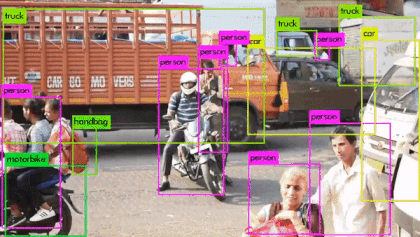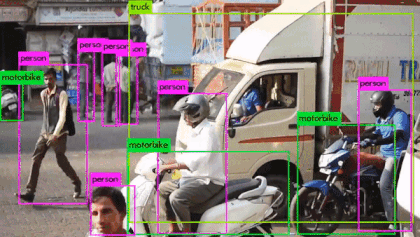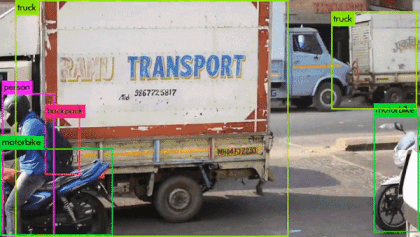
YOLO의 통합된 구조에 따른 장점
-
YOLO는 굉장히 빠릅니다.
기존의 복잡한 객체 검출 프로세스를 하나의 회귀 문제로 바꾸었기 때문입니다. 그리하여 기존의 객체 검출 모델처럼 복잡한 파이프라인이 필요 없습니다. -
YOLO는 예측을 할 때 이미지 전체를 봅니다
라이딩 윈도(sliding window)나 region proposal 방식과 달리, YOLO는 훈련과 테스트 단계에서 이미지 전체를 봅니다. 그리하여 클래스의 모양에 대한 정보뿐만 아니라 주변 정보까지 학습하여 처리합니다.
YOLO 이전의 객체 검출 모델 중 가장 성능이 좋은 모델인 Fast R-CNN는 주변 정보까지는 처리하지 못합니다. 그래서 아무 물체가 없는 배경(background)에 반점이나 노이즈가 있으면 그것을 물체로 인식하는 background error가 발생합니다. -
YOLO는 일반화된 Object의 표현을 학습합니다
일반적인 부분을 학습하기 때문에 자연 이미지를 학습하여 그림 이미지로 테스트할 때, YOLO의 성능은 DPM이나 R-CNN보다 월등히 뛰어납니다. 따라서 좋은 일반화 성능을 가집니다.
하지만, YOLO는 최신(SOTA, state-of-the-art) 객체 검출 모델에 비해 정확도가 다소 떨어진다는 단점이 있습니다. 빠르게 객체를 검출할 수 있다는 장점은 있지만 정확성이 다소 떨어집니다.
Unified Detection
YOLO는 단일 convolutional neural network 모델 하나로 특징 추출, 바운딩 박스 계산, 클래스 분류를 모두 수행합니다. 즉 원본 이미지를 입력으로 받은 모델이 object detection에 필요한 모든 연산을 수행할 수 있다는 의미이며, 이것이 바로 YOLO에서 주장하는 Unified Detection의 개념입니다.
모델이 이미지 전체를 보고 바운딩 박스를 예측할 수 있습니다. 즉 모델이 이미지의 전역적인 특징을 잘 이용해서 추론할 수 있습니다. 그리고 Unified Detection이라는 용어 그대로 모델은 bounding box regression과 multi-class classification을 동시에 수행할 수 있습니다. 이러한 이점들로 인하여 YOLO는 높은 mAP를 유지하면서, end-to-end 학습이 가능하고, 실시간의 추론 속도가 가능한 것입니다.
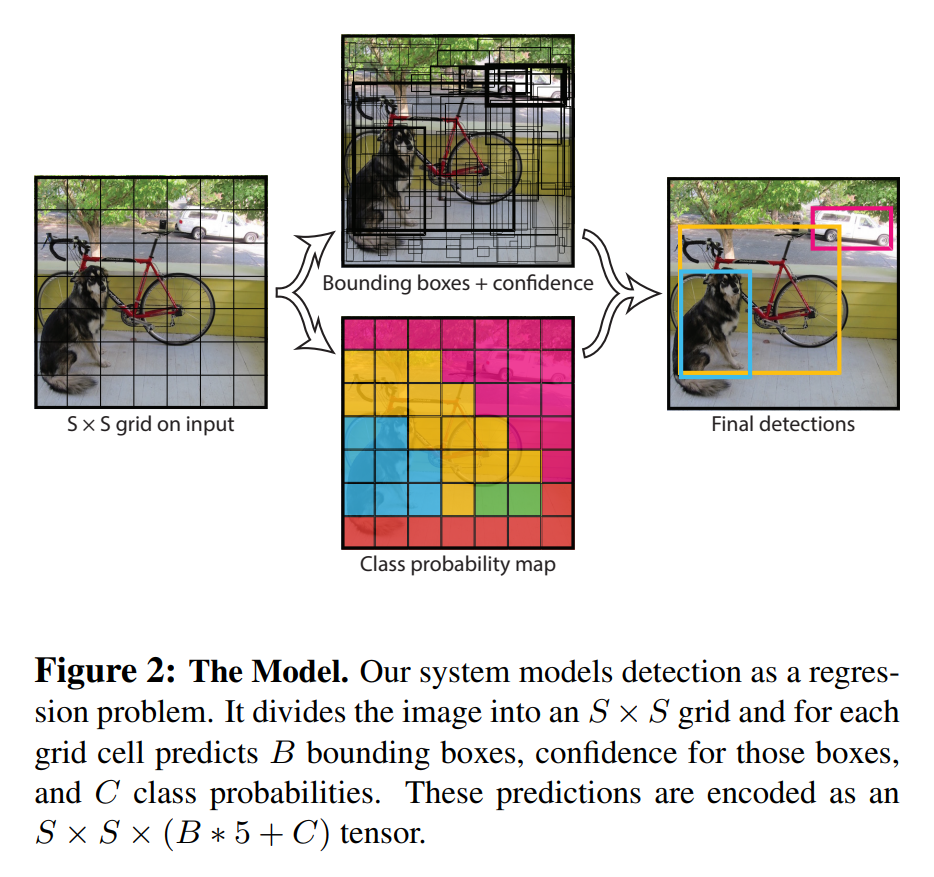
YOLO 모델에서는 입력 이미지를 S x S 그리드로 나눕니다.
만약 어떤 객체의 중점이 특정 그리드 셀 안에 존재한다면, 해당 그리드 셀이 그 객체를 검출해야 합니다. 각 그리드 셀은 B개의 바운딩 박스를 예측합니다. 그리고 각 바운딩박스 마다 confidence scores를 예측하는데, confidence scores란 해당 바운딩 박스 내에 객체가 존재할 확률을 의미하며 0에서 1 사이의 값을 가집니다.

만약 어떤 셀 안에 객체가 없으면 confidence scores는 0입니다. 또한 confidence scores는 모델이 예측한 바운딩 박스와 ground truth 간의 IOU(intersection over union)이 동일할수록 좋습니다.
각 바운딩 박스는 값 5개를 예측합니다 : x, y, w, h, confidence. (x, y)는 바운딩 박스의 중심점이며, 각 그리드 셀마다 상대적인 값으로 표현합니다. (w, h)는 바운딩 박스의 width와 height인데 전체 이미지에 대해 상대적인 값으로 표현합니다. 그리고 confidence는 앞서 다룬 confidence score와 동일합니다.
각 그리드셀마다 확률값 C를 예측합니다. C는 조건부 클래스 확률(conditional class probabilities)인 Pr(Class_i|Object)입니다. YOLO에서는 그리드 당 예측하는 바운딩 박스의 갯수(B)와 상관없이 그리드 당 오직 하나의 클래스 확률만 예측합니다.
바운딩 박스마다 sclass-specific confidence scores를 얻을 수 있습니다. 이 스코어는 해당 바운딩 박스에서 특정 클래스 객체가 나타날 확률과 객체에 맞게 바운딩 박스를 올바르게 예측했는지를 나타냅니다.
논문에서는 PASCAL VOC 데이터 셋을 이용하여 실험을 진행합니다. 이를 위해 S = 7, B = 2 PASCAL VOC에는 20개의 라벨링 된 클래스가 있으므로 C = 20 으로 설정합니다. B=2이라는 것은 하나의 그리드 셀에서 2개의 bounding box를 예측하겠다는 뜻입니다. 이렇게 했을 때 S x S x (B*5 + C) 텐서를 생성합니다. 따라서 모델의 output tensor는 7 x 7 x 30 입니다.
Network Design
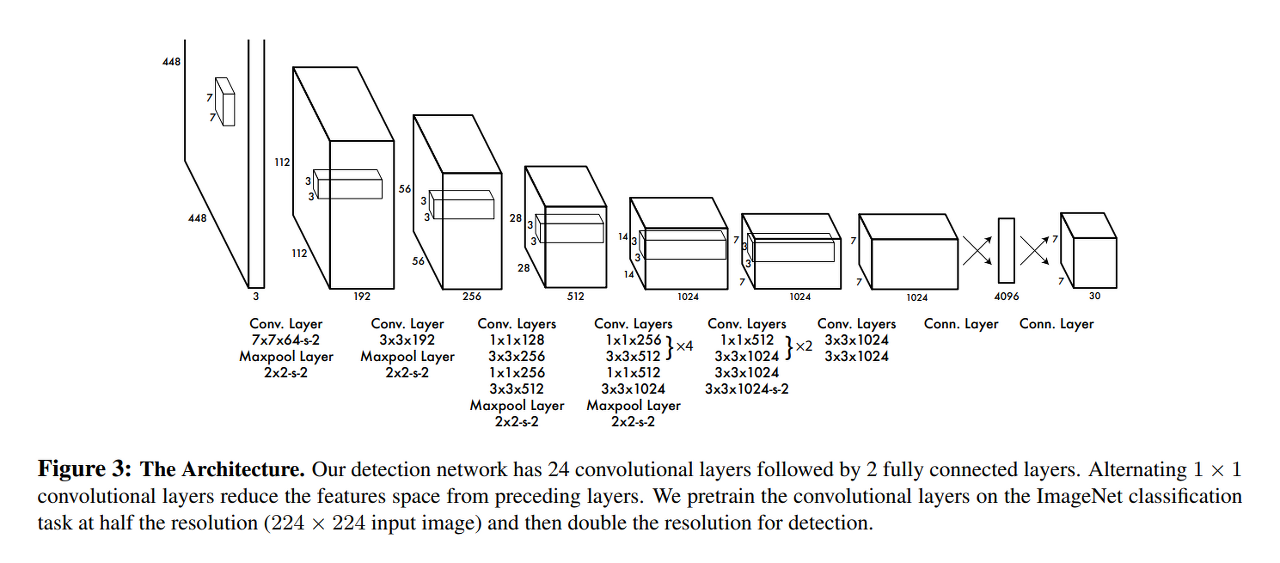
YOLO 모델을 하나의 CNN(Convolutional Neural Network) 구조로 디자인되었습니다. YOLO는 앞단의 convolutional layers와 뒷단의 fully connected layers로 구성됩니다. convolutional layers는 이미지에서 특징을 추출하고, fully connected layers는 추출된 특징을 기반으로 클래스 확률과 바운딩 박스의 좌표를 추론합니다.
YOLO는 24개의 convolutional layers와 2개의 fully connected layers로 구성됩니다.
Training
1,000개의 클래스를 갖는 ImageNet 데이터 셋으로 YOLO의 컨볼루션 계층을 사전훈련(pretrain)시켰습니다. 사전훈련을 위해서 24개의 컨볼루션 계층 중 첫 20개의 컨볼루션 계층만 사용했고, 이어서 전결합 계층을 연결했습니다. 이 모델을 약 1주간 훈련시켰습니다. 이렇게 사전 훈련된 모델은 ImageNet 2012 검증 데이터 셋에서 88%의 정확도를 기록했습니다. YOLO는 앞단 20개의 pretrained convolutional layer에 4개의 convolutional layer와 2개의 fully connected layer를 추가하여 구성합니다. 이때 새로 추가된 레이어는 random initialized weights로 초기화합니다.
신경망의 최종 아웃풋은 클래스 확률과 bounding box 위치정보입니다. bounding box의 위치정보에는 bounding box의 너비(width)와 높이(height)와 bounding box의 중심 좌표(x, y)가 있습니다. YOLO 에서는 정규화된(normalized) 바운딩 박스를 사용합니다. 바운딩 박스의 width와 height는 각각 이미지의 width와 height로 정규화시킵니다.
YOLO 연구진은 너비, 높이, 중심 좌표값(w, h, x, y)을 모두 0~1 사이의 값으로 정규화(normalize)했습니다.
YOLO 신경망의 마지막 계층에는 선형 활성화 함수(linear activation function)를 적용했고, 나머지 모든 계층에는 leaky ReLU를 적용했습니다. ReLU는 0 이하의 값은 모두 0인데 비해, leaky ReLU는 0 이하의 값도 작은 음수 값을 갖습니다.
SSE
YOLO의 loss는 SSE(sum-squared error)를 기반으로 합니다. YOLO의 loss에는 바운딩 박스를 얼마나 잘 예측했는지에 대한 loss인 localization loss와 클래스를 얼마나 잘 예측했는지에 대한 loss인 classification loss가 있습니다. 이 두 개의 loss에 동일한 가중치를 할당하고 학습시키는 것은 좋지 않습니다.
YOLO에서는 S x S개의 그리드 셀을 예측합니다. 거의 모든 이미지에서 대다수의 그리드 셀에는 객체가 존재하지 않습니다. 배경 영역이 전경 영역보다 더 크기 때문입니다. 따라서 대부분의 그리드 셀의 confidence socre=0이 되도록 학습할 수밖에 없습니다. 이는 모델의 불균형을 초래합니다.
이런 불균형은 YOLO가 모든 그리드 셀에서 confidence = 0이라고 예측하도록 학습되게 할 수 있습니다. YOLO에서는 이를 해결하기 위해서 객체가 존재하는 바운딩 박스의 confidence loss 가중치를 늘리고 반대로 객체가 존재하지 않는 바운딩 박스의 confidence loss 가중치를 줄입니다. 이는 실제로 두 가지 파라미터로 조절할 수 있는데, λ_coord와 λ_noobj 입니다. 논문에서는 λ_coord = 5, λ_noobj = .5로 설정합니다.
SSE를 사용하면 바운딩 박스가 큰 객체와 작은 객체에 동일한 가중치를 줄 때도 문제가 생길 수 있습니다. 작은 객체 바운딩박스는 조금만 어긋나도 결과에 큰 영향을 주지만 큰 객체의 바운딩 박스의 경우에는 그렇지 않습니다. 이를 해결하기 위해서 YOLO에서는 width와 height에 square root를 씌웁니다.
Multiple bounding boxes
YOLO는 하나의 그리드 셀 당 여러 개의 바운딩 박스를 예측합니다. 련(training) 단계에서 하나의 bounding box predictor가 하나의 객체에 대한 책임이 있어야 합니다. 즉, 객체 하나당 하나의 bounding box와 매칭을 시켜야 합니다. 따라서 여러 개의 bounding box 중 하나만 선택해야 합니다. 이를 위해 예측된 여러 bounding box 중 실제 객체를 감싸는 ground-truth boudning box와의 IOU가 가장 큰 것을 선택합니다.
Loss Function
훈련 단계에서 사용하는 loss function은 다음과 같습니다.
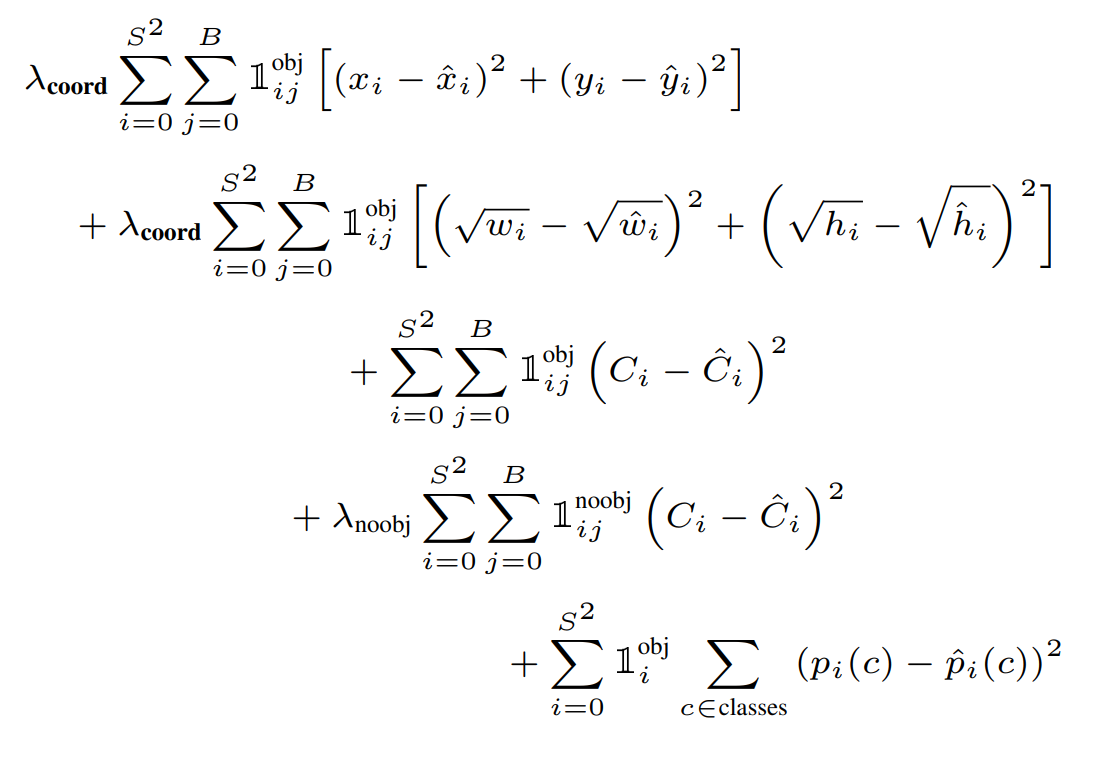
여기에서 1_obj^i 는 i번째 그리드 셀 에 있는 j번째 바운딩박스에 객체가 존재하는지를 나타냅니다. 이 값은 객체 존재하면 1, 존재하지 않으면 0입니다.
학습 및 하이퍼 파라미터
논문에서는 PASCAL VOC 2007 / 2012를 이용해서 총 135 epochs를 학습시켰습니다. 하이퍼 파라미터 세팅은 다음과 같습니다.
- batch size = 64
- momentum of 0.9
- decay = 0.0005
학습률 스케줄링(Learning Rate Scheduling)
첫 epoch은 learning rate =에서 까지 천천히 올립니다.
(처음부터 높은 learning rate를 주게되면 gradient가 발산할 수 있습니다.)
다음 75 epochs은 learning rate = 으로 학습시킵니다.
다음 30 epochs는 learning rate = 으로 학습시킵니다.
다음 30 epochs는 learning rate = 으로 학습시킵니다.
learning rate를 처음에는 점점 증가시켰다가 다시 감소시켰습니다.
오버피팅
YOLO에서는 오버피팅을 방지하기 위해 dropout과 data augmentation 기법을 사용합니다. dropout은 첫 번째 fully connected layer에 붙으며 dropout rate = 0.5로 설정했습니다.
data augmentation을 위해 원본 이미지의 20%까지 랜덤 스케일링(random scaling)과 랜덤 이동(random translation)을 적용했습니다.
Inference
추론 단계에서도 테스트 이미지로부터 객체를 검출하는 데에는 하나의 신경망 계산만 하면 됩니다. 파스칼 VOC 데이터 셋에 대해서 YOLO는 한 이미지 당 98개의 bounding box를 예측해주고, 그 bounding box마다 클래스 확률(class probabilities)을 구해줍니다.
OLO의 그리드 디자인(grid design)은 한 가지 단점이 있습니다. 그것은 바로 하나의 객체를 여러 그리드 셀이 동시에 검출하는 경우입니다. 객체의 크기가 크거나 객체가 그리드 셀 경계에 인접해 있는 경우, 그 객체에 대한 bounding box가 여러 개 생길 수 있습니다. 하나의 객체가 정확히 하나의 그리드 셀에만 존재하는 경우에는 이런 문제가 없지만 객체의 크기, 객체의 위치에 따라 충분히 이런 문제가 발생할 수 있습니다. 이러한 다중 검출(multiple detections) 문제는 최대억제(Non-maximal suppression)를 이용해 개선했습니다. YOLO는 NMS를 통해 mAP를 2-3% 가량 올릴 수 있었습니다.
YOLO의 한계
1. 공간적 제약
YOLO는 각 그리드 셀마다 오직 하나의 객체만을 검출할 수 있습니다. 이는 객체 검출에서 아주 강한 공간적 제약(spatial constraints)입니다. 이러한 공간적 제약으로 인해 YOLO는 '새 떼'와 같이 작은 객체들이 무리 지어 있는 경우의 객체 검출이 제한적일 수 있습니다.
2. 일반화 능력
그리고 바운딩 박스를 데이터로부터 학습하기 때문에 일반화 능력이 떨어지고, 이로 인해 train time에 보지 못했던 종횡비의 객체를 잘 검출하지 못합니다.
3. 잘못된 localizations
YOLO에서 가장 문제가 되는 부분이 바로 잘못된 localizations입니다. YOLO 모델은 큰 bounding box와 작은 bounding box의 loss에 대해 동일한 가중치를 둔다는 단점이 있습니다. 크기가 큰 bounding box는 위치가 약간 달라져도 비교적 성능에 별 영향을 주지 않는데, 크기가 작은 bounding box는 위치가 조금만 달라져도 성능에 큰 영향을 줄 수 있습니다.
📌 출처
You Only Look Once - Paper Review : 모두의 연구소
논문 리뷰 - YOLO(You Only Look Once) 톺아보기 : 귀퉁이 서재_Baek Kyun Shin
📌 이미지 출처
Terminologies used In Face Detection with Haar Cascade Classifier: Open CV : sliding window
YOLOv3 Object Detector : bounding box
