
🔎 시카고 맛집 데이터 분석
시카고 맛집 데이터 분석 - 개요
The 50 Best Sandwiches in Chicago
- 최종목표
총 51개 페이지에서 각 가게의 정보를 가져온다 - 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
1. 시카고 맛집 데이터 분석 - 메인 페이지 분석
header 에 웹브라우저 정보를 입력해준다 .
UserAgent()를 통해 fake 정보를 입력할 수 있다.
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
#!pip insntall fake-useragent
from fake_useragent import UserAgent
import pandas as pd
import re
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base+url_sub
ua = UserAgent()
# req=Request(url,headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"})
# req=Request(url,headers={"user-agent" : "Chrome"}) # header 값이 필요한 웹페이지는 필수로 입력
req = Request(url, headers={"user-agent": ua.ie}) # user-agent 값 fake로 입력 가능
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
soup
페이지의 HTML 코드 확인
...
<p>In our research, we learned that the sandwich is a wily chameleon, soaking up and synthesizing every trend, be it the resurgence of house-cured charcuterie or the sudden ubiquity of arugula. We learned to ask for extra napkins ahead of time. And we learned, above all, that quality and quantity can intersect in restaurants, and there’s no shame in that. Only joy.</p>
<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>
<div class="sammy" style="position: relative;">
<div class="sammyRank">2</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/"><b>Fried Bologna</b><br/>
Au Cheval<br/>
<em>Read more</em> </a></div>
</div>
<div class="sammy" style="position: relative;">
<div class="sammyRank">3</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/"><b>Woodland Mushroom</b><br/>
Xoco<br/>
<em>Read more</em> </a></div>
</div>
...
find / select 함수를 통해 tag = div, class = sammy 값만 가져온다
# soup에서 tag = div, class = sammy 값 가져옴
# find
soup.find_all("div", "sammy"), len(soup.find_all("div", "sammy"))
# select
# soup.select("div .sammy") , len(soup.select("div .sammy"))
- sample code
[<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>위에서 가져온 데이터에서 랭킹, 메뉴, 카페 정보, url 값을 가져온다
from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy") # soup.select(".sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
# 불필요한 글자 제거
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
len(rank), len(cafe_name), len(url_add), len(main_menu)(50, 50, 50, 50)
리스트를 데이터프레임 형태로 변환
# 데이터 프레임으로 만들기
import pandas as pd
data = {
"Rank": rank,
"Cafe": cafe_name,
"Menu": main_menu,
"URL": url_add
}
df = pd.DataFrame(data)
df.tail()
컬럼순서 변경 후 데이터 저장
# 컬럼 순서 변경
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
# 데이터 저장
df.to_csv("../data/03. best_sandwiches_list_chicago.csv",
sep=",", encoding="utf-8")2. 시카고 맛집 데이터 분석 - 하위페이지
데이터 가져오기
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail()

각 가게의 URL에 들어가서 정보 가져오기
df["URL"][0] # 하위 페이지(URL)에서 정보가져오기
url = df["URL"][0]
ua = UserAgent()
req = Request(url, headers={"user-agent": ua.ie}) # fake user-agent
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
# '$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
detail = soup.find("em").text
detail각 정보가 한 문장에 들어가 있다
'$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'정규식을 통해 원하는 정보만 가져온다
price = re.search("\$d+.(\d+)?", detail[0]).group()$기호와 숫자로 시작하다가 . 을 만나고 그 뒤에 숫자가 있을수도 없을수도 있다.
# regular expression 정규 표현식
#'$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
import re
# ['$10. 2109 W. Chicago Ave.', ' 773-772-0406', ' theoldoaktap.com']
detail = re.split(",", detail) #['$10. 2109 W. Chicago Ave.', ' 773-772-0406', ' theoldoaktap.com']
price = re.search("\$\d+.(\d+)?", detail[0]).group() # $10.
address = detail[0][len(price)+2:]
address
'3351 N. Broadway'
함수를 통해 전체 과정을 합쳐준다
tqdm을 통해 진행률을 표시
실습예제와 다르게 여러 에러가 발생해 에러 방지 코드도 추가해준다.
# conda install -c conda-forge tqdm
from tqdm import tqdm
from urllib.error import HTTPError
price = []
address = []
for idx, row in tqdm(df.iterrows()): # tqdm : 진행률 보여줌
# url=df["URL"][idx] # 하위 페이지(URL)에서 정보가져오기
ua = UserAgent()
try: # raise HTTPError(req.full_url, code, msg, hdrs, fp) 방지
url = row["URL"]
req = Request(url, headers={"user-agent": ua.ie}) # fake user-agent
response = urlopen(req)
except HTTPError as e:
price.append(None)
address.append(None)
print(e) # HTTP Error 403: Forbidden
continue
soup = BeautifulSoup(response, "html.parser")
# '$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
detail = soup.find("em").text
# ['$10. 2109 W. Chicago Ave.', ' 773-772-0406', ' theoldoaktap.com']
detail = re.split(",", detail)
# AttributeError: 'NoneType' object has no attribute 'group' 방지
if re.search("\$\d+.(\d+)?", detail[0]) != None:
price.append(re.search("\$\d+.(\d+)?", detail[0]).group()) # $10.
address.append(detail[0][len(re.search("\$\d+.(\d+)?", detail[0]).group())+2:])
else:
price.append(None)
address.append(None)
가격과 주소 정보를 데이터프레임에 추가해준다 .
print(len(price))
print(len(address))
df["Price"] = price
df["Address"] = address
df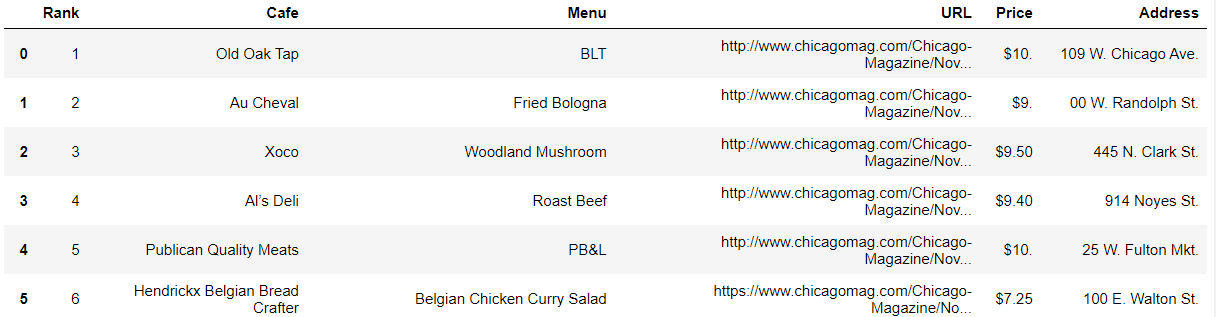
3. 시카고 맛집 데이터 분석 - 시각화
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdmdf=pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv",index_col=0)
df.tail()
구글맵 API를 이용한다
gmaps_key='Google Map Key'
gmaps=googlemaps.Client(key=gmaps_key)
address 주소를 통해 위도와 경도를 가져온다
여러 지점이 있을 경우에는 Multiple location 값을 가져오므로 Multiple location은 제외해준다
``python
lat=[]
lng=[]
for idx, row in tqdm(df.iterrows()):
if not row["Address"]=="Multiple location":
target_name=row["Address"]+", "+"Chicago"
# print(target_name)
gmaps_output=gmaps.geocode(target_name)
location_output=gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(None)
lng.append(None)```python
df["lat"]=lat
df["lng"]=lng
df.tail()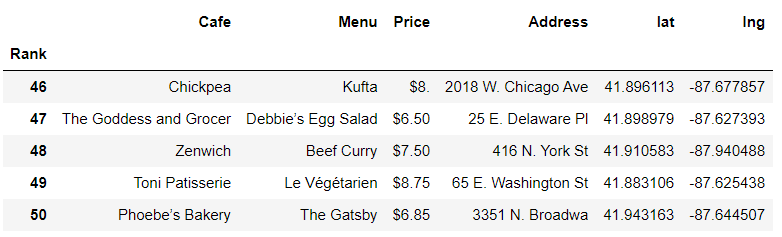
mapping=folium.Map(
location=[41.8781136, -87.6297982],
zoom_start=11
)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"],row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
icon_color="black",
prefix="fa"
)
).add_to(mapping)
mapping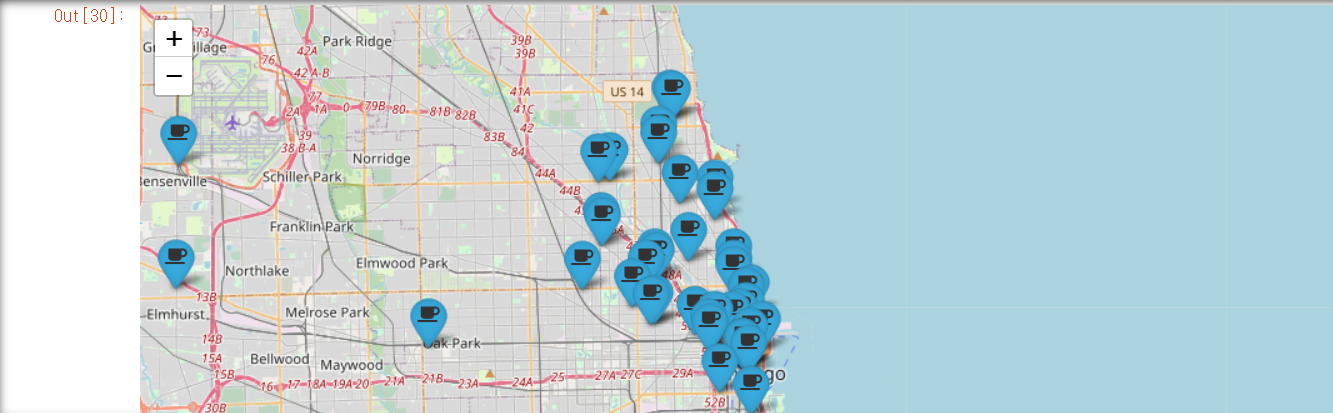

개발하고싶은사람