
코루틴은 코틀린의 새로운 기능이다. 코루틴은 동시성 논블로킹 코드를 만드는 좋은 방법을 제공해준다. 코루틴은 일시중단 다능한 함수와 함께 사용된다. 드리도 코루틴의 실행은 중단될 수도 잇고, 재개될 수도 있다. 이런 기능들은 컨티뉴에이션을 이용해서 코틀린에 만들어져 있다.
컨티뉴에이션은 추후 함수 호출을 이어가기 위해 함수의 내부 상태를 보호하는 데이터 구조이다.
📌 코루틴과 동시실행
어떤 작업은 숭서대로 실행되어야 한다. 어떤 것들은 병령로 수행될 수도 있다. 그리고 동시에 완료돼야 하느 것들도 있을 수 있다.
순차적 실행은 명확하다. 다음 작업을 하기 전에 이전 작업이 완료되어야 한다. 개발자들 사이에서 병렬 실행과 동시 실행은 혼란스러운 점이 존재한다. 병렬 실행과 동시 실행의 차이점을 이해하는 것은 중요하다. 멀티 코어 프로세서의 멀티 스레드는 일반적으로 병렬로 실행되고 코루틴은 일반적으로 병렬실행 보다는 동시실행에 더 많이 사용되기 때문이다.
병렬(parallel) vs 동시성(concurrency)

동시성 : 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질을 말한다. 동시성을 이용한 싱글 코어의 멀티 태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아가면서 조금씩 실행되고 있는 것이다.
병렬성 : 멀티 코어에서 멀티 스레드를 동작시키는 방식으로, 한 개 이상의 스레드를 포함하는 각 코어들이 동시에 실행되는 성질을 말한다. 병렬성은 데이터 병렬성(Data parallelism)과 작업 병렬성(Task parallelism)으로 구분된다.
동시성과 병렬성 올바른 개념 잡기
Thread poool 이해하기
함수의 협력 코루틴
범용프로그래밍에서 코루틴보다 서브루틴이 일반적이다. 서브루틴이란 실행이 완료된 이후에 호출자에게 반환되는 함수를 말한다. 서브루틴은 호출 사이에서 아무런 상태도 관리하지 않고 하나의 엔트리를 가지고 있다.
그에 반해 코루틴은 여러 엔트리를 가지고 있다. 코루틴은 호출 사이에 상태를 기억할 수 있으며 코루틴을 호출하면 이전 호출에서 중단된 코루틴의 중간으로 들어갈 수 있다. 이런 이유로 우리는 함수끼리 협력하는 구현을 할 수 있다.
즉, 함수들이 연결되어서 일을 한다. 두 개의 함수가 함수끼리 실행 플로우를 스위칭 하면서 동시에 실행되는 것이다.
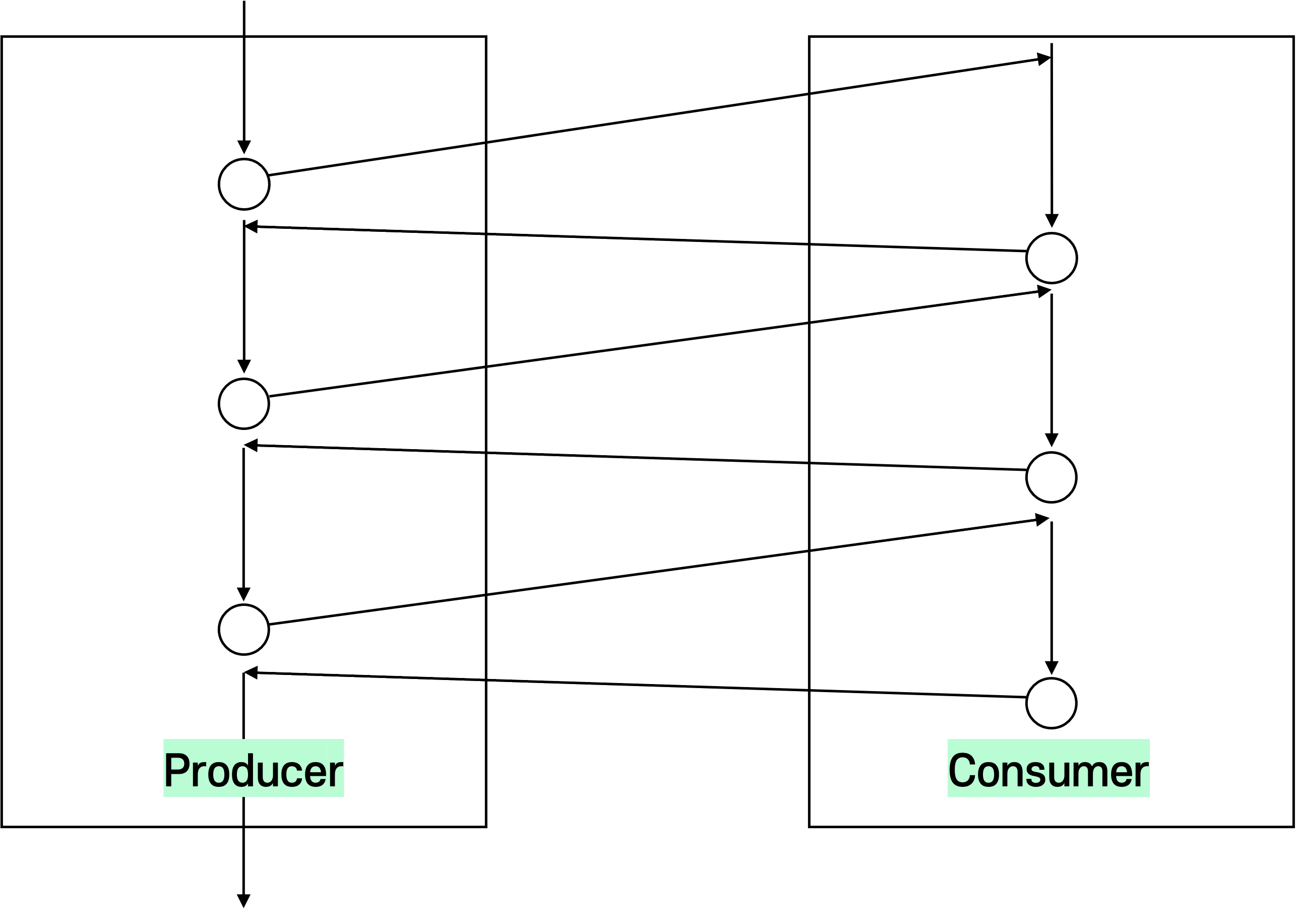
✔ Producer 코루틴이 Consumer 코루틴을 호출한다.
✔ Consumer 코드의 부분실행이 끝나면 Consumer는 현재 상태를 저장한다.
✔ Producer는 몇 단계를 수행하고 다시 Consumer에게 콜백한다.
🔥 이때 처음부터 실행 하는것이 아니라 이전 실행이 멈춘 부분부터 이전 호출의 상태를 복구하며 다시 호출한다.
📌 코루틴을 이용한 동시실행
코루틴은 서브루틴에서는 불가능한 기능을 제공해준다. 예를 들자면 코틀린은 무한 시퀀스, 이벤트 루프, 협력함수에서 사용된다.
우리는 코드가 순차적으로 실행되어야 하는지 아니면 동시에 실행되어야 하는지 그리고 현재 실행중인 컨텍스트 내에서 실행할지 아미면 분리된 코루틴에서 실행할지 결정할 수 있다.
순차적 실행으로 시작하기
✍ sequential
fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
println("end task1 in Thread ${Thread.currentThread()}")
}
fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
println("end task2 in Thread ${Thread.currentThread()}")
}
println("start")
kotlin.run {
task1()
task2()
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
task1()와 task2() 두 개의 함수는 각각 함수 실행이 시작될 때와 끝날 때의 스레드 정보를 출력한다.
💻 출력
start
start task1 in Thread Thread[main,5,main]
end task1 in Thread Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
called task1 and task2 from Thread[main,5,main]
done
예상대로 함수의 호출은 순차적으로 일어났다. task1()이 완료되고 task2()가 실행되고 완료되었다.
코루틴 만들기
이제 코루틴을 이용해 동시에 실행되도록 만들어보자
✍ coroutine
fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
println("end task1 in Thread ${Thread.currentThread()}")
}
fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
println("end task2 in Thread ${Thread.currentThread()}")
}
println("start")
runBlocking {
task1()
task2()
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
이전 코드와 차이점은 run()을 runBlocking()으로 변경했다. runBlocking() 함수는 람다를 아규먼트로 받고 코루틴에서 실행된다.
💻 출력
start
start task1 in Thread Thread[main,5,main]
end task1 in Thread Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
called task1 and task2 from Thread[main,5,main]
done
시퀀스를 이용한 버전의 출력과 코루틴을 이용한 버전의 출력이 동일해 보이지만 코루틴은 코드를 동시에 실행시킨다. 따라서 람다 안의 코드는 runBlocking() 호출 이전의 코드와 해당 함수 호출 이후의 코드 사이에서 이터리브된(interleaved) 메인 스레드에서 실행됐다.
테스크 실행
이제 두 개의 다른 코루틴으로 실행해보자
✍ coroutine
fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
println("end task1 in Thread ${Thread.currentThread()}")
}
fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
println("end task2 in Thread ${Thread.currentThread()}")
}
println("start")
runBlocking {
launch { task1() }
launch { task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
task1()과 task2() 두 함수를 launch 했다.
💻 출력
start
called task1 and task2 from Thread[main,5,main]
start task1 in Thread Thread[main,5,main]
end task1 in Thread Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
done두 테스크가 호출되었다는 메세지가 start 메세지 바로 뒤에 나왔다. task1()이 완료되고, task2()가 완료됐다.
모든 코드는 main 스레드에서 실행됐디만 우리는 람다의 마지막 라인이 task1()이나 task2()실행 되었는지 확인할 수 있다. 여기서 동시 실행을 했다는 걸 알 수 있다.
서스펜션 포인트(중단점)과 인터리빙 호출
코틀린의 코루틴 라이브러리는 서스펜션 포인트를 포함하고 있다. 서스펜션 포인트란 현재 실행중인 작업을 중지(suspend)시키고 다른 작업을 실행시키는 함수를 말한다.
kotlinx.coroutines 라이브러리는 2개의 함수를 제공한다. delay()와 yield()이다.
delay() - 현재 실행중인 작업을 지정된 밀리초만큼 멈추게 하는 함수이다.
yield() - 명시적인 지연을 만들지 않는다. 현재 작업이 더 중요한 작업들의 실행을 기다린다.
코틀린은 suspend 키워드로 어노테이트된 함수에서만 서스펜션 포인트를 사용할 권한을 준다.
✍ interleave
suspend fun task1(){
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2(){
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
println("start")
runBlocking {
launch { task1() }
launch { task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")두 함수 보두에 suspend 키워드를 달았다. 그리고 각 함수 안에서 yield()를 추가했다. 이제 각 함수는 다른 작업이 있을 경우 그 작업을 실행하도록 흐름에 맡기게 된다.
💻 출력
start
called task1 and task2 from Thread[main,5,main]
start task1 in Thread Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task1 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
donetask1()이 첫 번째 라인을 실행하고 실행 흐름을 넘겨준(yield)것을 볼 수 있다. 그 후 task2() 함수가 들어와서 첫 번째 라인을 main 스레드에서 실행시키고 다시 넘겨 주었다. 그래서 task1() 함수가 다시 실행을 다시 진행할 수 있게 되었다.
📌 코루틴의 컨텍스트와 스레드
launch() 함수와 runBlocking() 함수를 호출하면 호출자의 코루틴 스코프와 같은 스레드에서 코루틴을 실행하게된다. 왜냐하면 함수들이 함수의 스코프에서 코루틴 컨텍스트를 옮기기 때문이다.
컨택스트 명시적 세팅
우리는 CoroutineContext를 launch() 와 runBlocking() 함수에 전달해서 이 함수들이 진행시킬 코루틴의 컨텍스트를 설정할 수 있다.
CoroutineContext 타입의 아규먼트인 Dispatchers.Default의 값이 코루틴에게 DefaultDispatcher 풀의 스레드 안에서 실행하라고 지시한다. 풀 안의 스레드 숫자는 2개이거나 시스템의 코어 숫자 중 높은 것을 사용한다. 이 풀은 계산할 일이 많은 작업들을 위한 풀이다.
Dispatchers.IO : IO작업을 실행을 위한 풀 안의 코루틴을 실행시키는데 사용될 수 있다. 이 풀은 스레드가 IO에 블록될 경우와 작업이 더 생성된 경우 사이즈가 커질 수 있다.
Dispatchers.Main : 안드로이드 기기와 Swing UI에서 사용된다. 시용되는 예로는 main 스레드에서만 사용되는 UI 업데이트 기능을 실행하는 것이 있다.
✍ Dispatchers.Default
...
runBlocking {
launch(Dispatchers.Default) { task1() }
launch { task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")변경 이후에 task1()의 코드는 다른 스레드에서 실행된다. task1()을 제외한 모든 코드는 여전히 main 스레드에서 실행된다.
💻 출력
start
start task1 in Thread Thread[DefaultDispatcher-worker-1,5,main]
end task1 in Thread Thread[DefaultDispatcher-worker-1,5,main]
called task1 and task2 from Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
donerunBlocking()에 전달되는 람다 내부의 코드와 task2() 내부의 코드는 동시 실행이 된다. 하지만 task1() 내부의 코드는 병렬로 실행된다. 코루틴은 병렬 실행을 할 수도 있고, 동시 실행을 할 수도 있다. 이런 실행방식은 컨텍스트에 따라 달라진다.
커스텀 풀에서 실행시키기
코루틴을 싱글 스레드 풀에서 실행시키고 싶다면 어떻게 해야할까? 풀 안에 싱글 스레드가 있기 때문에 이 컨텍스트를 사용하는 코루틴은 병렬 실행이 아닌 동시 실행으로 진행될 것이다.
싱글 스레드 실행자를 만들기 위해서는 java.util.current 패키지의 JDK Executors 컨쿼런시 API를 시용할 수 있다.
✍ Single
import java.util.concurrent.Executors
suspend fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
Executors.newSingleThreadExecutor().asCoroutineDispatcher().use { context ->
println("start")
runBlocking {
launch(context) { task1() }
launch { task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
JDK의 Executors.newSingleThreadExecutor() 메소드를 이용해서 실행자를 만들었다. 그리고 asCoroutineDispatcher() 확장함수를 이용해서 CoroutineContext를 가지고 왔다. 그리고 use() 메소드를 호추하고 메소드에 람다를 전달했다.
람다 내부에서 우리는 contect 변수를 사용해서 컨텍스트 참조를 획득했고 참조를 launch()의 첫 호출에 전달했다. 이 launch() 호출에 의해서 시작되는코루틴은 우리가 만든 실행자에 의해서 관리되는 싱글 스레드 풀에서 실행된다. 람다 표현식이 끝날 때, use() 함수가 실행자를 닫는다.
💻 출력
start
start task1 in Thread Thread[pool-1-thread-1,5,main]
end task1 in Thread Thread[pool-1-thread-1,5,main]
called task1 and task2 from Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
donetask1()이 DefaultDispatcher 풀이 아닌 우리가 생성한 풀에서 실행된것을 확인 할 수 있다.
서스펜션 포인트 이후에 스레드 스위칭하기
코루틴을 현재 컨텍스트에서 실행시키기 위해서는 launch()의 두번째 옵셔널 전달자인 CoroutineStart 타입 옵셔널 전달인자 값을 Default로 설정해야 한다. CoroutuneStart엔 DEFAULT, LAZY, ATOMIC, UNDISPATCHED 중 하나를 선택할 수 있다.
- LAZY - 명시적으로 start() 가 호출되기 전까지 실행을 연기한다
- ATOMIC - 중단 할 수 없는 모드로 실행한다.
- UNDISPATCHED - 처음에는 현재 컨텍스트에서 실행되지만 서스펜션 포인트 이후에는 스레드를 스위치해서 실행한다.
✍ CoroutineStart.UNDISPATCHED
suspend fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors())
.asCoroutineDispatcher().use { context ->
println("start")
runBlocking {
launch(context, CoroutineStart.UNDISPATCHED) { task1() }
launch { task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
첫 번째 launch() 호출을 우리의 스레드풀에서 실행시키도록 변경하고 두 번째 아규먼트로 UNDISPATCHED 옵션을 준다.
💻 출력
start
start task1 in Thread Thread[main,5,main]
end task1 in Thread Thread[pool-1-thread-1,5,main]
called task1 and task2 from Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]
donetask1() 실행이 시작죌 때 pool-1의 스레드가 아니고 main 스레드에서 시작되는 것을 볼 수 있다. 실행 중 서스펜션 포인트 yield()를 만나면 스레드가 launch() 함수에 명시된 컨텍스트의 스레드인 pool-1의 스레드로 스위치되어 실행된다.
코루틴 컨텍스트 변경
withContext() 함수를 이용하면 코드의 한 부분을 코루틴의 다른 코드들과 완전히 다른 컨텍스트에서 실행시킬 수 있다.
✍ withContext()
suspend fun task1() {
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2() {
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors())
runBlocking {
println("starting in Thread ${Thread.currentThread()}")
withContext(Dispatchers.Default) { task1() }
launch { task2() }
println("ending in Thread ${Thread.currentThread()}")
}
💻 출력
starting in Thread Thread[main,5,main]
start task1 in Thread Thread[DefaultDispatcher-worker-1,5,main]
end task1 in Thread Thread[DefaultDispatcher-worker-1,5,main]
ending in Thread Thread[main,5,main]
start task2 in Thread Thread[main,5,main]
end task2 in Thread Thread[main,5,main]withContext() 전달된 람다 코드를 제외한 모든 코드가 main 스레드에서 동작하고 있고 withContext()에 전달된 람다에서 호출된 코드는 제공된 컨텍스트의 스레드에서 동작하는걸 볼 수 있다.
📌 async와 await
작업을 비동기로 실행하고 실행결과도 받고 싶다면 launch() 대신 async()를 시용해야 한다. async() 함수는 launch()와 동일한 파라미터를 받는다. 그래서 같은 방식으로 컨텍스트와 속성을 구성할 수 있다.
async( )와 launch( ) 차이점은 async()는 Deferred<T> 퓨처 객체를 리턴 한다는 점이다. 퓨처 객체는 코루틴의 상태체크, 취소 등을 할 수 있는 await() 메소드를 가지고 있는 객체이다.
await() 메소드는 스레드의 실행은 차단하지 않으면서 실행의 흐름을 차단한다. 그래서 호출자의 코드와 async()로 실행된 코루틴의 코드는 동시 실행이 가능하다.
await() 메소드의 호출은 결국 async()로 시작된 코루틴의 결과를 리턴받는다. async()로 시작된 코루틴이 예외를 던지면 예외는 await() 함수를 통해서 호출자에게까지 전파된다.
✍ withContext()
runBlocking {
val count: Deferred<Int> = async(Dispatchers.Default) {
println("fetching in ${Thread.currentThread()}")
Runtime.getRuntime().availableProcessors()
}
println("Called the function is ${Thread.currentThread()}")
println("Number of cores is ${count.await()}")
}
위 코드에서는 현재 사용 가능한 코어의 숫자를 비동기적으로 가져오게 된다. 싱글스레드 스코프를 사용하고 코루틴은 호출자와 동일한 스레드에서 동작할 것이다.
일단 요청이 전달되면 main 스레드가 async() 호출 이후에 print문을 실행시킨다. await() 메소드를 호출하면 async()에 의해서 실행된 코루틴이 완료되기를 기다리게 만든다.
💻 출력
Called the function is Thread[main,5,main]
fetching in Thread[DefaultDispatcher-worker-1,5,main]
Number of cores is 12출력이 시스템의 코어 숫자를 보여주고 코루틴이 DefaultDispatcher 풀의 스레드에서 실행된 것을 볼 수 있다.
📌 연속성 살펴보기
✍ Compute
class Compute {
fun compute1(n: Long): Long = n * 2
suspend fun compute2(n: Long): Long {
val factor = 2
println("$n received : Thread ${Thread.currentThread()}")
delay(n * 1000)
val result = n * factor
println("$n, returning $result: Thread: ${Thread.currentThread()} ")
return result
}
}
Comput 클래스는 두 개의 메소드를 가지고 있고 그 중 하나는 suspend로 마크되어 있다. compute1() 메소드는 주어진 입력을 두 배로 만들어서 리턴한다. compute2()는 동일한 동작을 한다.
✍ UseCompute
fun main() = runBlocking<Unit> {
val compute = Compute()
launch(Dispatchers.Default) { compute.compute2(2) }
launch(Dispatchers.Default) { compute.compute2(1) }
}
💻 출력
2 received : Thread Thread[DefaultDispatcher-worker-1,5,main]
1 received : Thread Thread[DefaultDispatcher-worker-2,5,main]
1, returning 2: Thread: Thread[DefaultDispatcher-worker-2,5,main]
2, returning 4: Thread: Thread[DefaultDispatcher-worker-2,5,main]
입력값 2로 compute2()를 실행시키는 코루틴은 스레드가 변경되었다. delay() 실행 후부터 다른 스레드에서 동작한다. 하지만 factor의 값은 delay() 전부터 delay() 후까지 정확하게 전달되었다. 이것을 '컨테뉴에이션'이라고 부른다.
아주 강력한 데이터 구조인 컨테뉴에이션을 사용하면 프로그램은 한 스레드에서 실행 상태를 포착하고 보존할 수 있다. 그리고 그 상태를 다른 스레드에서 필요로 할 때 불러올 수 있다.
📌 무한 시퀀스 만들기
시퀀스 사용
코틀린 라이브러리에는 sequence 함수가 있다. sequence 함수는 연속된 값을 만들 때 바로 사용할 수 있는 함수다.
primes() 함수는 시작 숫자를 받은 후 Sequence<Int>를 리턴해준다. Sequence는 컨티뉴에이션처럼 동작하고 반복을 위해서 값을 내보낸다.
✍ primes
fun primes(start: Int): Sequence<Int> = sequence {
println("Starting to look")
var index = start
while (true) {
if (index > 1 && (2 until index).none { i -> index % i == 0 }) {
yield(index)
println("Generating next after $index")
}
index++
}
}
sequence() 함수에 전달된 람다에서 우리는 소수를 찾고 yield() 메소드를 사용해서 내보내는 것을 볼 수 있다. 여기서 yield()는 스탠다드 라이브러리으 yield()로 코루틴 라이브러리의 yield()와 다르다.
for (prime in primes(start = 17)) {
println("Received $prime")
if (prime > 30) break
}반복의 모든 단계에서 제어의 흐름이 primes() 함수로 이동하고 이전에 떠났던 곳으로 돌아온다.
💻 출력
Starting to look
Received 17
Generating next after 17
Received 19
Generating next after 19
Received 23
Generating next after 23
Received 29
Generating next after 29
Received 31
sequence() 함수는 3개의 장점을 제공해준다.
- 콜렉션을 미리 만들 필요가 없다. 그러므로 연산에 얼마나 많은 값을 사용하게 될지 알 필요가 없다.
- 시간이 흐를수록 값을 생성하느라 들어간 시간을 아낄 수 있고, 이미 생성된 값을 사용하겐 된다.
- 시리즈 값의 생성이 필요할 때만 생성되기 때문에 우리는 사용도 안될 값을 생성하는 상황을 피할 수 있다.
그 결과로 코드가 더욱 효율적이게 되고 Iterable/Iterator 클래스를 만들 때 이 기술을 적용하기 쉽다.
이터레이터 함수 사용하기
서드파티-클래스-인젝팅 에서 구현한 ClosedRange<String> 클래스의 확장함수를 다시 구현해보자.
✍ forstringrange
operator fun ClosedRange<String>.iterator() =
object : Iterator<String> {
private val next = StringBuilder(start)
private val last = endInclusive
override fun hasNext() =
last >= next.toString() && last.length >= next.length
override fun next(): String {
val result = next.toString()
val lastCharacter = next.last()
if (lastCharacter < Char.MAX_VALUE) {
next.setCharAt(next.length - 1, lastCharacter + 1)
} else {
next.append(Char.MIN_VALUE)
}
return result
}
}
ClosedRange<String>의 iterator() 함수는 Iterator<String> 인터페이스를 구현한 객체를 리턴한다. Iterator 인터페이스는 2개의 속성과 2개의 메소드를 구현해야 한다. hasNext()는 반복을 위한 다른 값이 있는지를 알려준다. 그리고 next()는 다음 값을 리턴해준다.
코루틴을 사용하면 좀 더 효율적으로 만들 수 있다.
✍ forstringrange
operator fun ClosedRange<String>.iterator(): Iterator<String> = iterator {
val next = StringBuilder(start)
val last = endInclusive
while (last >= next.toString() && last.length >= next.length) {
val result = next.toString()
val lastCharacter = next.last()
if (lastCharacter < Char.MAX_VALUE) {
next.setCharAt(next.length - 1, lastCharacter + 1)
} else {
next.append(Char.MIN_VALUE)
}
yield(result)
}
}
for (word in "hell".."help") {
print("$word, ")
}
Sequence<T>를 리턴하는 sequence 함수와 다르게 iterator() 함수는 Iterator<T>를 리턴한다. iterator() 함수에 전달된 람다 내부에서 우리는 반복하면서 순서대로 String을 만들어낸다.
그리고 yield() 함수를 호출하여 생성된 String을 sequence() 함수를 호출한 곳으로 리턴한다.
hasNext()는 사라졌고 next() 메소드에서 return 대신 yield() 함수를 사용했다.
🔑 정리
코루틴은 컨테뉴에이션의 개념을 기반으로 태어났고 코루틴은 동시성 프로그래밍을 만들기 위한 좋은 방법이다.
코루틴은 다중 엔트리포인트(진입점)를 가지고 있고 호출들 사이에서 상태를 전달할 수 있다. 이런 함수들은 서로 호출을 할 수 있고 이전 호출에서 중단된 부분부터 다시 실행을 재개할 수 있다
코루틴은 실행되고 있는 스레드를 변경할 수 있고, async()/await()를 사용하면 병렬로 실행한 후 나중에 결과를 받을 수 있다.
출처 : 다재다능 코틀린 프로그래밍
