
📌 연산자 오버로딩
연산자 오버로딩은 언어가 유저가 정의한 데이터 타입에 연산자를 사용하기 위해서 확장한 기능이다.
bigInteger1.multiply(bigInteger2)
bigInteger1 * bigInteger2첫 줄은 JDK의 multiply 메소드를 사용한 것이다. 두 번째 줄은 BigInteger의 인스턴스에 연산자를 사용한 것이다.
두 연산 모두 같은 결과를 만들지만 연산자를 사용한 코드가 더 자연스러워 보이며 유창성을 가질 뿐 아니라, multiply() 메소드를 사용한 것에 비해서 코드가 적다.
코틀린에서는 +,-,* 같은 연산자를 숫자 타입에만 사용하는 것에 추가적으로 연산자를 오버로딩해서 객체에서 사용할 수 있다. JVM이 연산자 오버로딩을 지원하지 않기 때문에 코틀린은 연산자 오버로딩을 지원하기 위해서 연산자를 특별히 망명된 메소드에 맵핑한다.
연산자를 오버로딩하기 위해서, 함수는 operator 키워드로 정의되어 있어야 한다.
✍ + 오버로딩
operator fun Pair<Int,Int>.plus(other:Pair<Int,Int>)=
Pair(first+other.first,second+other.second)함수의 이름은 plus()이다. plus()는 +를 위한 메소드 이름이다. plus() 확장 함수는 주어진 페어의 첫 번째 값을 합친 값과 두 번째 값을 각각 합친 값으로 만들어진 새로운 Pair<Int,Int> 객체를 리턴한다.
직접 만든 클래스에서 연산자를 오버로닝하기 위해서, 적절한 특화된 메소드를 클래스의 멤버함수로 작성해야 한다.
✍ * 오버로딩
data class Complex(var real: Int, val imaginary: Int) {
operator fun times(other: Complex) =
Complex(real * other.real - imaginary * other.imaginary, real * other.imaginary + imaginary * other.real)
private fun sign() = if (imaginary < 0) "-" else "+"
override fun toString(): String = "$real ${sign()}${abs(imaginary)}i "
}
println(Complex(4, 2) * Complex(-3, 4))
println(Complex(1, 2) * Complex(-3, 4))
💻 출력
-20 +10i
-11 -2i 연산자와 대응하는 메소드들의 종류는 여러가지다.
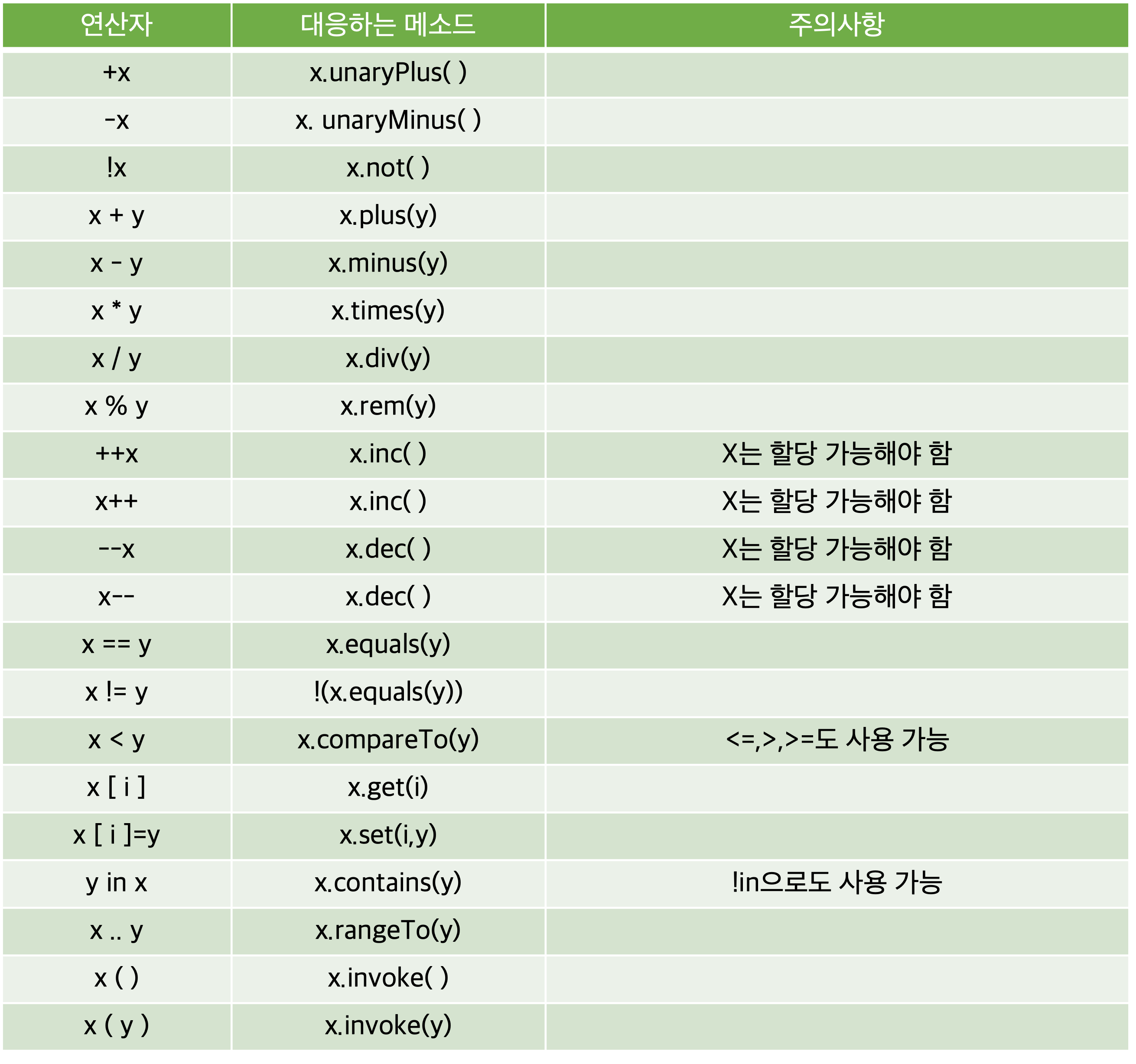
+=, -=, *=, /=, %= 같은 혼합된 연산자를 위한 함수는 첫 번째 연산자의 특화된 메소드명 뒤에 Assign을 붙이면 된다. 예를들어 plusAssign()은 +=을 뜻하는 메소드명이다. 한 클래스에서 Plus(), plusAssign()을 보두 구현할 필요는 없다. 만약 plus()를 구현해 놨다면 +=는 Plus() 메소드를 적절하게 사용할 것이다.
연산자를 오버로딩할 때는 지켜야할 규칙이 있다. 개발자는 연산자의 동작의 관행을 따라야 한다. 예를 들어서 + 나 - 연산자를 오버로딩할 때 객체를 변경하면 안된다.
✍ inc(), dec()
class Counter(val value: Int) {
operator fun inc() = Counter(value + 1)
operator fun dec() = Counter(value - 1)
override fun toString() = "$value"
}
var counter=Counter(2)
println(counter) //2
println(++counter) //3
println(counter) //3
println(counter++) //3
println(counter) //4inc() 메소드에서 우리는 아무것도 변형시키지 않았다. 그대신 새로운 상태를 가진 새로운 객체를 리턴했다. 선 증가연산으로 사용될 때 코틀린은 연산자에 적용된 변수에 리턴해야 하는 값을 저장해놓는다.
연산자 오버로딩은 강력한 기능이다. 하지만 사용할때에 주의해야할 점이 있다.
- 절제하여 사용해라.
- 코드를 읽는 사람 입장에서 당연하게 받아들여질 경우에만 사용해라.
- 변수이름을 의미있게 만들어라. 그래야 오버로딩의 문맥을 파악하기 좋다.
- 오버로딩된 연산자는 일반적인 연산자의 동작이어야 한다.
📌 확장 함수와 속성을 이용한 인젝팅
코틀린은 개발자에게 다른 JVM언어에서 작성된 클래스를 포함된 모든 클래스에 메소드와 속성을 인젝팅할 수 있는 권한을 준다. 코틀린은 인젝션을 런타임 패치나 클래스 로딩없이 수행한다. 코틀린에서 클래스는 확장에는 열려있다. 상속이 불가능한 클래스 역시 확장에는 열려있다.
클래스의 확장함수를 만들면 해당 클래스의 인스턴스 메소드를 만든 것처럼 보인다. 클래스에 이미 존재하는 메소드를 확장 함수로 만들면 안된다. 충돌이 있는 경우에 클래스의 멤버 함수가 항상 확장 함수를 이긴다.
이미 존재하는 클래스에 메소드와 속성은 인젝팅할 수 있다. 여기엔 final 클래스도 포함되고, 직접 작성하지 않은 클래스도 포함된다.
확장 함수를 이용한 메소드 인젝팅
✍ circle
data class Point(val x: Int, val y: Int)
data class Circle(val cx: Int, val cy: Int, val radius: Int)이 클래스들 서로 독립적이며 아무런 메소드도 가지고 있지 않다.
만약 점이 원안에 있는지 확인하는 메소드를 만들고 싶다면 각 클래스 내부에 메소드를 만들 필요는 없다. 우리가 직접 메소드를 추가할 수 있기 때문이다 .
fun Circle.contains(point: Point) =
(point.x - cx) * (point.x - cx) + (point.y - cy) * (point.y - cy) < radius * radius
이 코드는 모든 클래스의 바깥에 존재한다. 패키지의 top-level에 존재한다는 의미이다. contains() 확장 함수 안에 우리는 암시적으로 Circle 클래스의 인스턴스에 접근한다. 클래스 내부에 인스턴스 메소드로 정의되었을 때와 동일하게 접근하는 것이다.
이 메소드는 같은 파일이거나 임포트한 경우 항상 사용할 수 있다.
val circle = Circle(100, 100, 25)
val point1 = Point(110, 110)
val point2 = Point(10, 100)
println(circle.contains(point1)) //true
println(circle.contains(point2)) //false
Circle에는 contains() 메소드가 없지만 Circle클래스의 인스턴스에서 해당 메소드를 호출할 수 있다. 코틀린의 확장 함수는 패키지의 static 메소드로 만들어진다. 확장 함수를 사용할 때 메소드 호출로 보이는 과정은 사실 static 메소드를 호출하는 과정과 동일하다.
확장 함수를 이용한 연산자 인젝팅
확장 함수는 연산자 역시 될 수 있다. 위에서 연산자 in은 contains() 메소드와 맵핑된다는것을 보았다. Circle 클래스의 contains 메소드에 operator 어노테이션을 붙여보자
operator infix fun Circle.contains(point: Point) =
(point.x - cx) * (point.x - cx) + (point.y - cy) * (point.y - cy) < radius * radius
println(circle.contains(point1))
println(circle contains point2)
단순히 확장함수 앞에 operator 키워드를 더해줬다.
println(circle.contains(point1)) //true
println(point1 in circle) //true
println(point2 in circle) //false
확장 속성을 이용한 속성 인젝팅
확장 속성은 클래스 내부에 존재하는 것이 아니기 때문에, 백킹 필드를 가질 수 없다. 확장 속성은 클래스의 다른 속성이나 메소드를 이용해서 작업을 완료할 수 있다.
✍ area 속성 추가
val Circle.area: Double
get() = PI * radius * radius
val circle = Circle(100, 100, 25)
println("Area is ${circle.area}") //Area is 1963.4954084936207
var 로 정의된 속성에는 setter도 사용할 수 있다. setter는 클래스의 다른 메소드에 의존하게 된다.
서드파티 클래스 인젝팅
확장 함수를 서드파티 클래스에 추가할 수도 있고, 이미 존재하는 메소드로 확장 함수를 라우팅할 수도 있다.
//팰린드롬(palindrome)은 거꾸로 읽어도 제대로 읽는 것과 같은 문장이나 낱말, 숫자, 문자열
fun String.isPalindrome(): Boolean {
return reversed() == this
}
isPalindrome( ) 메소드는 코틀린의 확장 함수인 reversed()를 이용해서 주어진 문자열이 Palindrome인지 결정한다.
fun String.shout() = uppercase()
val str = "dad"
println(str.isPalindrome()) //true
println(str.shout()) //DAD✍ iterator() : ERROR
for(word in "hell" .. "help") { print("$word, ")} //ERROR
//for-loop range must have an 'iterator()' method
에러 메세지를 보면 컴파일러가 CloseRanged<String>클래스에서 iterator() 메소드를 찾을수 없다고 나온다. iterator() 메소드를 클래스로 인젝팅하면 해결된다.
iterator( ) 인젝팅 시 도움 될 사항
- 반복자를 만들 때는 익명객체로 만들 수 있다.
- start 속성을 이용해서 range의 첫 요소에 접근할 수 있고, CloseRanged<T> 클래스의 endlnclusive를 이용해서 마지막 요소에 접근할 수 있다.
- 코틀린은 >= 연산자를 사용하면 compareTo() 메소드를 실행한다.
- 뮤터블 String을 사용하기 위해서 JDK의 StringBuilder 클래스를 사용할 수 있다.
- kotlin.Char의 + 연산자는 다음 문자를 가져오기 위해 사용된다. 우리는 + 연산자를 StringBuilder의 마지막 캐릭터를 증가시키기 위해서 사용한다.
iterator() 확장 함수를 만들자
✍ iterator() 확장 함수
operator fun ClosedRange<String>.iterator() =
object : Iterator<String> {
private val next = StringBuilder(start)
private val last = endInclusive
override fun hasNext() =
last >= next.toString() && last.length >= next.length
override fun next(): String {
val result = next.toString()
val lastCharacter = next.last()
if (lastCharacter < Char.MAX_VALUE) {
next.setCharAt(next.length - 1, lastCharacter + 1)
} else {
next.append(Char.MIN_VALUE)
}
return result
}
}
for (word in "hell".."help") {
print("$word, ") // hell, helm, heln, helo, help,
} 이번에는 에러가 발생하지 않는다.
Static 메소드 인젝팅
클래스의 컴패니언 객체를 확장해서 static 메소드를 인젝팅할 수 있다. 즉 메소드를 클래스가 아니라 컴패니언에 인젝팅한다는 의미이다.
✍ 컴패니언
fun String.Companion.toUrl(link: String) = java.net.URL(link)
val url: URL = String.toUrl("https://naver.com")코틀린의 모든 서드파티 클래스에 static 메소드를 추가할 수 없다. 컴패니언 클래스가 있는 클래스만 추가할 수 있다.
클래스 내부에서 인젝팅
지금까지 모든 확장 함수는 탑레벨에서 인젝팅했다. 즉, 확장 함수를 모두 클래스 외부에서 추가했다는 의미이다. 확장 함수는 클래스 내부에서도 인젝트할 수 있다.
확장 함수를 클래스 안에서 만든다면 해당 확장 함수는 해당 클래스와 해당 클래스의 이너 클래스에서만 볼 수 있다. 또한 확장 함수 안에는 2개의 리시버가 있다. 즉, 2개의 this 컨텍스트 객체가 있다는 의미이다.
위에서 만든 Point 클래스를 변경해보자
Point 클래스의 주 생성자는 2개의 파라미터 x,y를 받는다. x와 y를 속성 대신 파라미터로 만든 다음에 두 파라미터를 Pair<Int,Int>에 저장한다.
✍ inner extension
class Point(x: Int, y: Int) {
private val pair = Pair(x, y)
private val firstSign = if (pair.first < 0) "" else "+"
private val secondSign = if (pair.second < 0) "" else "+"
override fun toString() = pair.point2Stirng()
fun Pair<Int, Int>.point2Stirng() =
"${firstSign}${first}, ${this@Point.secondSign}${this.second}"
}
println(Point(1, -3))
println(Point(-3, 4))Point 클래스에서 Pair<Int,Int>로 확장 함수를 인젝트했다. 그렇기 때문에 클래스 외부에서 Pair<Int,Int>의 확장 함수를 사용하려고 하면 컴파일 에러가 난다.
fun Pair<Int, Int>.point2Stirng() =
"${firstSign}${first}, ${this@Point.secondSign}${this.second}"
}확장 함수가 클래스 내부에 생성되었기 때문에 확장 함수에는 this 와 this@Point 두개의 리시버를 가지고있다. 하나는 익스텐션 리시버이고 다른 하나는 디스패치 리시버이다.
익스텐션 리시버는 확장함수를 리시브하는 객체라이고 디스패치 리시버는 확장 함수를 만들어 추가한 클래스의 인스턴스 이다.
메소드 안에서 first는 익스텐션 리시버인 Pair<Int,Int>의 속성에 바인딩된다. 이와 유사하게, this.second는 위와 같은 인스턴스의 second 속성에 바인딩 된다. 익스텐션 리시버를 바이패스한 후 디스패치 리시버에 참조를 걸고 싶다면 this@Outer 문법은 사용하면 된다.
📌 함수 확장
코틀린에서 함수는 객체이다. 우리는 클래스에 메서드를 인젝트한 것처럼 함수에도 메소드를 인젝트할 수 있다. 코틀린은 andThen() 메소드를 가지고 있지 않다. 하지만 우리는 코틀린의 함수에 andThen() 메소드를 인젝트할 수 있다.
✍ andThen()
fun <T, R, U> ((T) -> (R)).andThen(next: (R) -> (U)): (T) -> U =
{ input: T -> next(this(input)) }
fun increment(number: Int): Double = number + 1.toDouble()
fun double(number: Double) = number * 2
val incrementAndDouble = this::increment.andThen { this::double }
println(incrementAndDouble(5))
확장 함수의 시그니처를 보면 T타입 파라미터를 받고, R타입을 리턴하는 andThen()이 추가 됐다는 것을 알 수 있다. andThen()으로 전달 될 파라미터는 타입 R을 파라미터로 받는 함수여야 한다. 그리고 andThen()에 전달될 함수는 U타입을 리턴한다. andThen()에 의해서 생성된 함수의 결과는 T타입의 파라미터를 받고, U타입을 리턴하게 된다. 이 람다는 자신의 파라미터를 andThen()이 호출된 함수로 전달하고 그 결과를 next함수로 전달한다.
fun increment(number: Int): Double = number + 1.toDouble()
fun double(number: Double) = number * 2increment()의 결과를 double() 함수와 함께 사용하기 위해서 andThen()을 호출할 수 있다.
val incrementAndDouble = this::increment.andThen { this::double }
println(incrementAndDouble(5)) //12.0::구문을 이용한 increment()의 참조에 andThen()메소드를 호출했고, double() 메소드에 참조를 넘겼다. 이런 동작의 결과는 increment()와 double()을 합친 함수가 됐다.
📌 infix를 이용한 중위표기법
연산자가 중간에 있거나 피연산자 사이에 있는 것을 중위표기법이라고 부른다. 중위표기법은 이해하기 쉬운 코드로 만들어준다.
println(circle.contains(point1))
println(point2 in circle)
contains() 대신 in 을 사용하는 것처럼 메소드에 infix 어노테이션을 사용하면 코틀린은 점과 괄호를 제거하는 것을 허용해준다. infix는 operator와 함께 사용할 수 있다.
✍ infix
operator infix fun Circle.contains(point: Point) =
(point.x - cx) * (point.x - cx) + (point.y - cy) * (point.y - cy) < radius * radius
println(circle.contains(point1))
println(circle contains point2)📌 Any 객체를 이용한 자연스러운 코드
코틀린은 코드를 풍부하게 해주는 4가지의 특별한 메소드를 가지고 있다. also(), apply(), let(), run() 이다. 각각의 메소드는 람다 표현식을 파라미터로 받고, 전달받은 람다를 실행하고 객체를 리턴해준다.
4가지 메소드의 동작
✍ any method
val format = "%-10s%-10s%-10s%-10s"
val str = "context"
val result = "RESULT"
fun toString() = "lexical"
println(
String.format(
"%-10s%-10s%-10s%-10s%-10s", "Method", "Argument", "Receiver", "Return", "Result"
)
)
println("================================================")
val result1 = str.let { arg ->
print(String.format(format, "let", arg, this, result))
result
}
println(String.format("%-10s", result1))
val result2 = str.also { args ->
print(String.format(format, "also", args, this, result))
result
}
println(String.format("%-10s", result2))
val result3 = str.run {
print(String.format(format, "run", args, this, result))
result
}
println(String.format("%-10s", result3))
val result4 = str.apply {
print(String.format(format, "apply", args, this, result))
result
}
println(String.format("%-10s", result4))💻 출력
Method Argument Receiver Return Result
================================================
let context lexical RESULT RESULT
also context lexical RESULT context
run N/A context RESULT RESULT
apply N/A context RESULT context let() 메소드는 컨텍스트 객체를 아규먼트로 람다에 전달했다. 함다의 this의 스코프는 렉시컬 스코프이고, this는 람다가 정의된 스코프에 바인딩된다. 람다가 리턴한 결과가 let()의 호출 결과로 리턴된다.
also() 메소드 역시 컨텍스트 객체를 람다의 아규먼트로 전달한다. 그리고 리시버 역시 렉시컬 스코프로 인해서 람다가 정의된 곳의 this가 사용된다. 하지만 let() 과 다르게 also() 메소드는 람다의 결과를 무시하고 컨텍스트 객체를 result로 리턴한다. also()가 전달받은 람다의 리턴타입은 Unit이다. 그래서 result의 리턴이 무시되는 것이다.
run() 메소드는 람다에 아규먼트를 전달하지 않는다. 하지만 컨텍스트 객체를 람다의 this에 바인딩한다. 람다가 리턴한 것이 run()의 결과로 리턴된다.
apply() 메소드 역시 람다에 아무런 아규먼트도 안넘긴다. 람다의 this에 컨텍스트 객체를 바인딩한다. 하지만 run()과 다르게 apply() 메소드는 람다의 결과를 무시하고 컨텍스트 객체를 호출자에게 리턴한다.
- 4개의 메소드 모두 전달받은 람다를 실행시킨다.
- let()과 run()은 람다를 실행시키고 람다의 결과를 호출한 곳으로 리턴한다.
- also() 와 apply()는 람가의 결과를 무시하고 컨택스트 객체를 호출한 곳으로 리턴한다.
- run()과 apply()는 run()과 apply()를 호출한 컨텍스트 객체의 실행 컨텍스트를 this로 사용하여 실행시킨다.
🔥 여기서 중요한 것은 각 메소드는 리시버(this)가 다르고, 메소드로부터 리턴되는 것들이 다르다는 것이다.
장황하고 지저분한 코드로부터
4개의 메소드를 이용하면 코드를 풍부하게 만들 수 있다. 일단 Mailer 클래스를 만들어보자.
✍ Mailer
class Mailer {
val detail = StringBuilder()
fun from(addr: String) = detail.append("from $addr...\n")
fun to(addr: String) = detail.append("to $addr...\n")
fun subject(line: String) = detail.append("subject $line...\n")
fun body(message: String) = detail.append("body $message...\n")
fun send() = "...sending...\n$detail"
}
val mailer = Mailer()
mailer.from("builder@agliedeveloper.com")
mailer.to("venkats@agliedeveloper.com")
mailer.subject("Your code bad")
mailer.body("detail")
val mail = mailer.send()
println(mail)다소 장황한 코드로 이루어져있다.
💻 출력
...sending...
from builder@agliedeveloper.com...
to venkats@agliedeveloper.com...
subject Your code bad...
body detail...코드는 동작하지만 Mailer의 메소드를 호출하는 것인 너무 지저분하고, 반복적이다.
apply()를 이용한 반복 참조 제거
apply() 메소드는 람다를 apply()를 호출한 객체의 컨텍스트에서 실행하고, 컨텍스트 오브젝트를 호출한 객체로 다시 리턴해준다
✍ apply()
val mailer = Mailer()
.apply { from("builder@agliedeveloper.com") }
.apply { to("venkats@agliedeveloper.com") }
.apply { subject("mailerApply") }
.apply {
body("detail")
}
val mail = mailer.send()
println(mail)메소드를 호출한 Mailer 인스턴스에 리턴을 해주는 Mailer 와 클래스의 메소드는 하나도 없다. 즉, Mailer의 메소드에 다중 호출을 만들 수가 없다는 뜻이다. apply()는 이런 이슈를 잘 해결해준다. apply()는 하나의 Mailer 인스턴스에서 인스턴스를 참조하고 있는 이름의 반복적인 사용 앖이 연속적으로 메소드를 호출할 수 있다. 참조명의 반복이 적어졌다는 좋은 점이 있지만 apply()의 반복으로 지저분해졌다.
apply() 메소드는 apply()를 마지막으로 호출한 객체의 컨텍스트레서 람다를 실행시킨다. 그 래서 우라는 apply()에 전잘하는 람다에서 Mailer에 여러번 메소드 호출을 사용할 수 있다.
val mailer = Mailer()
.apply {
from("builder@agliedeveloper.com")
to("venkats@agliedeveloper.com")
subject("mailerApply2")
body("detail")
}
val mail = mailer.send()
println(mail)run을 이용한 결과 얻기
이전 예제에서 Mailer의 메소드를 여러번 콜했지만 최종적으로 원했던 것은 send() 메소그를 호출 하는 것이었다. 만약 메소드가 수행된 이후에도 Mailer의 참조가 유지되고, 해장 인스턴스로 다른 일을 더 할 수 있도록 하는거라면 apply() 메소드가 좋은 선택이지만 호출 이후에 더 이상 쓸 일이 없다면 run()을 사용할 수 있다. apply()와 다르게 run() 메소드는 람다의 결과를 리턴해준다. apply()와 동일한 점은 타깃 객체의 컨텍스트에서 람다를 실행 시킨다는 점이다.
✍ Run()
val mailer = Mailer()
.run {
from("builder@agliedeveloper.com")
to("venkats@agliedeveloper.com")
subject("mailerRun")
body("detail")
send()
}
println(mailer)Mailer 인스턴스는 run() 메소드의 타깃으로 사용되었다. send() 의 결과응 run() 메소드에 의해서 호출자에게 리턴된다. run()에서 사용된 Mailer 인스턴스는 더 이상 사용 불가능하다.
✔ 연속적으로 메소드 호출을 하고 마지막에 타깃 객체를 유지하고 싶다면 apply()를 사용해라
✔ 마지막에 타깃 객체가 아닌 람다 표현깃의 결과를 유지하고 싶다면 run()을 사용해라
apply() 또는 run()을 사용할땐 모두 람다를 타깃 객체의 컨텍스트에서 사용하거 싶은 경우에만 사용해야 한다.
let을 이용해 객체를 아규먼트로 넘기기
함수에서 인스턴스를 받았지만 해당 인스턴스를 다른 메소드의 아규먼트로 전달하고 싶다고 가정해보자. 이런 연산의 순서는 코드의 자연스러운 흐름을 깨버리지만 let() 메소드가 해결해 줄 수 있다.
✍ Mailer() 객체를 파라미터로 받는 함수
fun createMailer() = Mailer()
fun prepareAndSend(mailer: Mailer) = mailer.run {
from("builder@agliedeveloper.com")
to("venkats@agliedeveloper.com")
subject("prepareAndSend")
body("detail")
send()
}두 함수를 이용하는 코드를 보자
val mailer = createMailer()
val result = prepareAndSend(mailer)
println(result)createMailer() 결과를 변수에 저장한다. 그리고 그 변수를 prepareAndSend()에 전달하여 그 결과를 result라는 변수에 저장해서 마지막으로 출력할 때 사용한다. 코드의 흐름이 자연스럽지 못하다.
두 함수 호출을 이렇게 변경 가능하다.
val result = prepareAndSend(createMailer()) 여전히 코드의 자연스러움이 없다. 여러 개의 괄호가 매우 무겁게 느껴진다.
let()을 이용하면 메소드를 호출 한 후 다음 메소드로의 연결이 편해진다.
✍ let()
val result = createMailer().let { mailer ->
prepareAndSend(mailer)
}createMailer()을 결과에서 let()을 호출하고 let() 함수에 람다 표현식을 전달한다. 람다에서 Mailer 인스턴스는 let()의 타깃 인스턴스인 createMailer()의 결과물이다. Mailer 인스턴스는 prepareAndSend() 함수에 전달됐다.
전보다 자연스러워 보이지만 아직 부족하다. 여기서 파라미터 이름을 제거해주자.
val result = createMailer().let {
prepareAndSend(it)
}조금 나아보인다. 여기서 람다는 파라미터를 전달박도, 그 파라미터를 prepareAndSend() 메소드로 다시 전달한다. 여기에 람다를 사용하는 대신 메소드를 사용할 수 있다.
val result = createMailer().let(::prepareAndSend)createMailer()의 결과는 let으로 전달되고, let()은 전달받은 파라미터를 다시 prepareAndSend() 메소드에 전달한다. 그리고 함수가 뭘 리턴하던 상관없이, let()은 함수가 리턴한 것을 호출자에게 다시 리턴한다.
also를 사용한 함수 체이닝
also() 메소드는 체이닝을 사용할 수 없는 void 함수를 체이닝 하려고 할 때 유용하다.
✍ void
fun prepareMailer(mailer: Mailer): Unit {
mailer.run {
from("builder@agliedeveloper.com")
to("venkats@agliedeveloper.com")
subject("prepareMailer")
body("detail")
send()
}
}
fun sendMail(mailer: Mailer): Unit {
mailer.send()
println("Mailer sent")
}
리턴이 없는 함수들에서 Mailer() 인스턴스를 전달한다.
val mailer = createMailer()
prepareMailer(mailer)
sendMail(mailer)also()를 이용하면 함수 호출을 할 때 체이닝을 사용할 수 있다. also()가 타깃 객체를 람다 파라미터에 전달하고, 람다의 리턴을 무시한 후 타깃을 가시 호출한 곳으로 리턴하기 때문이다.
✍ also
createMailer().also(::prepareMailer).also(::sendMail)📌 암시적 리시버
let() 이나 also() 메소드와 다르게 run() 이나 apply() 메소드는 타깃 컨텍스트에서 람다를 실행시킨다. 코틀린은 언어나 라이브러리를 구현체들이 각 구현체들 안에서만 실해되는 것이 아니고 언어를 사용하는 모두에게 접근 권한을 주었다.
리시버 전달
✍ lambda
val length = 100
val printIt: (Int) -> Unit = { n: Int ->
println("n is $n, length is $length")
}
printIt(6)printIt 은 람다를 참조한다. 람다는 Int를 파라미터로 받고 , 아무것도 리턴하지 않는다. 람다에서 length라는 이름의 속성을 프린트하고, 파라미터 이름은 n이다.
람다 내부에는 length가 없지만 렉시컬 스토프의 변수에서 length를 찾을 수 있다.
💻 출력
n is 6, length is 100
코틀린은 람다에 리시버를 세팅하는 좋은 기능을 제공한다.
val length = 100
val printIt: String.(Int) -> Unit = { n: Int ->
println("n is $n, length is $length")
}String.(Int) 문법은 람다가 String의 인트턴스의 컨텍스트에서 실행된다는 의미를 가지고 있다. 만일 (Int,Double) 처럼 하나 이상의 파라미터를 받는 람다는 사용한다면 Type.(Int,Double) 이런식으로 호출하면서 리시버를 가져올 수 있다.
만얏 리시버 자체가 없거나 변수를 리시버에서 찾을 수 없으면 컴파일러는 렉시컬스코프를 찾게 된다.
printIt("Hello", 6)리시버가 첫 번째 아규먼트로 전달되었고, 실제 람다의 파라미터는 그 뒤에 따라온다.
"Hello".printIt(6)가장 좋은 호출방법은 확장함수처럼 호출하는 것이다. 코틀린은 람다를 리시버의 확장함수처럼 취급한다.
💻 출력
n is 6, length is 5
리시버를 이용한 멀티플 스코프
람다 표현식은 다른 람다표현식에 중첩 될 수있다. 바로 다이렉트 리시버와 부모의 리시버이다. 부모 람다가 다른 람다에 중첩된 람다라면 가장 안쪽의 람다 표현식은 3개 이상의 리시버를 가지는 것처럼 보인다. 사실, 람다는 하나의 리시버만 가진다. 하지만 중첩 레벨에 따라서 변수에 바인딩하기 위한 멀티플 스코프를 가질수 있다.
✍ multiple_receivers
fun top(func: String.() -> Unit) = "hello".func()
fun nested(func: Int.() -> Unit) = (-2).func()
top {
println("In outer lambda $this and $length")
nested {
println("in inner lambda $this and ${toDouble()} ")
println("from inner through receiver of outer: ${length}")
println("from inner to outer receiver ${this@top}")
}
}top() 함는 임의의 String인 "hello"를 리시버로 사용하는 람다 표현식을 실행시킨다. nested() 함수는 -2를 리시버로 사용한다. nested()함수를 보면 Int 에는 length 속성이 없기 때문에 부모의 리시버로 라우틴된다. 즉, 중첩된 람다 표현식이란 의미이다. 이너 리시버와 부모 리시버 사이에서 속성 충돌 이벤트가 생기거나 명시적으로 부모 리시버를 참조하기 위해 마지막 라인을 보면 @문법(this@top)을 사용하고 있다.
출처 : 다재다능 코틀린 프로그래밍
