1. PostgreSQL EXPLAIN
- EXPLAIN 명령은 지정한 쿼리문에 대해서 PostgreSQL planner가 만든 실행 계획을 보여줍니다.
- 실행 계획은
plain sequential scan,index scan등으로 쿼리문에서 참조되는 테이블을 스캔하는 방법과, 여러 테이블을 참조할 때 각 테이블에서 필요한 row를 합치는 데 사용할 join 알고리즘을 보여줍니다. - 실행 계획에서 가장 중요한 부분은 예상 명령문 실행 비용(cost) 입니다.
- 이 비용은 명령문을 실행하는데 걸리는 시간을 추측합니다.
- 임의의 cost 단위로 측정되지만 보통 disk page fetches 를 의미합니다.
- EXPLAIN을 사용하는 방법은 기본적으로 쿼리문 앞에
EXPLAIN명령어를 추가하고 실행하면 됩니다.(엄청 간단)!!
- ANALYSE 파라미터를 추가하면 쿼리문을 실제로 실행하고 실제 실행 시간과 통계를 표시합니다.(Default 는 false!)
explain analyse select * from pks_dckeylink where dc_key_no ='01';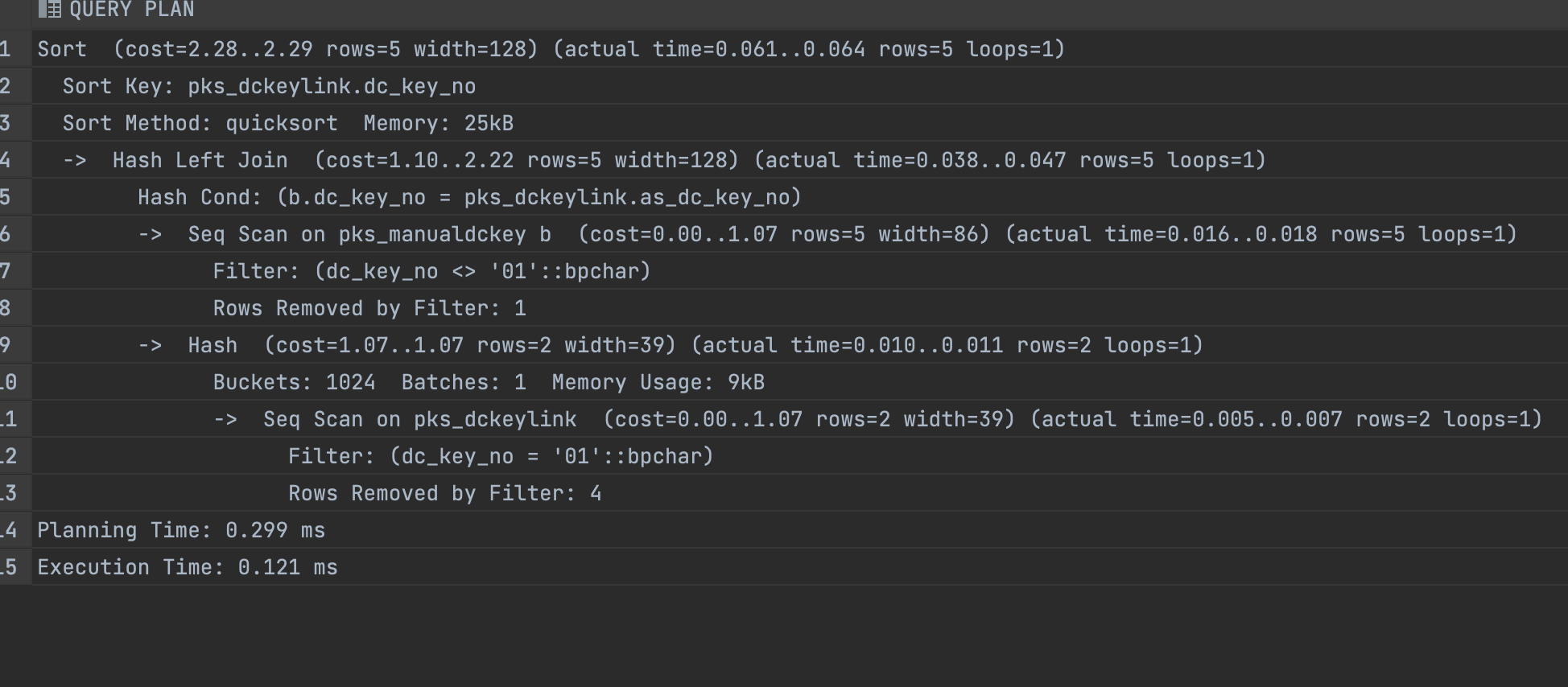
사용법을 익혔다면 이제 읽을 줄을 알아야 합니다!!!
2.EXPLAIN 분석
Sort (cost=2.28..2.29 rows=5 width=128) (actual time=0.061..0.064 rows=5 loops=1)
Sort Key: pks_dckeylink.dc_key_no
Sort Method: quicksort Memory: 25kB
-> Hash Left Join (cost=1.10..2.22 rows=5 width=128) (actual time=0.038..0.047 rows=5 loops=1)
Hash Cond: (b.dc_key_no = pks_dckeylink.as_dc_key_no)
-> Seq Scan on pks_manualdckey b (cost=0.00..1.07 rows=5 width=86) (actual time=0.016..0.018 rows=5 loops=1)
Filter: (dc_key_no <> '01'::bpchar)
Rows Removed by Filter: 1
-> Hash (cost=1.07..1.07 rows=2 width=39) (actual time=0.010..0.011 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on pks_dckeylink (cost=0.00..1.07 rows=2 width=39) (actual time=0.005..0.007 rows=2 loops=1)
Filter: (dc_key_no = '01'::bpchar)
Rows Removed by Filter: 4
Planning Time: 0.299 ms
Execution Time: 0.121 ms
- 위의 Query plan 중에서 가장 먼저 볼 것은 가장 윗줄과
->가 붙어있는 들여쓰기 된 블록입니다. - 이들은
node라고 부릅니다. node는 관련된 cost와 실행시간을 가진 논리적 작업 단위 입니다. - 각각의 noded의 cost와 시간은 누적된 값이며 모든 하위 노드를 roll up 합니다.
- 즉 , 맨 처음 node는 모든 쿼리문에 대한 누적 cost와 실제 시간을 의미합니다.
- 이를 통해 어떤 node 가 병목 지점인지 파악할 수 있습니다.
- 다음으로
cost를 살펴보면 cost는 2개의 숫자정보(cost=2.28..2.29)를 갖고 있습니다.- 첫 번째 숫자는 시작 cost(첫 번째 레코드를 검색하는 cost)이고
- 두번째 숫자는 전체 node를 처리하는데 드는 cost(시작부터 끝까지의 total cost)입니다.
- cost를 보고 PostgreSQL 의 쿼리문을 실행하기 위해 얼마나 많은 작업을 해야하는지 추정할 수 있습니다.
- cost는 정확하게 ms나 sec 와 같은 실행에 필요한 시간을 말하는 것은 아니고 그저 직접적인 상관관계가 있을 뿐입니다.
- cost는 필요한 작업을 추정하는데 사용되는 5가지 작업요소
- sequential fetch
- non-sequential(random) fetch
- processing of row
- processing operator
- processing index entry
의 조합입니다.
- cost는 I/O 와 CPU 활동을 나타내고, 상대적으로 높은 cost는 더 많은 작업을 해야한다고 여긴느 것을 말합니다.
rows는node에서 출력하는 예상 row 수를 의미합니다.loops는node가 반복된 횟수를 의미합니다.witdth는node에서 출력한 row의 예상 평균 너비(byte)입니다.- 예를 들어 row=4는 기본적으로 반환되는 각 row는 4byte라는 것입니다.
Actual time는 2개의 숫자정보를 확인 할 수 있습니다.- 첫번째 숫자는 시작시간(첫 번째 레코드를 검색하는 시간)
- 두번째 숫자는 전체 noe(natural operating environment)를 처리하는데 걸리는 시간(시작과 끝까지의 총시간)
- 둘다 밀리초(ms) 단위입니다.
planning TIme,Execution Time은 각각 출력에 대한 실행시간, 예상 실행 시간 입니다.

블로그 이전합니다! https://jyyoun1022.tistory.com/