Redis 란?
- Redis(Remote Dictionary Server)
- 디스크가 아닌 메모리 기반의 Map 처럼 'Key-Value' 구조로 이루어진 데이터 저장소
- Redis는 NoSQL로 분류 됩니다.
- memcached와 같은 인메모리(In-Memory) 솔루션으로 분류됩니다.
Redis를 사용하는 이유
- RDBMS에서 SELEECT 쿼리문을 날려 데이터들을 FETCH 하였을 때,
구조상 디스크에서 데이터를 꺼내오는 데, 메모리에서 읽어들이는 것보다 대략 1000배 가량 느리다고 합니다. - 이 때, Redis를 사용하여 DB Read 연산의 부하를 분산시킬 수 있습니다.
- 또한 다양한 데이터 타입을 지원하여 Key로 참조되는 Value 타입을 다양하게 지정할 수 있습니다.
- (List, String, Set, Sorted set 등)
Redis Type
String
- Redis의 가장 기본적인 데이터형으로 일반적인 문자열을 저장합니다.
- Text 뿐만 아니라 정수형이나 JPG 같은 바이너리 데이터도 저장이 가능합니다.
- Redis에는 정수형, 실수형이 따로 구분되어 있지 않습니다.
- Key에 넣을 수 있는 데이터의 최대 크기는 512MB 입니다.
List
- 하나의 key에 N 개의 데이터를 가지며, 중복하여 저장이 가능합니다.
- List 앞,뒤 데이터를 push or pop 할 수 있습니다.(LinkedList 처럼)
- Lpush,Rpush,Lpop,Rpop
- 또한 인덱스를 사용하여 원하는 위치 데이터를 빼거나 넣을 수 있습니다.
- 한 key에 넣을 수 있는 요소의 최대 개수는 4,294,967,295개 입니다.(2^32 -1)
- 데이터형의 값은 설정파일 조건보다 크면 LinkedList, 작다면 ZipList 로 인코딩됩니다.
Hashes
- 필드(hash-key)와 값의 쌍으로 이루어진 테이블을 저장하는 자료구조입니다.
- 보통 Object를 저장할 때 사용합니다.
- 형태는 list와 비슷합니다
- "필드명" , "필드값" 의 연속으로 이루어져 있습니다.
- 한 key에 포함 할 수 있는 field-value 쌍의 최대 개수는 List와 같다.
- 데이터형의 값은 설정파일 조건보다 크면 Hashtable, 작다면 ZipMap 으로 인코딩됩니다.
Set
- 하나의 Key에 중복되지 않은 데이터 값을 가집니다.
- Key에 속한 데이터들은 정렬되지 않고 find가 빠릅니다.
- 이 타입의 장점은 요소의 추가, 제거 및 존재 체크시 소요시간이 요소의 수에 관계없이 일정합니다.
- 데이터형의 값은 설정파일 조건보다 크면 Hashtable, 작다면 IntSet 으로 인코딩 됩니다.
Sorted Sets
- 위의 Set의 자료 구조 형태에 score 필드가 추가된 데이터 타입입니다.
- 가중치를 넣을 수 있습니다.
- Sorted Set 내에서 score를 기준으로 내부 정렬이 가능합니다.
- Key의 각 요소들의 값은 중복이 불가능하지만 score의 값은 중복될 수 있습니다.
- 범위를 대상으로 데이터를 가져올 수 있습니다.
- 요소의 추가,제거,업데이트(CUD)는 매우 빠른 방법으로 진행됩니다.
- 다른 데이터 형의 정렬을 위한 index 값으로도 활용이 가능합니다.
- 예를들어 hashes 로 한 객체 데이터를 저장하였는데, 한 필드로 정렬이 필요하다면 sorted sets의 요소의 값은 객체 구별 값, Score은 정렬을 위한 값을 넣어주면 됩니다.
- sorted sets는 가장 진보한 redis 데이터형이라고 합니다.
- 주의할 점 !
- Sorted sets의 score는 double 타입이므로 값이 정확하지 않을 수 있습니다.
Redis 사용처
Look aside Cache (Lazy Loading)
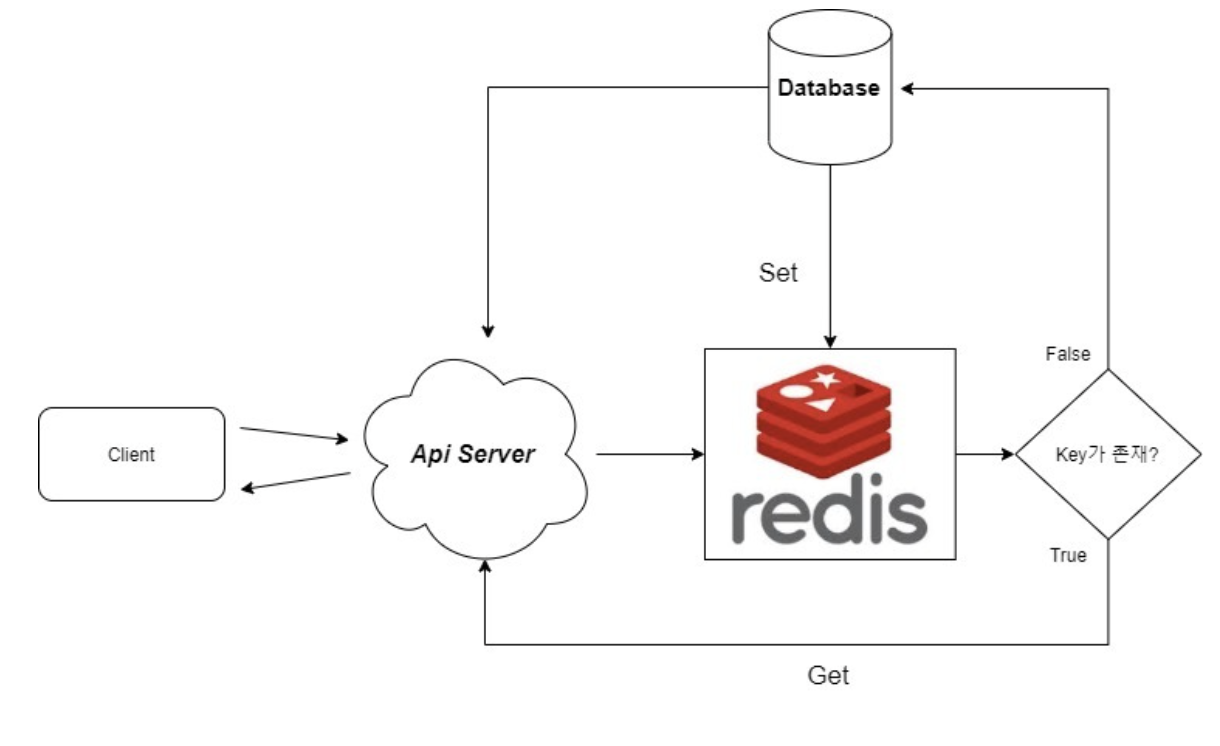
1. 클라이언트가 데이터 요청
2. Redis에 데이터가 있다면 GET
3. 없다면 DB에서 데이터와 가져옴과 동시에 Redis에 SET
- 이 구조의 장점은 같은 요청이 높은 트래픽으로 들어올 경우, RDBMS read 부하를 줄임과 동시에, 레디스의 캐싱 전략으로 빠르게 처리할 수 있습니다.

블로그 이전합니다! https://jyyoun1022.tistory.com/