JPA
1.[JPA] 페이징/정렬처리

JPA는 개발자들이 SQL이 아닌 API의 객체와 메서드를 사용하는 형태로 페이징 처리를 할 수 있도록 도와줍니다.페이징 처리와 정렬에 사용하는 메서드 : findAll()findAll()메서드는 JpaRepository 인터페이스의 상위 호환인 PagingAndSor
2.[JPA]트랜잭션(Transaction)과 ACID특성
트랜잭션이란 질의(query)를 하나의 묶음 처리해서 만약 중간에 실행이 중단되었을 경우,처음부터 다시 실행하는 Rollback을 수행하고, 오류업싱 실행을 마치면 commit을 하는 실행 단위를 의미합니다.즉 한 번 질의가 실행되면 질의가 모두 수행되거나 모두 수행되
3.[JPA]연관 관계 단방향,양방향
용어이해 방향(Direction) : 단방향, 양방향 다중성(Multiplicity) : 다대일(N:1), 일대다(1:N), 다대다(M:N) 연결관계의 주인(Owner) : 객체 양방향 연관관계는 관리주인이 필요 단반향 연관관계 객체 지향 모델링 >객체 연관관계 사
4.[JPA]getOne() 과 findById의 차이

책에 있는 예제를 보다가 오류가 발생하여 getOne()에 대해서 한번더 공부해보려고 정리해보았습니다.findById() 및 getOne()메서드는 모두 기본 데이터 저장소에서 개체를 검색하는데 사용합니다.그러나 레코드 검색을 위한 기본 케머니즘은 두 메서드가 다릅니다
5.[JPA]getOne() 과 findById의 차이
책에 있는 예제를 보다가 오류가 발생하여 getOne()에 대해서 한번더 공부해보려고 정리해보았습니다.findById() 및 getOne()메서드는 모두 기본 데이터 저장소에서 개체를 검색하는데 사용합니다.그러나 레코드 검색을 위한 기본 케머니즘은 두 메서드가 다릅니다
6.[JPA] Page 와 Slice 인터페이스
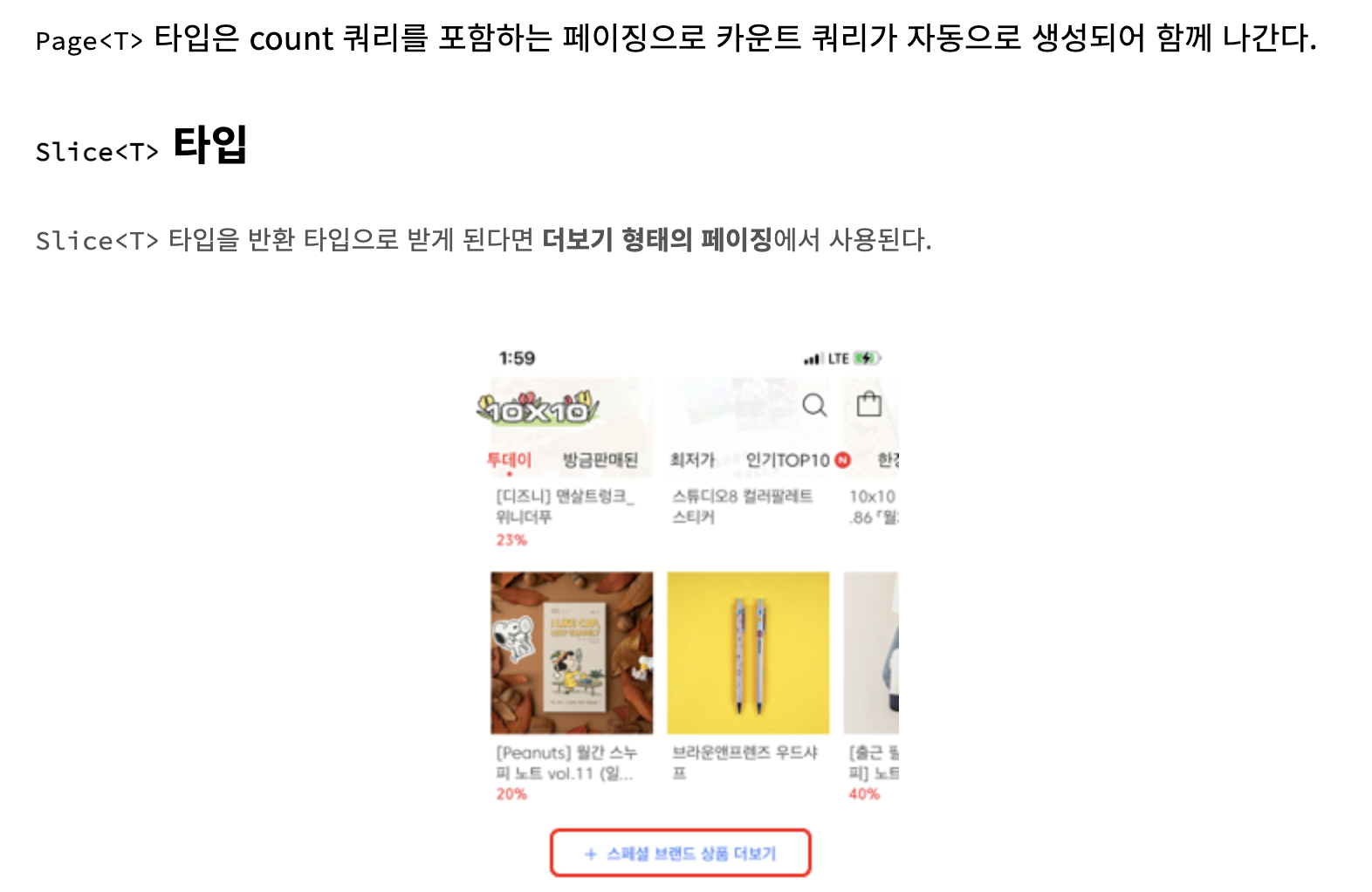
PAGE 인터페이스는 SLICE 인터페이스를 상속 받고있었다.Pageable 객체를 쿼리 메소드로 전달해 쿼리에 페이징을 동적으로 추가할 수 있다.page는 사용 가능한 데이터의 총 개 수 및 전체 페이지 수를 알 수 있다.총 개수를 알아내기 위해 추가적으로 카운트 쿼
7.[JPA] JPA Auditing
Java에서 ORM 기술인 JPA를 사용하여 도메인을 관계형 데이터베이스 테이블에 매핑할 때 공통적으로 도메인들이 가지고 있는 필드나 컬럼들이 존재합니다. 대표적으로 생성일자, 수정일자, 식별자 같은 필드 및 컬럼이 있습니다.도메인마다 공통으로 존재한다는 의미는 결국
8.[JPA]JPA 동적 검색(QueryDsl)

JPQL(Java Persistence Query Language)는 JPA(Java Persistence API)의 일부로 정의된 플랫폼에 독립적인 객체지향 쿼리 언어입니다. JPQL은 관계형 데이터베이스의 엔티티에 대한 쿼리를 만드는데 사용됩니다.JPA는 엔티티 객
9.[JPA] JPA에서 복합키와 식별관계 매핑하기
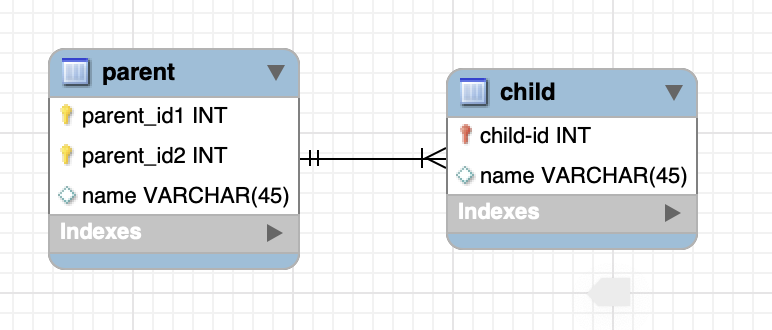
DB의 설계상에서 key를 단일 키만 사용하는 경우는 거의 없습니다.대부분 복합 key를 사용하여 DB설계를 하고 있습니다.그래서 JPA에서 복합 키를 어떻게 표현할 수 있는지 공부해 보겠습니다.DB에서는 FK(외래 키)가 기본 키에 포함되는지 여부에 따라 식별,비식별
10.[JPA]@Embedded,@Embeddable이란?
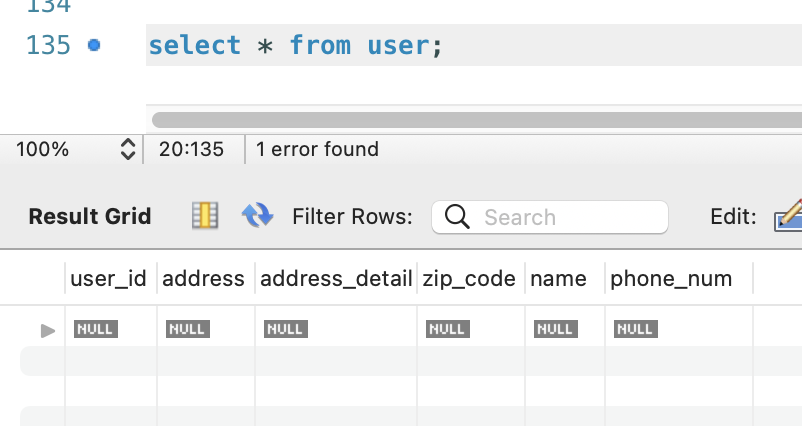
JPA에서는 Entity 내부의 값을 더 응집시켜 객체로 데이터를 표현합니다.JPA를 사용하면서 자주 보게되는 @Embedded와 @Embeddable 어노테이션을 공부해봅니다.회원가입을 생각하여 간단한 코드로 확인해 봅니다.위의 Entity를 보면 User의 정보중에
11.[JPA] 연관 관계 정리
JPA에서 가장 중요한 것을 생각해 보았는데, "객체"와 관계형 데이터베이스 테이블이 어떻게 매핑되는지를 이해하는것" 이 라고 생각합니다.왜냐하면 JPA의 목적인 "객체 지향 프로그래밍과 데이터베이스 사이의 패러다임 불일치를 해결" 이라는 것과 가장 직접적으로 연관되어
12.[JPA] 연관 관계 정리
JPA에서 가장 중요한 것을 생각해 보았는데, "객체"와 관계형 데이터베이스 테이블이 어떻게 매핑되는지를 이해하는것" 이 라고 생각합니다.왜냐하면 JPA의 목적인 "객체 지향 프로그래밍과 데이터베이스 사이의 패러다임 불일치를 해결" 이라는 것과 가장 직접적으로 연관되어
13.[JPA]쿼리 만들기
메서드 이름을 분석해서 쿼리 만들기 (CREATE)미리 정의해 둔 쿼리 찾아 사용하기(USE_DECLARED_QUERY)미리 정의한 쿼리 찾아보고 없으면 만들기(CREATE_IF_NOT_FOUND)리턴타입{접두어}{도입부}By{프로퍼티 표현식}(조건식)(And|Or){
14.[JPA] 커스텀 레포지토리 만들기
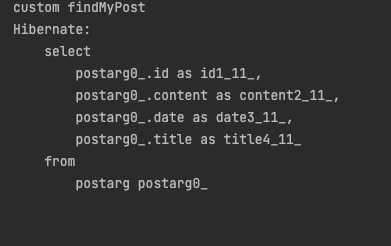
쿼리 메서드로 해결이 되지 않은 경우 직접 코딩으로 구현이 가능합니다예를 들어 Post 라는 엔티티클래스가 있다고 가정해봅니다.기본적으로 JpaRepository를 상속받은 인터페이스를 생성해줍니다.커스텀 레포지토리도 인터페이스로 생성해줍니다.이 커스텀 레포지토리에 대
15.[JPA] JPA 프로그래밍 - 기본편
기본 생성자 필수(public or protect)hibernate.hbmddl.auto, value ="create" 애플리케이션 동작시 drop과 create를 동시에 해줌name : 필드와 매핑할 테이블의 컬럼 이름 (default : 객체의 필드 이름)inser
16.[JPA] Repository 에서 Querydsl 사용하기
Querydsl 을 사용하기 위해서는 JPAQueryFactory 가 필요한데 Querydsl 을 사용하는 Repository에서 주입받으려면 불편합니다. 따라서 Config를 생성하여 JPAQueryFactory를 bean 으롤 등록하고 사용할 Repository에서
17.[JPA] BooleanBuilder를 사용한 동적 쿼리와 성능 최적화
1.@QueryProjection Q-Type을 만들기 위한 어노테이션StringUtils.hasText 를 이용하여 null 과 빈문자 체크("") (null or "" 이라면 false)StringUtils.hasText 를 이용하여 null 과 빈문자 체크(""
18.[JPA] JPA에서 Entity에 protected 생성자를 만드는 이유
엔티티에서 setter 를 사용하는 것보다 생성자를 통해 파라미터를 넘기는 것이 좋습니다.Setter를 남용하다 보면 여기저기서 객체의 값을 변경할 수 있으므로 객체의 일관성을 보장할 수가 없습니다.그리고 setter 는 의도를 알아채기 힘들기 때문에 사용을 자제해야합
19.[JPA] @Converter
컨버터를 사용하면 엔티티이 데이터를 변환하여 데이터베이스에 저장할 수있습니다. 주로 개인정보에 암호화/복호화 해야 하는 정보나, 날짜에 원하는 방식으로 저장하기 위하여 오노테이션이 붙어있습니다.Converter 를 선언할 클래스컨버터는 @Converter 어노테이션을
20.[JPA] 더티체킹(Dirty Checking)
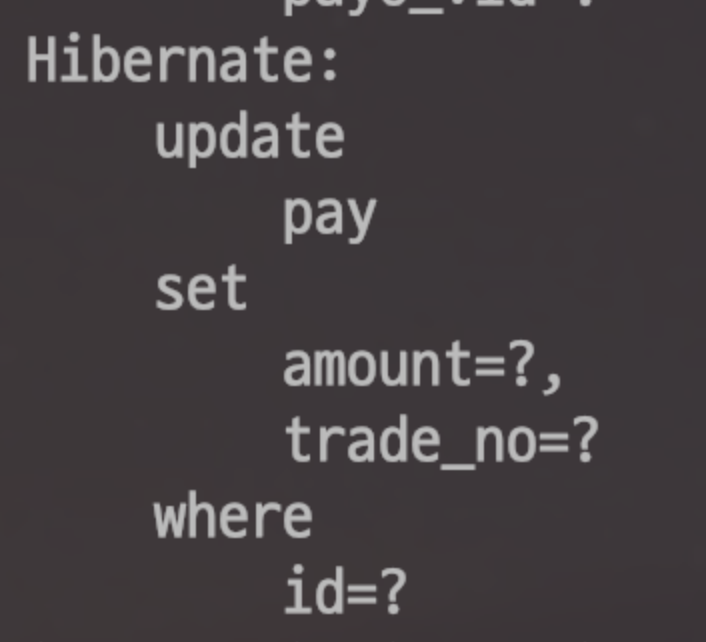
Spring Data Jpa 같은 ORM 구현체를 사용하다보면 더티체킹 이라는 단어를 종종 듣게 됩니다.PayService 클래스코드로 보면 별도로 데이터베이스에는 save 하지 않습니다.트랜잭션이 시작합니다.엔티티를 조회합니다.엔티티의 값을 변경합니다.트랜잭션을 커밋
21.JPA를 사용하면서 기본 지식들
Entity와 관련된 코드들은 많은데 비해 DTO의 경우는 상대적으로 적습니다.그런 상황에서 Entity는 변경될 가능성이 DTO에 비해 상대적으로 적습니다.만약 Entity를 Request,Response에 사용하게 되면 변경가능성이 높아지고 동시에 같이 변경되는 코