📚 데이터 병합
-
바인딩 : 데이터 행 또는 열 단순 병합
-
특정 변수를 기준으로 두 데이터를 엮는 조인 많이 사용함
✔ join
-
Inner Join: 두 변수의 공통인 행 반환 -
Left Join: 왼쪽 행 모두 유지하고 오른쪽 행은 공통되는 행만 반환->
Right Join도 있지만 보통Left Join을 더 많이 씀
✔ sample()
-
데이터 프레임에서 무작위로 몇 개의 값 출력
-
n = m: m만큼 데이터 추출
✔ random_state
-
랜덤 추출한 값에 시드 설정 가능
-
원하는 값을 설정하면 동일한 값으로 재출력 가능
->
random_state = 123으로 설정했을 때 다시123으로 입력하면 동일한 값 나옴
✔ reset_index
-
기존의 인덱스 초기화하는 메서드
-
인덱스 초기화 할 경우 0부터 row 개수만큼 숫자 재할당
-
파라미터로
drop = True속성 사용 시 기존 인덱스 삭제됨
import pandas as pd
bike = pd.read_csv("bike.csv")
bike_sub = bike.sample(n =4, random_state= 123)
bike_sub.reset_index()
# 제일 앞에 0부터 3까지 새로운 인덱스 생김
bike_sup = bike_sub.reset_index(drop = True)
// 기존에 있던 인덱스는 날려버림✔ set_index
- 특정 변수를 인덱스로 지정
bike_sub = bike_sub.set_index("datetime")
# datetime을 인덱스로 사용함
bike_sub.reset_index()
# 다시 원래 인덱스로 돌리기✔ concat
-
데이터를 row 방향 또는 column 방향으로 이어 붙이는 함수
-
axis = 0: row 방향, 기본 -
axis = 1: column 방향 -
변수명 리스트(
[])로 묶어야함
⭐ 입력
bike1 = bike.iloc[:3, :4]
# 로우 0~3 컬럼은 4개 출력
bike2 = bike.iloc[3:6 , :4]
# 행 3개 출력
pd.concat([bike1, bike2])
# 리스트처럼 묶기📌 출력
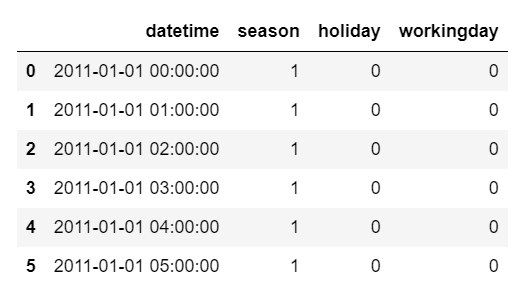
- bike2의 값이 밑으로 합쳐짐
⭐ 입력(컬럼 방향)
pd.concat([bike1, bike2], axis =1)📌 출력
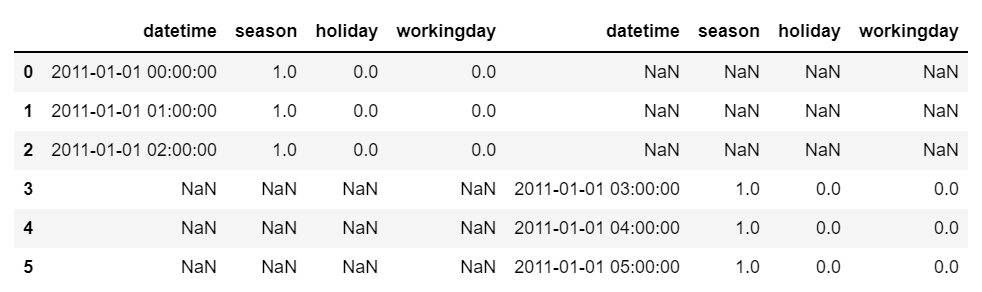
-
옆으로 붙음
-
인덱스 번호가 맞지 않기 때문에 Nan값 들어가는 거!
-
인덱스 번호가 같아야 바로 옆에 붙음
⭐ 입력(인덱스 번호 맞춰주기)
pd.concat([bike1, bike2.reset_index(drop = True)], axis =1)
# bike2의 인덱스 날려주면 잘 붙음
# 만약에 bike1의 인덱스도 0부터 시작하는 게 아니었으면
# bike1에도 drop = True으로 기존 인덱스 삭제하고
# 새로 reset_index() 해주면 밑의 사진과 같이 출력됨📌 출력

✔ merge()
-
변수 기준 병합할 때 사용
-
left_join,inner_join등 다양한 join 연산 가능-> 보통
left_join,inner_join많이 사용 -
left_on,right_on인자에 각 데이터 key 저장
⭐ 입력(inner_join)
df_a = pd.read_csv("join_data_group_members.csv")
df_b = pd.read_csv("join_data_member_room.csv")
pd.merge(left=df_a, right=df_b, left_on="member", right_on ="name", how="inner")
# left에 df_a 변수 , right에 df_b 변수
# df_a의 member컬럼이랑 df_b의 name 컬럼 연결할 거임📌 출력
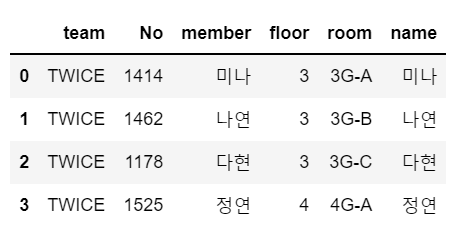
- member랑 name 이름 똑같이 맞춰짐
⭐ 입력(left_join)
pd.merge(left=df_a, right=df_b, left_on="member", right_on ="name", how="left")
# left에 df_a 변수 , right에 df_b 변수
# df_a의 member컬럼이랑 df_b의 name 컬럼 연결📌 출력
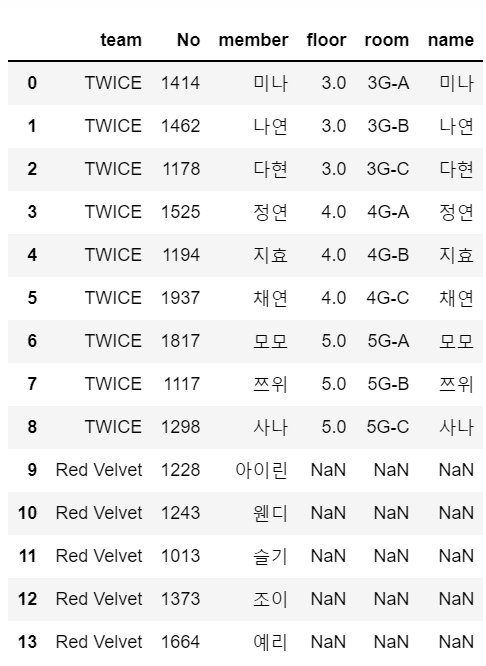
- 레드벨벳 쪽에는 매칭되는 데이터 없기 때문에
Nan으로 뜸
⭐ 입력(right_join)
pd.merge(left=df_a, right=df_b, left_on="member", right_on ="name", how="right")
# left에 df_a 변수 , right에 df_b 변수
# df_a의 member컬럼이랑 df_b의 name 컬럼 연결📌 출력
-
아까 레드벨벳은 df_b에 데이터 없었던 거 확인했음
-
오른쪽을 기준으로 데이터를 뽑았기 때문에 레드벨벳 데이터 아예 날아감
🔗 참고
inner_join은 있는 것만 출력하기 때문에 결측치 없음
- A를 B에 left_join 했을 때 생성되는 결측 행의 개수는?
df_join = pd.merge(left=df_a, right=df_b, left_on="member", right_on ="name", how="left")
df_join.isna().sum()
# 행 기준이라고 했으니까 한 번만 더하면 됨
- 여름과 겨울의 시간대별 registered 평균을 비교할 때 가장 차이가 많이 나는 시각은?
bike = pd.read_csv("bike.csv")
bike["datetime"] = pd.to_datetime(bike["datetime"])
bike["hour"] = bike["datetime"]dt.hour
# 시간으로 바꿔줌
bike_s2 = bike.loc[bike["season" == 2], ]
bike_s4 = bike.loc[bike["season" == 4], ]
# 여름과 겨울 변수 새로 만들기
bike_s2_agg = bike_s2_agg.gruopby("hour")["registered"].mean()
bike_s4_agg = bike_s4_agg.gruopby("hour")["registered"].mean()
# 시간대별 평균
bike["diff"] = bike_s2_agg - bike_s4_agg
# 두 평균 차이
bike["diff"].reset_index()
# 데이터 출력 쉽게 인덱스 새로 만들어줌
bike_s2_agg.loc[bike["diff"] == bike["diff"].max(), ]
# 최대값 구하면 답 나옴- 이건 내가 했던 방법이고 밑에는 문제에서 원한 답...
bike_s2_agg = bike_s2_agg.gruopby("hour")["registered"].mean().reset_index()
bike_s4_agg = bike_s4_agg.gruopby("hour")["registered"].mean().reset_index()
# 바로 인덱스 초기화 해주고
bike_agg_bind = pd.concat([bike_s2_agg, bike_s4_agg], axis = 1)
# 열 기준으로 붙여주는데
# hour이 중복이니까
bike_agg_bind = bike_agg_bind.iloc[:, [0,1,3]]
# 행은 모두 출력하는데
# 열은 0, 1, 3번 인덱스만 출력하겠다는 뜻
bike_agg_bind.columns = {"hour", "reg_s2", "reg_s4"}
# registered 이름 똑같으니까 이름 바꿔주는데
# rename써도 되지만 이름 다 똑같을 때는 이렇게 써도 됨
bike_agg_bind["diff"] = bike_agg_bind["reg_s2"] - bike_agg_bind["reg_s4"]
# 이제 연산함...
bike_agg_bind.iloc[[bike_agg_bind["diff"].idxmax(),] ]
# 인덱스 번호 출력
- 비가 온 날에 30도가 넘는 시각의 count의 평균은 얼마인가?
# 비가 온 날 = date 날짜 필요함
bike["datetime"] = pd.to_datetime(bike["datetime")
bike["date"] = bike["datetime"].dt.date
bike_h100 = bike.grouby("date")["humidity"].max().reset_index()
# max 값이 100임
bike_h100 = bike_h100.loc[bike_h100["humidity"] == 100, ]
# 100인 날만 고르기
bike_join = pd.merge(left=bike, right = bike_h100, left_on = "date", right_on = "date", how="inner)
# 둘이 공통인게 날짜니까 날짜를 맞춰서 출력
bike_join_up30 = bike_join.loc[bike_join["temp"]>30, ]
# 30도 넘는 날만 뽑기
bike_join_up30["count"].mean()
# count의 평균 구하기