API 연동 때문에 밤새 고생하신 적 있나요?
API 연동을 할 때, 백엔드의 데이터가 준비되지 않아 작업이 지연된 경험이 있으신가요? 아마도 많은 주니어 개발자들이 API 요청에 필요한 필드명, 데이터 포맷, 또는 엔드포인트가 나오지 않아서 작업을 멈춘 채 기다려본 경험이 있을 겁니다. 백엔드가 준비될 때까지 발만 동동 구르며 시간을 허비하는 동안, 연동 작업은 중단되고 일정은 점점 밀리기만 하죠.
이러한 상황에서 종종 필드명이 일치하지 않거나 하드코딩된 데이터로 인해 수정 작업이 반복되며 좌절감을 느낀 적도 있을 것입니다. 매번 데이터를 기다리며 답답함을 느끼는 대신, 백엔드가 완성되지 않았더라도 API 연동 작업을 빠르게 진행할 수 있는 방법이 있다면 어떨까요? 이 글에서는 여러분이 더 이상 백엔드를 재촉할 필요 없이, API 연동을 스스로 효율적으로 마무리하는 꿀팁을 소개하려 합니다. 이제 API 연동에 대한 스트레스를 덜고, 더 빠르게 작업을 완료하는 방법을 배워보세요!
"하드코딩한거 다 고쳐야 한다고요? 샘플 데이터 넣어둔거 고치는데 또 UI 컴포넌트마다 필드명은 왜이리 다른지 ㅋㅋ.."
API 연동 과정에서 백엔드가 준비되지 않은 상황에서 많은 주니어 개발자들이 흔히 빠지는 함정 중 하나는 하드코딩입니다. 특히 리액트 개발에서 이런 상황을 자주 볼 수 있죠. 예를 들어:
const SAMPLE_USER = {
name: 'John Doe',
email: 'john@example.com',
age: 30
};
function UserProfile() {
const [user, setUser] = useState(SAMPLE_USER);
// useEffect(() => {
// // TODO: API 연동 후 user 정보를 가져와 setUser로 업데이트
// }, []);
return (
<div>
<h2>{user.name}</h2>
<p>Email: {user.email}</p>
<p>Age: {user.age}</p>
</div>
);
}이런 식의 하드코딩은 임시방편으로 보일 수 있지만, 실제로는 큰 문제를 일으킬 수 있습니다.
실제 사례를 들어보겠습니다. 제가 참여했던 프로젝트에서는 백엔드 API가 미완성 상태였기 때문에, 팀에서는 우선 하드코딩된 데이터를 기반으로 개발을 시작했습니다. 그러나 이후 필드명이 여러 번 변경되면서 프론트엔드 코드가 엉망이 되었고, 여러 차례 수정을 거쳐야 했습니다.
예를 들어, 'name'이 'fullName'으로, 'email'이 'emailAddress'로 바뀌는 식이었죠. 더 큰 문제는 각 컴포넌트마다 다른 필드명을 사용하고 있어서 일괄 수정이 불가능했다는 점입니다.
// UserProfile.js
<h2>{user.name}</h2>
// UserCard.js
<p>{user.fullName}</p>
// UserSettings.js
<input value={user.userName} />이렇게 컴포넌트마다 다른 필드명을 사용하면, API 연동 시 각 컴포넌트에서 데이터를 매핑하는 로직이 제각각이 되어버립니다. 예를 들면 이런 식이죠:
// UserProfile.jsx
useEffect(() => {
api.getUser().then(data => {
setUser({
name: data.fullName,
email: data.emailAddress,
age: data.age
});
});
}, []);
// UserCard.jsx
useEffect(() => {
api.getUser().then(data => {
setUser({
fullName: data.fullName,
email: data.emailAddress
});
});
}, []);이렇게 되면 UI 로직이 복잡해지고, 데이터 구조가 변경될 때마다 여러 컴포넌트를 수정해야 하는 번거로움이 생깁니다.
결국 배포 직전에야 이런 불일치를 발견하게 되어 큰 좌절감을 느꼈습니다.
이러한 문제를 해결하기 위해서는 하드코딩된 데이터를 최소화하고, 데이터를 한 곳에서 관리하면서 필요한 곳에 제공하는 접근 방식이 필요합니다. 이를 통해 API 필드 변경에도 유연하게 대응할 수 있고, 프론트엔드 코드의 반복적인 수정을 피할 수 있습니다.
다음 섹션에서는 이 놀라운 비법에 대해 자세히 알아보겠습니다. 하드코딩의 함정에서 벗어나, 더 효율적으로 API 연동을 처리하는 방법을 함께 살펴보세요!
이거 해봤더니 API 연동이 훨씬 쉬워졌어요!
API 연동을 두 단계로 나누는 방식을 소개합니다: Repository와 Service입니다. 이는 원래 백엔드에서 주로 사용하는 기법인데, 프론트엔드에서도 활용하면 정말 효과적이에요!
-
Repository: API 서버를 마치 데이터베이스처럼 생각하고 1:1로 매칭시켜줍니다.
- API 엔드포인트와 직접 연결
- 데이터를 타입화하여 일관성 유지
- 서버의 응답을 그대로 반환
-
Service: Repository에서 가져온 데이터를 화면에서 쓰기 쉽게 가공합니다.
- 여러 Repository의 데이터를 조합
- 데이터 포맷팅 및 필드명 통일
- 한 번에 제공되지 않는 정보들을 동시에 호출하여 통합
이렇게 하면 프론트엔드 개발자에게 새로운 가능성이 열립니다. 백엔드 의존성을 줄이고, 다양한 API에서 데이터를 가져와 한 번에 가공하는 방식으로 API 연동을 더 빠르고 효율적으로 처리할 수 있죠.
예를 들어보겠습니다:
// Repository 클래스: API 엔드포인트와 직접 연결
class UserRepository {
async fetchUserInfo(userId) {
// 사용자 정보를 가져오는 API 호출
const response = await fetch(`/api/user/${userId}`);
return await response.json();
}
async fetchUserOrders(userId) {
// 사용자 주문 내역을 가져오는 API 호출
const response = await fetch(`/api/orders/${userId}`);
return await response.json();
}
}
// Service 클래스: 여러 repository에서 데이터를 가져와 가공
class UserService {
constructor(userRepository) {
this.userRepository = userRepository;
}
async getUserData(userId) {
const userInfo = await this.userRepository.fetchUserInfo(userId);
const userOrders = await this.userRepository.fetchUserOrders(userId);
// 데이터 가공: 필드명 통일, 포맷팅 등
return {
name: userInfo.fullName, // API에서는 fullName으로 오지만 프론트에서는 name으로 통일
email: userInfo.emailAddress, // emailAddress를 email로 변경
orders: userOrders.orders.map(order => ({
...order,
date: new Date(order.date).toLocaleDateString() // 날짜 포맷팅
})),
};
}
}
// 사용 예시
const userService = new UserService(new UserRepository());
userService.getUserData(123).then((userData) => {
console.log(userData);
});이처럼 서비스 계층에서 데이터를 한 번에 처리하면 프론트엔드에서 복잡한 데이터 가공 작업을 줄일 수 있습니다. 특히, 날짜 포맷팅이나 필드명 통일 같은 반복적인 작업도 이 단계에서 완료할 수 있어, 프론트엔드 컴포넌트에서는 그저 가공된 데이터를 사용하기만 하면 됩니다.
덕분에 API의 변경 사항이나 필드명 변경에도 유연하게 대응할 수 있어 유지보수도 훨씬 간편해집니다. 예를 들어, API에서 fullName이 userName으로 바뀌더라도 Service 클래스에서만 수정하면 되니까요!
이렇게 서비스 계층을 활용하면 여러 가지 이점이 있습니다:
-
컴포넌트 단순화: 컴포넌트들은 서비스 계층에서 정한 타입을 그대로 사용할 수 있어, 데이터 처리 로직이 크게 줄어듭니다.
-
일관성 유지: 필드명에 대한 일관성이 서비스 계층에서 처리되므로, 컴포넌트 간 데이터 구조 불일치 문제가 해결됩니다.
-
관심사의 분리: 상태와 UI에 맞는 데이터 정제가 서로 분리되어 관리됩니다. 훅(Hook)은 상태만 동기화하는 역할을 하고, 데이터 포매팅은 서비스의 역할이 됩니다.
예를 들어, 컴포넌트는 이렇게 간단해질 수 있습니다:
function UserProfile() {
const { userData, loading, error } = useUserData(123); // 커스텀 훅
if (loading) return <div>Loading...</div>;
if (error) return <div>Error: {error.message}</div>;
return (
<div>
<h2>{userData.name}</h2>
<p>Email: {userData.email}</p>
<h3>Orders:</h3>
<ul>
{userData.orders.map(order => (
<li key={order.id}>{order.product} - {order.date}</li>
))}
</ul>
</div>
);
}이런 접근 방식은 어찌 보면 작은 BFF(Backend for Frontend)를 구현한 것과 같다고 볼 수 있습니다. BFF는 원래 백엔드가 프론트엔드에 친화적으로 데이터를 제공해주는 기법인데, 여기서는 프론트엔드가 직접 그 역할을 수행하고 있는 거죠. ㅠ_ㅠ
결국, 백엔드에서 완벽한 API를 제공받지 못하더라도, 프론트엔드에서 이런 방식으로 데이터를 효율적으로 관리하고 사용할 수 있습니다. 이를 통해 백엔드와 프론트엔드 사이의 간극을 줄이고, 더 유연하고 maintainable한 코드를 작성할 수 있게 됩니다.
심화편: Storybook으로 백엔드 없이 완성된 페이지 만들기
Storybook은 단순한 컴포넌트 테스트 도구를 넘어서, 프론트엔드 개발자가 백엔드 없이도 완성된 페이지를 테스트할 수 있는 강력한 도구입니다. 특히 여러 repository 계층을 Mocking하여 API가 준비되지 않았더라도, UI 컴포넌트에서 service 계층을 호출해 실제 작업처럼 진행할 수 있습니다.
Storybook에서 여러 Repository를 Mocking하는 방법
실제 애플리케이션에서는 여러 종류의 데이터를 다루는 경우가 많습니다. 예를 들어, 사용자 정보, 주문 내역, 제품 목록 등을 각각 다른 repository에서 관리할 수 있습니다. 이런 경우 Storybook에서 각 repository를 모두 mocking해야 합니다.
다음은 여러 repository를 mocking하는 예시입니다:
// MockUserRepository.ts
export class MockUserRepository {
async fetchUserInfo(userId: string) {
return {
id: userId,
name: "John Doe",
email: "john@example.com"
};
}
}
// MockOrderRepository.ts
export class MockOrderRepository {
async fetchUserOrders(userId: string) {
return [
{ id: "1", product: "Laptop", date: "2024-08-01" },
{ id: "2", product: "Mouse", date: "2024-08-15" }
];
}
}
// MockProductRepository.ts
export class MockProductRepository {
async fetchFeaturedProducts() {
return [
{ id: "1", name: "Super Laptop", price: 999 },
{ id: "2", name: "Ergonomic Mouse", price: 59 }
];
}
}
// UserService.ts
export class UserService {
constructor(
private userRepo: MockUserRepository,
private orderRepo: MockOrderRepository,
private productRepo: MockProductRepository
) {}
async getUserDashboardData(userId: string) {
const [userInfo, userOrders, featuredProducts] = await Promise.all([
this.userRepo.fetchUserInfo(userId),
this.orderRepo.fetchUserOrders(userId),
this.productRepo.fetchFeaturedProducts()
]);
return {
user: userInfo,
recentOrders: userOrders.slice(0, 5),
recommendedProducts: featuredProducts.slice(0, 3)
};
}
}
// Storybook story
export const UserDashboardStory = () => {
const userRepo = new MockUserRepository();
const orderRepo = new MockOrderRepository();
const productRepo = new MockProductRepository();
const userService = new UserService(userRepo, orderRepo, productRepo);
return <UserDashboard userService={userService} userId="123" />;
};이 예시에서는 UserRepository, OrderRepository, ProductRepository 세 가지 repository를 모킹하고 있습니다. UserService는 이 세 repository를 사용하여 사용자 대시보드에 필요한 데이터를 가져옵니다.
Subpath Imports를 활용한 효율적인 모킹
여러 repository를 모킹할 때 subpath imports를 활용하면 더욱 효율적으로 관리할 수 있습니다. package.json에 다음과 같이 설정할 수 있습니다:
{
"imports": {
"#repositories/user": {
"storybook": "./repositories/user.mock.ts",
"default": "./repositories/user.ts"
},
"#repositories/order": {
"storybook": "./repositories/order.mock.ts",
"default": "./repositories/order.ts"
},
"#repositories/product": {
"storybook": "./repositories/product.mock.ts",
"default": "./repositories/product.ts"
}
}
}이렇게 설정하면 컴포넌트나 서비스에서 다음과 같이 import할 수 있습니다:
import { UserRepository } from '#repositories/user';
import { OrderRepository } from '#repositories/order';
import { ProductRepository } from '#repositories/product';Storybook 환경에서는 자동으로 mock 파일을, 실제 환경에서는 원본 파일을 사용하게 됩니다.
여러 repository를 모킹하고 Storybook과 subpath imports를 활용하면, 복잡한 데이터 흐름을 가진 애플리케이션도 백엔드 API 개발과 무관하게 효율적으로 개발할 수 있습니다. 이를 통해 개발 속도를 높이고, 다양한 시나리오를 미리 테스트하며, 결과적으로 더 안정적인 애플리케이션을 만들 수 있습니다.
스토리북으로 검색페이지를 만들었다구요!(api 연동도 되어있음!)
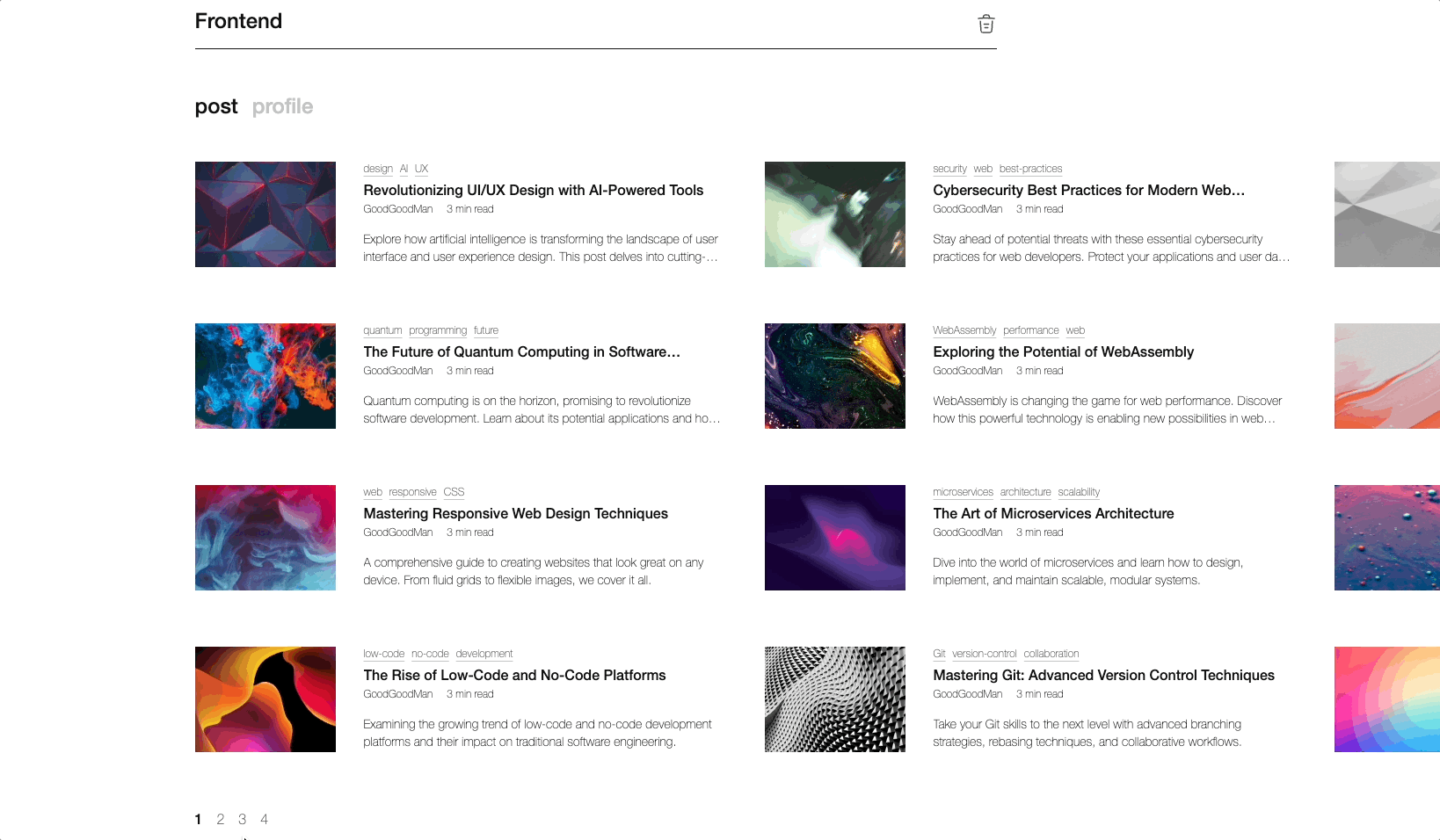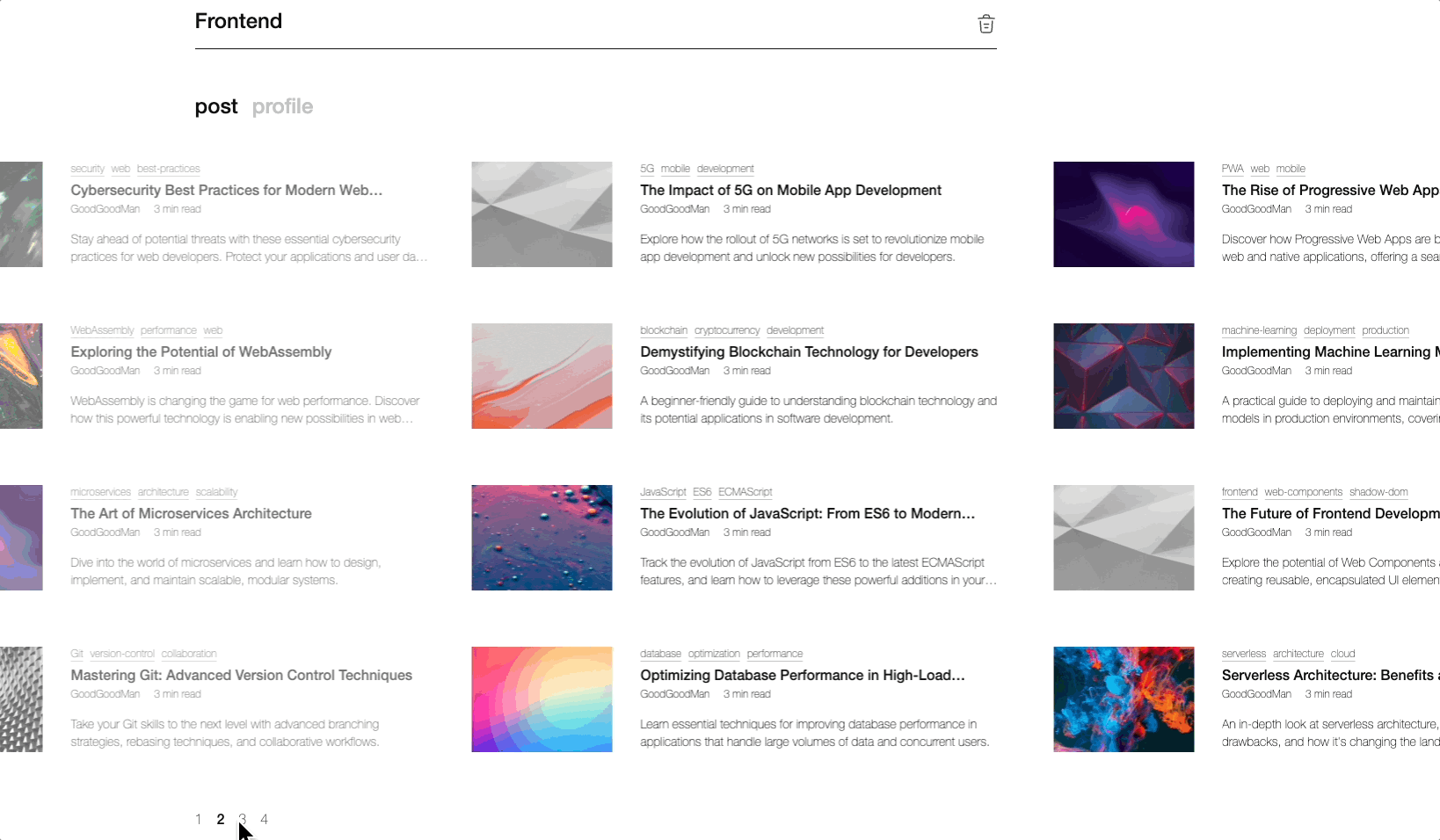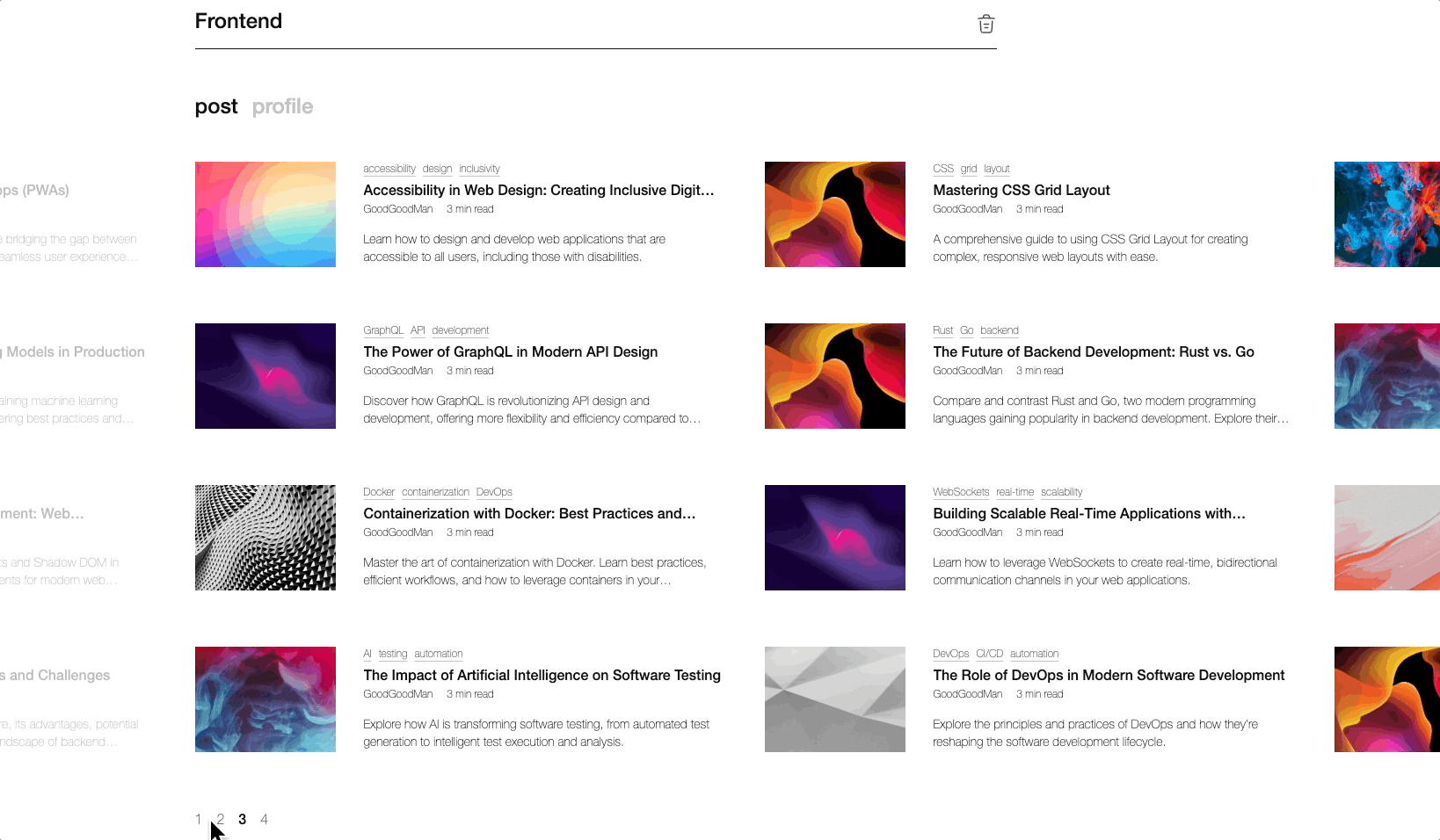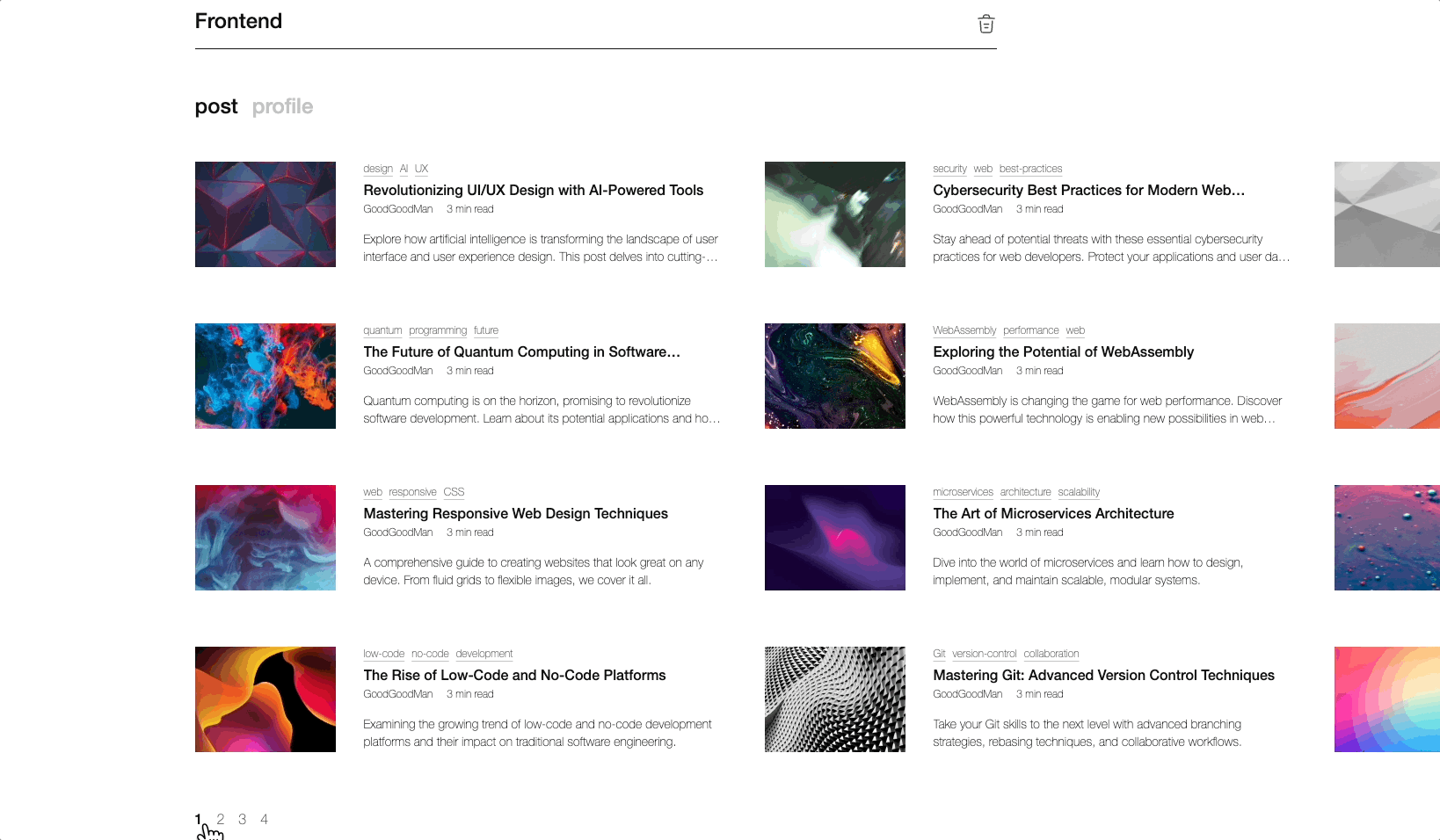
이제 당신은 API 연동의 슈퍼히어로! 🦸♂️
여러분, 축하합니다! 이제 여러분은 API 연동의 달인이 되었어요. 더 이상 백엔드 팀을 기다리며 머리를 쥐어뜯을 필요가 없답니다.
자, 이제 어떤 일이 벌어질까요?
-
빛의 속도로 개발하기: 서비스 계층과 모킹으로 무장한 여러분은 이제 광속으로 개발할 수 있어요. 백엔드가 준비되기도 전에 프론트엔드를 완성할 수 있다니, 상상이 가나요? 🚀
-
야근? 그게 뭐죠?: API를 기다리느라 밤늦게까지 사무실에 남아있던 날들은 이제 추억이 되었어요. 이제 퇴근 시간에는 정확히 칼퇴근! ⏰
-
여유 시간 대폭발: 갑자기 생긴 여유 시간, 어떻게 쓰실 건가요? 새로운 프레임워크를 배워볼까요? 아니면 오랫동안 미뤄둔 사이드 프로젝트를 시작해볼까요? 아니면 그냥 넷플릭스나 볼까요? (농담이에요, 물론 공부하세요! 😉)
-
팀의 히어로 되기: "어떻게 이렇게 빨리 개발하셨어요?"라는 질문을 받을 준비하세요. 여러분은 이제 팀의 슈퍼스타예요.
-
끝없는 성장: 이렇게 번 시간으로 더 많은 것을 배우고 성장할 수 있어요. 신기술, 새로운 패턴, 다음에 배울 건 뭘까요? 가능성은 무한하답니다!
자, 이제 여러분은 API 연동의 마법사가 되었어요. 이 힘을 사용해 코드 세상을 더 나은 곳으로 만들어주세요. 그리고 가끔은 쉬어가는 것도 잊지 마세요. 완벽한 워라벨!, 그게 바로 진정한 10x 개발자의 비결이니까요!
이제 가서 여러분의 마법으로 세상을 놀라게 해주세요! 그리고 점심 시간에 맛있는 거 드세요, 여러분 정말 멋져요! 👏👏👏



와 제목만 보고 내용 예측에 성공했어요!
어쩌면 나 성장했을지도?