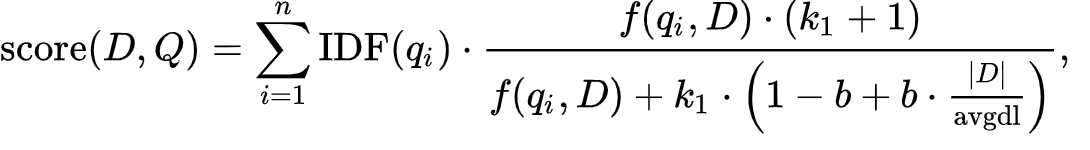
Elasticsearch는 6.3버전 이후로 BM25 알고리즘으로 score를 계산하고 있다.
score 계산법은 쿼리 요청 시, explain=true를 파라미터로 넘기면 확인할 수 있다.
"details" : [
{
"value" : 0.0111732995,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.0111733,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [...]
},
{
"value" : 0.45454544,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [...]
}
]
}
]description을 확인해보면 아래의 수식을 찾을 수 있다.
boost * idf * tf즉, score 계산은 boost(가중치 값)과 idf, tf를 곱한 값으로 이루어진다는 것을 알 수 있다.
그렇다면 idf와 tf는 뭘까? description을 다시 살펴보자.
Inverse Document Frequency(idf)
idf = log(1 + (N - n + 0.5) / (n + 0.5))
N : 총 문서의 개수
n : 문서에 단어가 등장하는 빈도수수식을 보면 N값 대비 n값이 낮을수록 idf가 커진다.
즉, 문서에 해당 키워드가 등장하는 빈도가 작을수록, score가 높게. 키워드가 등장하는 빈도가 높을수록, score가 낮게 부여되는 방법이다.
Term Frequency(tf)
tfNorm = freq / (freq + k1 * (1 - b + b * dl / avgdl))
freq : 문서에 나타나는 키워드 수
k1 : 상수(elastic default 1.2)
b : 상수(elastic default 0.75)
dl : 검색된 필드의 길이
avgdl : 평균 필드 길이수식을 보면 freq(문서에 나타나는 키워드 수)이 높을수록, avgdl(평균 필드의 길이)대비 dl(검색된 문서의 필드 길이)가 짧을수록 tf의 크기가 커진다.
즉, 검색된 문서에 해당 키워드수가 자주 등장할 수록,평균 필드 길이보다 검색된 문서의 필드가 짧을수록 score가 높게 부여되는 방법이다.
결론
- 전체 문서에서 검색 키워드가 등장하는 빈도수가 작을수록(즉, 유니크한 단어일수록)
- 검색된 문서에서 검색 키워드가 많이 나타날수록
- 평균 필드 길이보다 검색된 문서의 필드가 짧을수록 score가 올라간다!

📌 기억하기 위해 남기는 기록들