
개요
학회 활동도 하는 겸 해서 고전 명작 논문을 한번 리뷰하게 되었다.
사실 Attention 구조도 많이 쓰고 Transformer 구조도 많이(사실 많이 안써봄) 써봤지만, Transformer의 FF 구조가 정확히 어떤 식으로 representation을 잡아내는지는 정확하게 이해하지 못했기 때문에 Attention과 Feed Forward가 어떤 식으로 상호작용 하는 지, Residual connection과 normalization이 어떤 구조로 이에 도움을 주는 지 알고 싶었고, 이 후 Transformer를 직접 구현하는 과정이 있기 때문에, 간단하게 구현하고 학습도 해본 후에 Visualization까지 하는 것이 2주차까지의 목표이다.
배경
알다시피 Transformer는 RNN, LSTM, GRU 등으로 이어진 sequence modeling에서 parallelization이 잘 안되는 문제와, memory 문제, long range dependency 문제 때문에 이를 보완하기 위해 attention 구조를 이용해서 사용하다가 아예 attention 만으로 모델을 구성하는 것이 가능하다며 나온 논문이다. 오래 전에 나온 논문이지만 아직도 많이 쓰이는 것을 넘어서 점점 더 많이 쓰여 Convolution도 대체하는 논문이 여럿 나오고 있는 시점이다. 특히 대규모 언어 모델의 경우 Fine tuning과 매우 큰 데이터셋의 차이만 있을 뿐 여전히 auto regressive 기반의 구조를 그대로 이용하고 있다.
구조
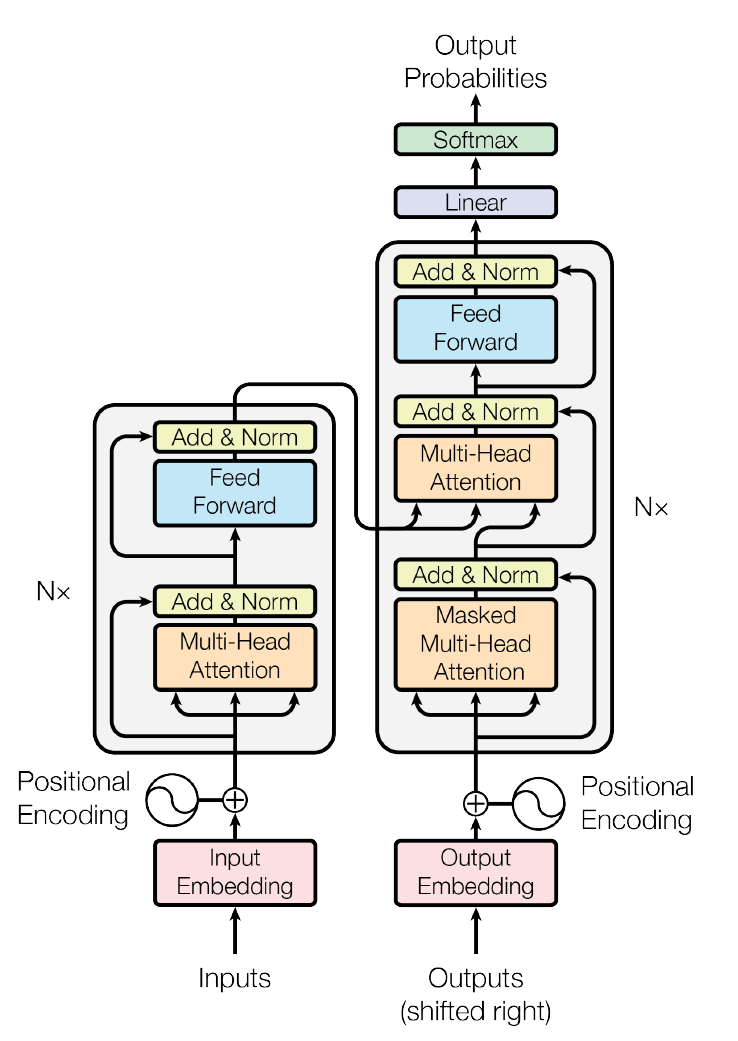
Encoder
논문에선 encoder에 N=6 layers를 이용하고 있다.
layer 마다 2개의 sub-layer로 구성되어 있으며, 각 sub-layer는 각각 multi-head attention과 add & layer norm. 즉 구조로 되어 있으며 논문에선 embedding dimension 로 설정하였다.
Decoder
마찬가지로 N=6개의 layers를 이용하고 있으며, 3개의 sub-layers로 구성되어 있는데, encoder와 비슷한 두개의 sub-layer 구조에 중간에 cross attention layer에 들어가 있다. encoder와 다른 점은 앞에서 말했 듯이 cross attention이 들어간 점과 앞의 self attention이 Masked Multi-Head Attention이 들어가 있다는 점이다.
Attention
Attention은 Transformer 구조만이 아니라 요즘에는 어떤 모델이든 다 쓴다고 봐도 좋을 정도로 많이 쓰는 구조이기 때문에 정확한 이해가 필요하다.
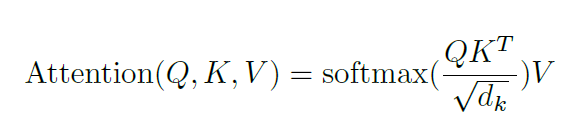
기본적으로 위와 같은 식으로 계산이 되며,
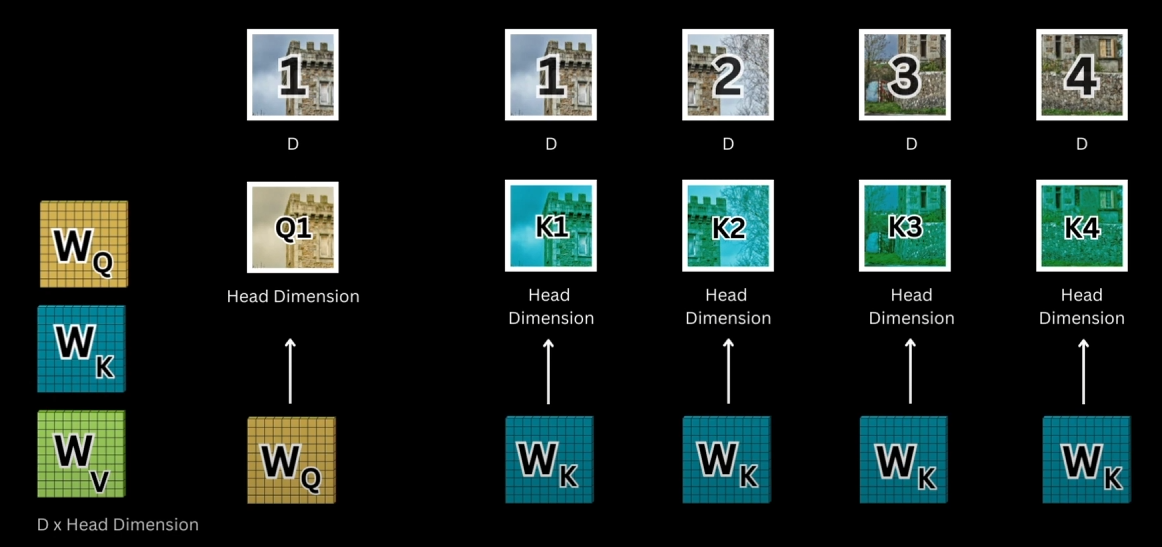
이건 Vision Transformer에서의 Vision attention이긴 한데 원리는 같다. Q, K, V에 각각 를 곱해 linear projection 한 후에 여기서 도출 된 represention을 이용해 계산한다. 일단 Q는 [num_token_query, head_dimension] 차원의 행렬이고, K도 [num_token_key, head_dimension]의 행렬이므로 계산을 하면 [num_token_query, num_token_key]의 행렬이 나오게 된다.

결과 값은 matrix multiplication에 의해 너무 커져서 softmax를 거쳤을 때 gradient가 너무 작아질 수 있으므로 이를 으로 나눠주게 된다.
이 값을 row마다 softmax하게 되면, 예를 들어 첫 번째 줄의 값은 Q1(query의 첫 번째 토큰)의 embedding이 key의 각각의 token과 얼마나 관련되어 있는지를 알려주게 된다.

V는 [num_token_value, embedding_dimension]의 행렬이므로,
이 값을 이용해 V와 곱해주게 된다면 예를 들어 a1=0.8, a2=0.2라고 했을 때 결과의 첫 번째 줄은 value의 첫 번째 token의 embedding을 0.8 함유하게 되고 두 번째 token의 embedding을 0.2 함유하게 된다.
보통 cross attention은 key와 value를 같은 값으로 두고 query를 다른 값으로 두는데, 이렇게 되면 query와 key와의 관계를 고려한 value의 값이 결과로 나오게 되는데, 이 때 차원은 [num_token_query, embedding_dimension]이 된다. 이 때 key와 value의 num_token은 같아야한다.
Multi-head Attention
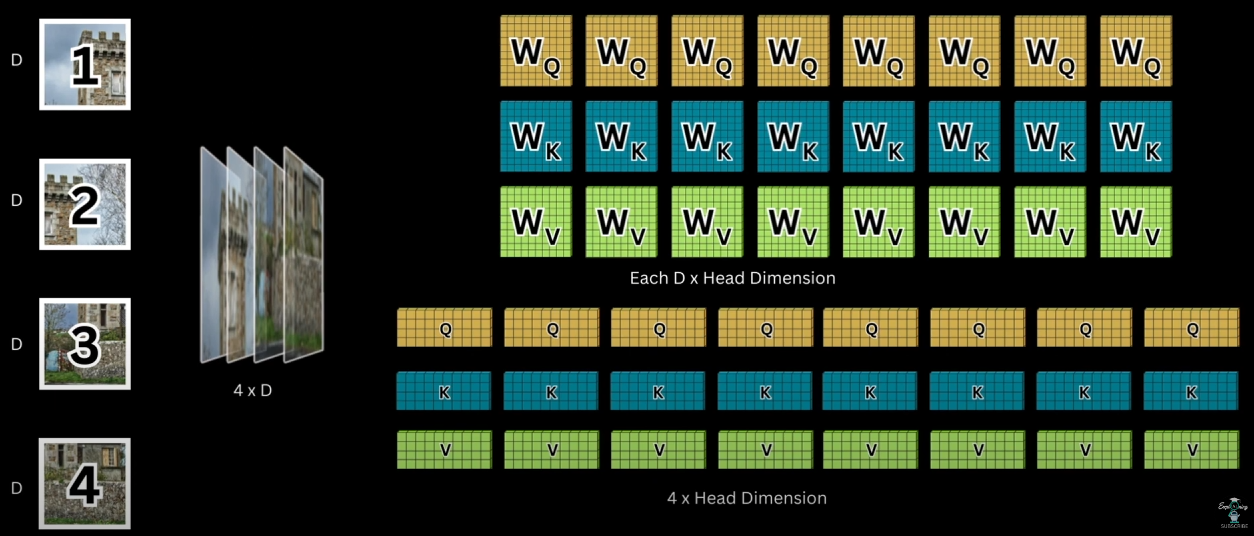
Token마다 여러가지 상호 관계가 존재할 수 있는데, 이를 하나의 attention으로 나타내기엔 embed_dim도 너무 커지고 제대로 표현되지 않을 수 있다. 따라서 attention은 이를 여러가지 head로 나눈다. 이 때 W의 dimension 또한 head의 개수만큼 나누게 된다. 위의 사진은 head가 8개 일때의 예시이다. 사실 요즘은 다 multi head를 이용하기 때문에 그냥 head dimension으로 이해하는게 쉽다.
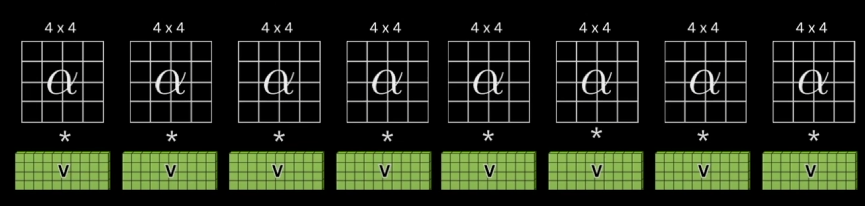
이 후 위와 같이 각각 head에 대해 QKV 계산을 하게 되는데,

어차피 W를 하나로 합쳐서 계산한 후에 나눠도 같은 결과가 나오기 때문에 이렇게 하는 것이 빠르다. W는 [token dimension, 8 * 3 * head_dimension] 의 행렬이 되고, 이를 token들의 행렬에 곱하면 [num_token, 8 * 3 * head_dimension]의 행렬이 되므로 이를 3등분 하면 [num_token, 8 * head_dimension]의 행렬이 3개 나오게 된다.
이 부분은 결국 차원 맞추기라서 그냥 손으로 그려보면서 하면 쉽게 이해가 갈 것이다.

결과 값은 concat하게 되고, 따라서 결과 값은 [num_token_query, num_heads * head_dimension]이 되므로 이를 으로 [num_token_query, embed_dim]으로 바꿔주게 된다.
Masked Multi-head Attention
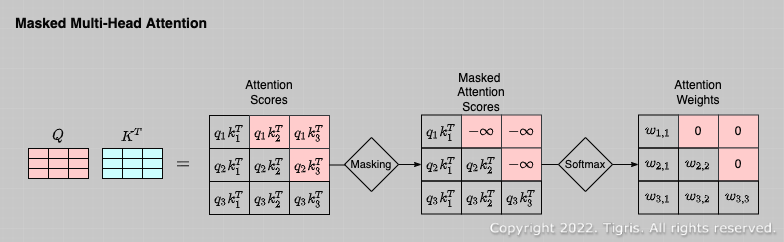
Transformer의 Decoder는 보통 auto-regressive로 앞의 문장을 보고 뒤의 단어를 유추해야 하는데, training을 할 때 모든 문장을 주어주면 뒷 단어까지 참고하게 되므로 의 결과에 위와 같이 -infinity로 mask를 넣어주어 softmax를 거쳤을 때 사실상 0으로 수렴하도록 만들어 Value의 값들이 뒤의 값들을 참고하지 못하도록 하는 방법이다.
FFN

Transformer의 Feed Forward Network는 위와 같이 계산된다. 특별한 건 없는데, 그냥 다른 linear transformation과 같이 attention으로 나온 embedding 값을 목적에 따라 더 feature를 잘 나타내도록 하는 작업인듯. kernel size 1의 conv layer로 대체할 수 있다는데 그렇게 할 필요는 없을 것 같다. 그렇게 하는 걸 본적도없고.
positional embedding
https://nsbg.tistory.com/entry/Transformer-%EC%8B%9C%EB%A6%AC%EC%A6%88-01-Positional-Encoding
위 블로그가 너무 자세하게 잘 설명해놓았기 때문에 생략.
최근엔 rotary positional embedding이란 것도 이용하던데 나중에 공부해보면 좋을 것 같다.
사진 출처: Transformer 논문,
https://tigris-data-science.tistory.com/entry/%EC%B0%A8%EA%B7%BC%EC%B0%A8%EA%B7%BC-%EC%9D%B4%ED%95%B4%ED%95%98%EB%8A%94-Transformer4-Masked-Multi-Head-Attention%EA%B3%BC-Decoder,
https://youtu.be/zT_el_cjiJw?si=ubHwwFtIY2Kwao4h
