ORM(Object-Relational Mapping)
자바의 객체와 DB의 테이블을 매핑(연결)해서 영속화
ORM은 객체 지향 프로그래밍 언어인 자바와 관계형 데이터베이스 간의 불일치를 해결하고, 객체와 데이터베이스 간의 변환을 자동화하여 개발자의 작업을 간소화
객체-관계 불일치 해결: 객체 지향 프로그래밍 언어와 관계형 데이터베이스 간에는 다양한 불일치가 존재합니다. 예를 들어, 객체는 상속, 다형성, 연관 관계 등을 지원하지만, 데이터베이스는 테이블 구조로 데이터를 저장합니다. ORM은 이러한 불일치를 해결하여 객체와 테이블 간의 변환을 쉽게 처리합니다.
CRUD 작업 간소화: ORM을 사용하면 객체를 생성(Create), 조회(Read), 수정(Update), 삭제(Delete)하는 작업을 객체 지향적으로 처리할 수 있습니다. 개발자는 SQL 쿼리를 직접 작성하지 않고도 객체에 대한 CRUD 작업을 수행할 수 있습니다.
성능 최적화: ORM은 데이터베이스와의 상호작용을 최적화하여 성능을 향상시킬 수 있습니다. 캐싱, 지연 로딩, 배치 처리 등을 통해 효율적인 데이터 접근 방식을 지원합니다.
데이터베이스 독립성: ORM은 데이터베이스 종속성을 줄여주어 여러 종류의 데이터베이스 시스템에 대한 호환성을 제공합니다. 개발자는 데이터베이스 변경 시에도 큰 수정 없이 코드를 유지할 수 있습니다.
JPA(Java Persistence API)
JPA는 자바 표준으로서 ORM의 구현을 표준화한 것입니다.
자바에서 ORM을 적용한게 JPA
자바랑 DB랑 사이에서 매핑
자바 객체를 DB로 보낼때 쿼리로 만들어주고
DB 조회한걸 자바로 보낼때 객체로 만들어주고
JPA(Java Persistence API)는 자바 언어와 데이터베이스 사이에서 객체와 관계형 데이터베이스의 매핑(Mapping)을 수행하는 자바 표준 인터페이스입니다. JPA는 객체 지향 프로그래밍과 관계형 데이터베이스 간의 불일치를 해결하고, 자바 객체와 데이터베이스 테이블 간의 변환 및 연결을 단순화하는 역할을 합니다.
JPA는 객체를 데이터베이스에 저장하거나 데이터베이스에서 가져오는 작업을 처리합니다. 주요 기능으로는 객체와 테이블 간의 매핑, 데이터베이스 CRUD(Create, Read, Update, Delete) 작업, 객체 간의 관계 처리 등이 포함됩니다.
JPA의 동작 방식은 다음과 같습니다:
객체와 테이블 매핑: JPA는 자바 클래스와 데이터베이스 테이블 간의 매핑을 설정합니다. 애노테이션을 사용하여 매핑 정보를 지정하거나 XML 매핑 파일을 사용할 수 있습니다.
CRUD 작업: JPA는 자바 객체의 생성(Create), 조회(Read), 수정(Update), 삭제(Delete) 작업을 데이터베이스에 대응하도록 처리합니다. 객체를 생성하면 해당 데이터가 데이터베이스에 삽입되고, 객체를 조회하면 데이터베이스에서 해당 데이터를 가져옵니다.
객체 간의 관계: JPA는 객체 간의 연관 관계와 관련된 데이터베이스의 외래 키(Foreign Key) 관계를 처리합니다. 객체 간의 관계를 설정하고, 이를 데이터베이스 스키마에 맞게 매핑합니다.
JPQL(Java Persistence Query Language): JPA는 객체 지향적인 쿼리 언어인 JPQL을 제공합니다. JPQL을 사용하여 객체를 대상으로 쿼리를 작성하고 실행할 수 있습니다.
JPA를 사용하면 자바 객체를 데이터베이스로 보낼 때 INSERT, UPDATE, DELETE 쿼리를 자동으로 생성하고 실행하여 데이터베이스와 자바 객체 간의 변환 작업을 간소화할 수 있습니다. 또한 데이터베이스에서 조회한 결과를 자바 객체로 변환할 때 SELECT 쿼리를 자동으로 생성하여 처리합니다.
영속성 컨텍스트(Persistence Context)
JPA에서 엔터티(Entity)의 상태를 관리하는 공간
엔터티(Entity)의 상태를 관리하고 엔터티의 생명주기를 추적하는 역할을 합니다.
영속성 컨텍스트는 엔터티와 데이터베이스 간의 중간 계층으로 작동하며,
엔터티의 변경을 추적하여 데이터베이스에 동기화하고 캐싱하며 성능을 최적화하는 역할을 합니다.
엔터티의 상태 관리: 영속성 컨텍스트는 엔터티의 상태 변화를 추적하고, 엔터티의 변경이 어떤 상태에 있는지를 관리합니다. 엔터티를 생성하거나 조회한 후에는 이 엔터티가 영속성 컨텍스트에 관리되며, 엔터티의 변경을 영속성 컨텍스트가 추적합니다.
캐싱: 영속성 컨텍스트는 데이터베이스에서 조회한 엔터티를 캐시에 저장합니다. 이를 통해 같은 엔터티를 반복적으로 조회할 때 데이터베이스에 매번 접근하지 않고 캐시에서 읽어와 성능을 향상시킬 수 있습니다.
변경 감지: 영속성 컨텍스트는 엔터티의 상태 변화를 감지하여 자동으로 UPDATE 쿼리를 생성하고 데이터베이스와 동기화합니다. 엔터티의 변경 사항이 발생하면 JPA가 알아서 데이터베이스에 변경을 반영합니다.
트랜잭션 지원: 영속성 컨텍스트는 트랜잭션 범위에 따라 엔터티의 변경을 추적합니다. 트랜잭션 커밋 시에 변경된 내용을 데이터베이스에 반영하게 됩니다.
지연 로딩 및 즉시 로딩: 영속성 컨텍스트는 엔터티 간의 연관 관계에서 지연 로딩(Lazy Loading)과 즉시 로딩(Eager Loading)을 지원합니다. 필요한 데이터만 로딩하여 데이터베이스 접근을 최적화할 수 있습니다.
동일성 보장: 같은 엔터티를 조회하면 영속성 컨텍스트에서는 항상 같은 인스턴스를 반환하여 객체 동일성을 보장합니다.
Hibernate
Hibernate는 JPA(Java Persistence API)의 구현체
Hibernate는 JPA의 스펙을 따르면서 확장된 기능을 제공하는 ORM 프레임워크입니다.
Hibernate는 JPA의 구현체: Hibernate는 JPA 스펙을 구현한 ORM 프레임워크입니다. JPA는 자바 표준 API이며, Hibernate는 JPA 스펙을 준수하여 구현한 것입니다. 즉, Hibernate를 사용하면 JPA의 표준 기능을 활용하면서 Hibernate 고유의 기능과 설정을 추가로 사용할 수 있습니다.
JPA와 공통된 개념 및 기능: Hibernate와 JPA는 엔터티 매핑, 영속성 컨텍스트, JPQL(Java Persistence Query Language) 등의 기능을 공통적으로 제공합니다. Hibernate를 사용하면 JPA의 엔터티 매핑 애노테이션과 관련된 설정을 사용하며, 영속성 컨텍스트를 활용하여 엔터티의 상태를 추적하고 변경 사항을 관리할 수 있습니다.
확장된 기능: Hibernate는 JPA 스펙을 확장하여 다양한 고급 기능을 제공합니다. 예를 들어, Hibernate의 특화된 애노테이션과 설정을 통해 성능 최적화, 배치 처리, 캐싱, 상속 매핑 등을 보다 편리하게 다룰 수 있습니다.
세이브 전에는 비영속
세이브 할때
pk가 없으면 인서트
있으면 수정
세이브하면 영속 객체
createNativeQuery
데이터베이스로 쓰는 특정 SQL의 문법을 사용하여 쿼리를 작성
createQuery
JPQL 쿼리를 생성합니다.
JPQL은 객체 지향적인 쿼리 언어로서,
DB의 테이블이 아니라, 엔티티와 필드를 대상으로 하는 쿼리를 작성할 수 있습니다.
그러면 자동으로 사용하는 DB SQL의 문법대로 DB에 반영됨
컨트롤러(요청처리, 핵심로직호출, 응답처리)
서비스(비지니스로직, 트랜잭션관리, db랑 연관된거, 예외 처리)
레포지토리(DB상호작용)
영속성컨텍스트
DB
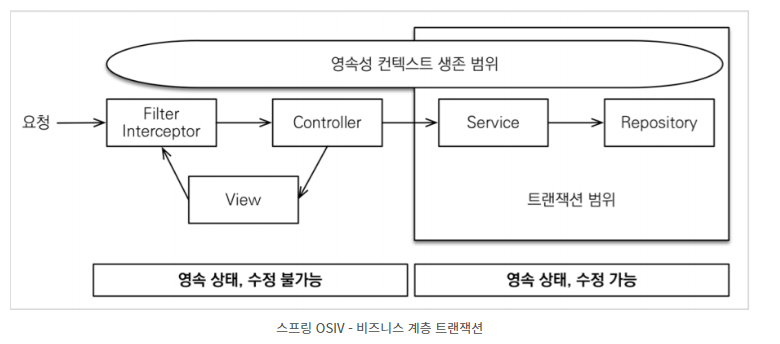
클라이언트 요청으로 일련의 메서드가 다 실행되고 뷰 그리면 영속화된게 사라짐
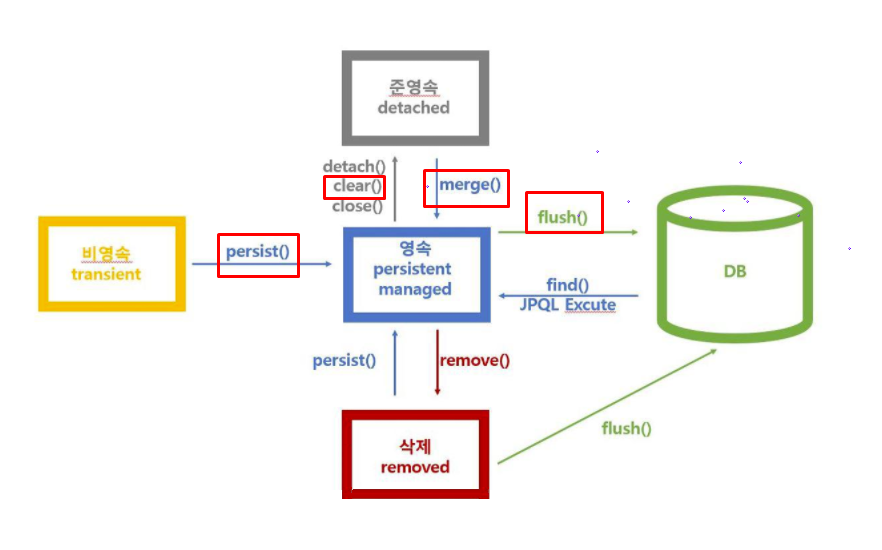
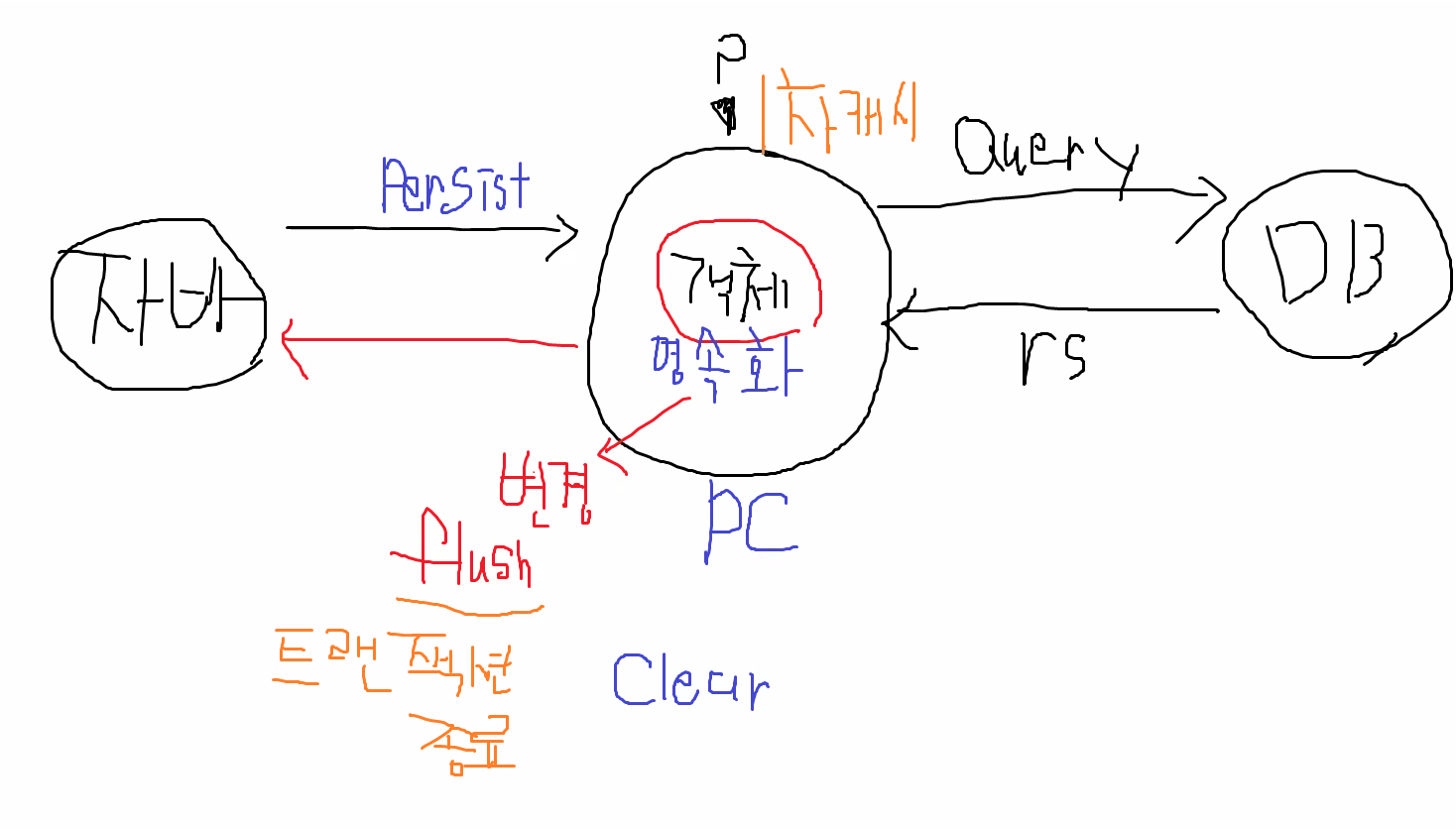
em.persist(entity) : 영속성 컨텍스트에 엔티티 객체를 추가하여 영속화 합니다.
이 때, 엔티티 객체는 DB에 저장되지 않은 상태이며, 영속성 컨텍스트 내에만 존재합니다
em.merge(entity) : 엔티티 객체를 영속성 컨텍스트에 추가하거나, 이미 존재하는 엔티티 객체를 가져와서 변경된 내용을 데이터베이스에 반영합니다.
merge() 메소드는 변경된 엔티티 객체를 반환하며, 이를 통해 엔티티 객체를 계속 사용할 수 있습니다.
em.flush(entity) : 영속성 컨텍스트에 있는 엔티티 객체의 변경 내용을 DB에 반영합니다.
이 때, 데이터베이스에 저장되지 않은 엔티티 객체는 데이터베이스에 저장되지 않습니다.
flush() 메소드는 void 타입을 반환합니다.
트랜잭션 종료시에 자동으로 호출됨 (더티체킹, 더티 체킹 Dirty Checking)
em.clear(entity) : 영속성 컨텍스트에 있는 모든 엔티티 객체를 제거합니다.
이 때, 변경된 내용은 데이터베이스에 반영되지 않습니다.
clear() 메소드는 void 타입을 반환합니다.
4. JPQL with JPA (가장 많이 사용하는 방식)
- JpaRepository가 제공하지 않는다면 일반적으로 아래 문법을 가장 많이 사용함
jpql은 셀렉트만 가능. 인서트 업데이트 딜리트는 불가능
public interface UserRepository extends JpaRepository<User, Integer> {
@Query(value = "select u from User u where u.id= :id")
User findById(@Param("id") Integer id);
}5. NativeQuery with JPA (작성할 일 거의 없음)
- insert, delete, update시에는 save()를 사용하면 되는데, 굳이 직접 쓰고 싶다면 작성해야 함
public interface UserRepository extends JpaRepository<User, Integer> {
@Modifying
@Query(value = "insert into user_tb(created_at, email, password, username) values(now(), :email, :password, :username)", nativeQuery = true)
void mSave(@Param("username") String username, @Param("password") String password, @Param("email") String email);
}JPA n+1 문제
엔티티 조회 쿼리(1 번) + 조회된 엔티티의 연관된 엔티티를 조회하기 위한 추가 쿼리(N 번)
게시글의 fk로 유저가 있으면(모델에 @ManyToOne) db에서 찾을때 게시글 findAll만 하는게 아니라,
그냥 select * from board_tb; 로 찾은 board목록의 user_id컬럼 다른거마다 또 찾아서 성능문제 (user_id컬럼 n개만큼 더 찾아야되니까)
db의 테이블은 컬럼으로 다른 테이블을 못가지는데(다른테이블의 pk만 적어두고) java에선 객체가 다른객체를 필드로 가질 수 있으니까
JPQL 직접 작성하는 방법(fetch로 조인하면서)
@Query("select b from Board b join fetch b.user")
List<Board> mfindAll();fetch를 붙히면 조인해서 쿼리 한번으로 찾음.
select * from board_tb b inner join user_tb u on b.user_id = u.id;
뭐 이런식으로 찾아서 나온걸 JPA가 파싱해서 각각의 board랑 연관된 user랑 객체로 만들고 매핑해서 준다
문제는 JPA의 Pageable 기능을 못씀
지연로딩 방법
board 모델에 user 필드 @ManyToOne 걸 때,
@ManyToOne(fetch = FetchType.LAZY)
이러면 조회 1번만 하고 board의 필드로 user객체는 id만 있고 나머지는 null로 놔두고 그냥 가져옴
영속화된 객체의 null을 참조하려고 하면, 이시점에서 유저id로 db조회해서 찾아옴
FetchType.EAGER 이 기본값(매니투원 걸린 필드에 값 다른거마다 db찾는거)인데 실무에선 거의 안쓰고 lazy 쓴다
필요할때만 fetch Join으로 eager처럼 가져오기
Fetch Join
public intance MemberRepository extends JpaRepository<Member, Long>{
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin()
}이렇게되면 회원 엔티티를 조회하면서 연관된 팀 엔티티도 함꼐 조회하게 됩니다.
프록시 객체로 가져오지 않고 Team 엔티티를 정확히 가져옵니다.
조회의 주체가 되는 Entity 이외에 Fetch Join이 걸린 연관 Entity도 함께 SELECT하여 모두 영속화 시킵니다.
DB의 테이블 = 릴레이션 = 엔티티
DB에서 ResultSet으로 받아서 ORM해서 Entity로 바꿔줌
Entity가 아니라 DTO로 받으려면(repository dto 로 바로) QLRM 라이브러리 써서 받아야함
그래서 일단 Repository에서 받을땐 엔티티로 받음
뷰(프런트엔드)에게 넘길때 Entity로 넘겨서 필요 없는 필드까지 주는거보다 DTO로 필요한거만 넘겨야함
Service에서 Controller로 넘길때 DTO로 넘기는게 좋음
(엔티티랑 필드가 같아도 만들자 나중에 필드 바꿔야 할수도 있고)
dto만들때 매개변수로 엔티티 자체를 넣어서 dto생성자에서 만들면 편함
public SaveDTO(Board board) {
this.title = board.getTitle();
this.content = board.getContent();
}