
-
Abstract
- 이 논문에서 “딥러닝”을 사용해 추천시스템의 성능을 향상
- Deep candidate generation model
- Separate deep ranking model
- YouTube의 3가지 이슈
- Scale:
- 기존 알고리즘들은 유튜브처럼 큰 scale에서 잘 작동하지 않음
- 추천시스템은 distributed learning 적용한 알고리즘 필요, 엄청난 양의 corpus와 사용자를 커버할 수 있는 latency도 보장되어야 함
- Freshness:
- 매 초마다 엄청난 양의 새로운 비디오 업로드 / 새로운 비디오에대한 사용자들의 반응 발생
- 추천시스템은 이러한 실시간 반응 요소들을 잘 반영해야함
- Noise:
- 수많은 외부 요인과 sparsity 때문에 예측은 쉽지 않음
- Explicit feedback 사용이 어려워 implicit feedback을 사용
- Scale:
- 이 논문에서 “딥러닝”을 사용해 추천시스템의 성능을 향상
-
System Overview
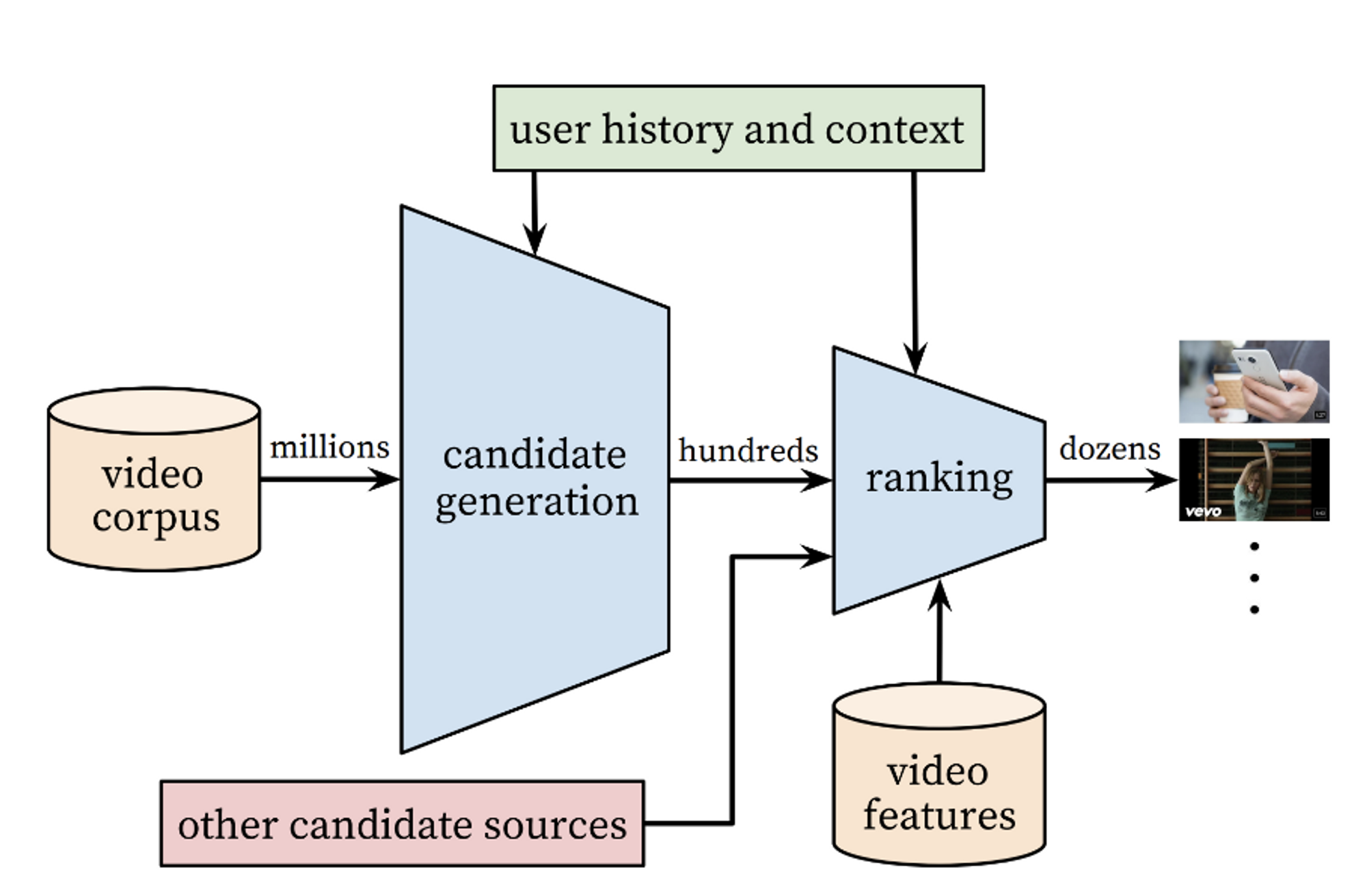
2개의 Neural Network으로 구성 : Candidate generation & Ranking
- Candidate generation (후보 생성 단계) : millions → hundreds
- input: 사용자의 YouTube 활동 기록 / output: large corpus에서 어느정도 개인화 된 비디오
- 협업 필터링을 통한 broad한 개인화만을 제공
- user와의 유사도: coarse feature로 계산 ( ex. IDs of video watches, search query tokens, and demographics )
- Ranking : hundreds → dozens
- 각 비디오 별 점수를 매겨 높은 점수의 비디오가 user에게 표시
- 2단계 추천 알고리즘을 통해 user에 맞게 개인화된 비디오 표시
- Candidate generation (후보 생성 단계) : millions → hundreds
-
Candidate Generation (후보 생성 단계)
-
이전에는 rank loss를 기반으로 한 matrix factorization 사용
-
이 논문에서는 user의 과거 시청기록 임베딩과 neural network을 사용 → non-linear generalization of factorization
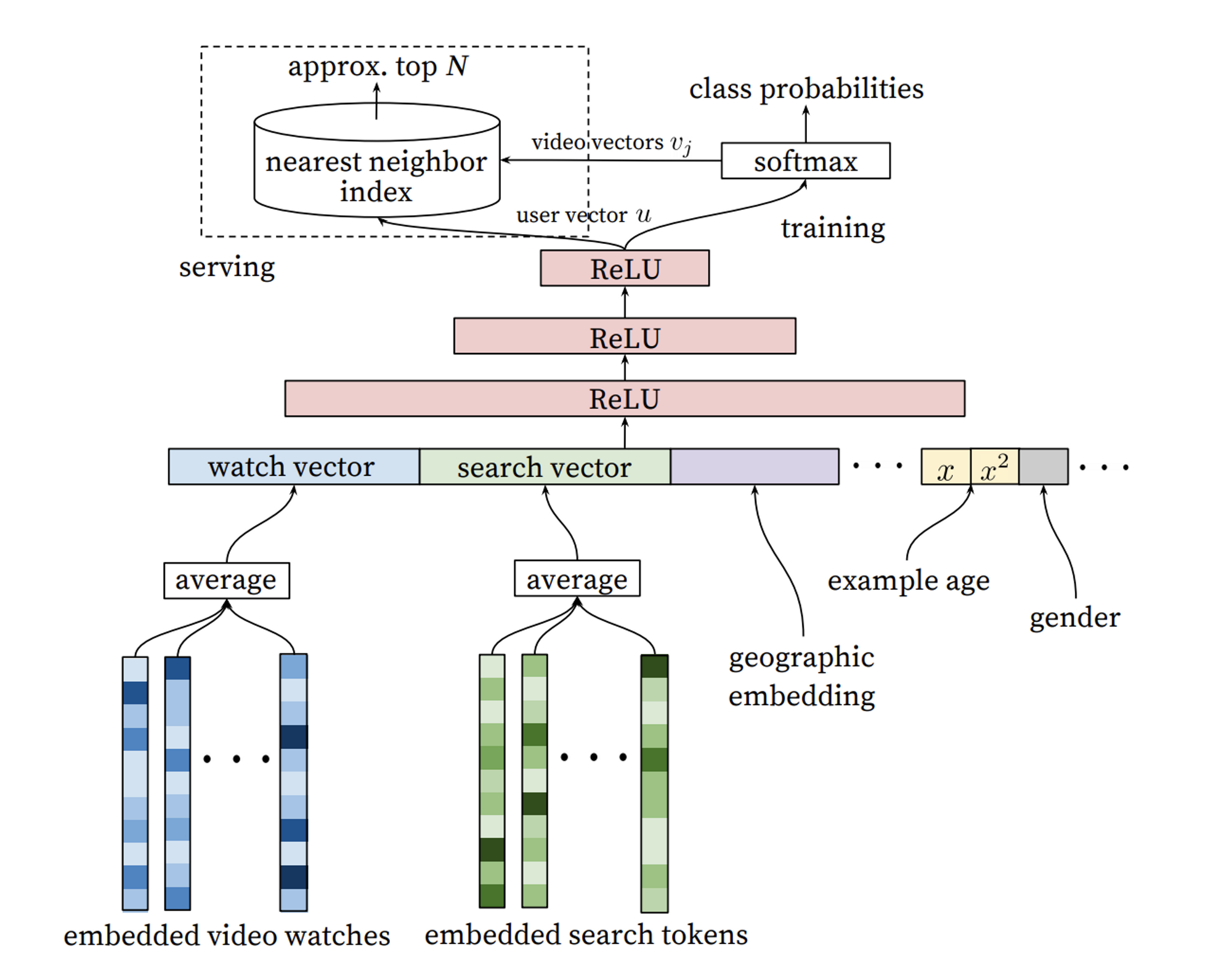
- 구조
- 비디오 시청기록과 search token이 dense vector로 임베딩
- 임베딩된 벡터들의 average를 내 fixed-size input으로 바꿔줌
- fully-connected layer + ReLu
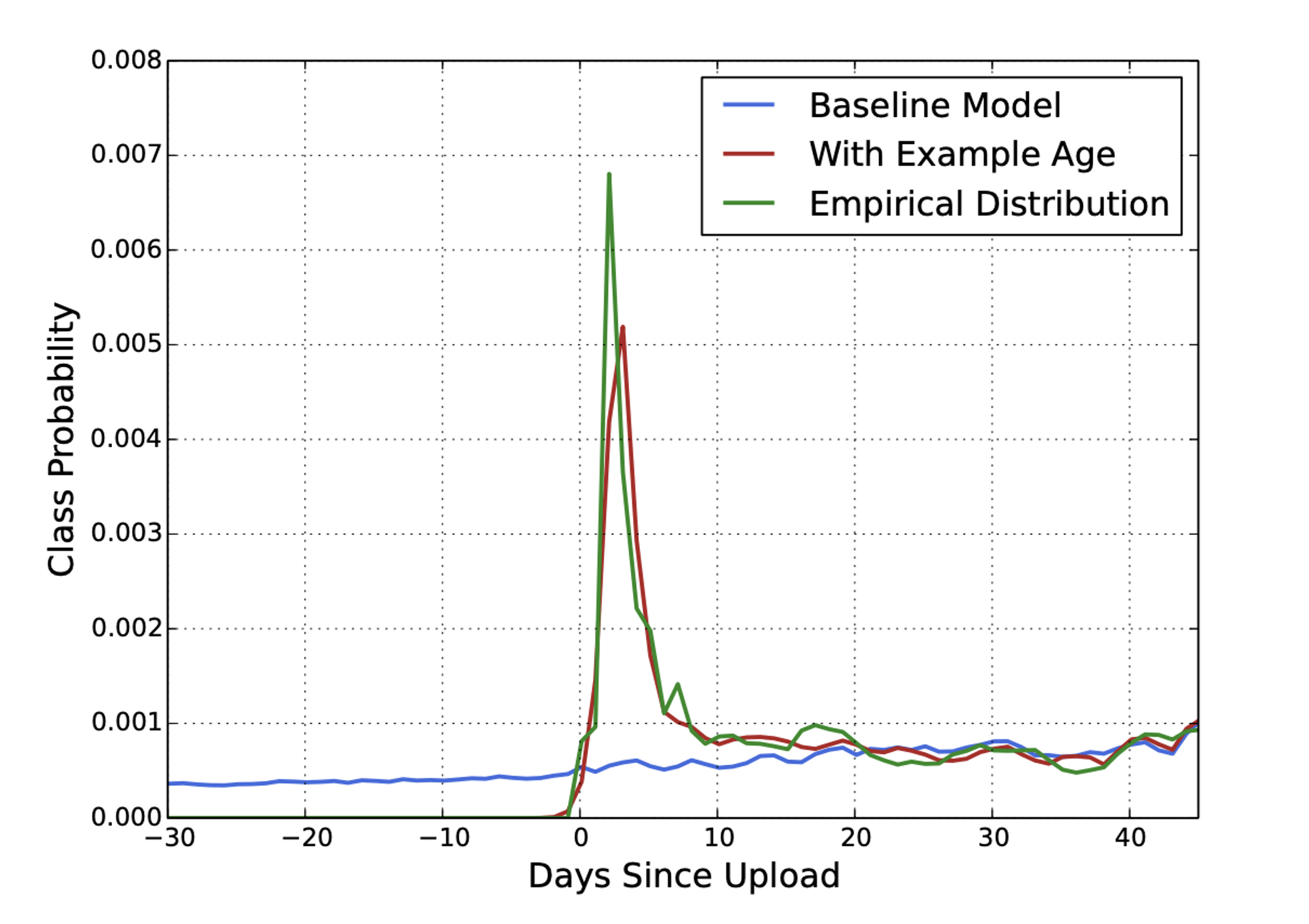
- “ Example Age (영상의 나이) ” Feature의 중요성
- YouTube의 Freshness에 따라 새로운 업로드된 영상을 추천하는 것도 중요
- 머신러닝 시스템은 과거 데이터로 미래를 예측 → 보통 과거의 아이템을 추천하는 경향이 있음
- 아래 그림에서 “Example Age” 추가 후 성능 향상을 보여줌
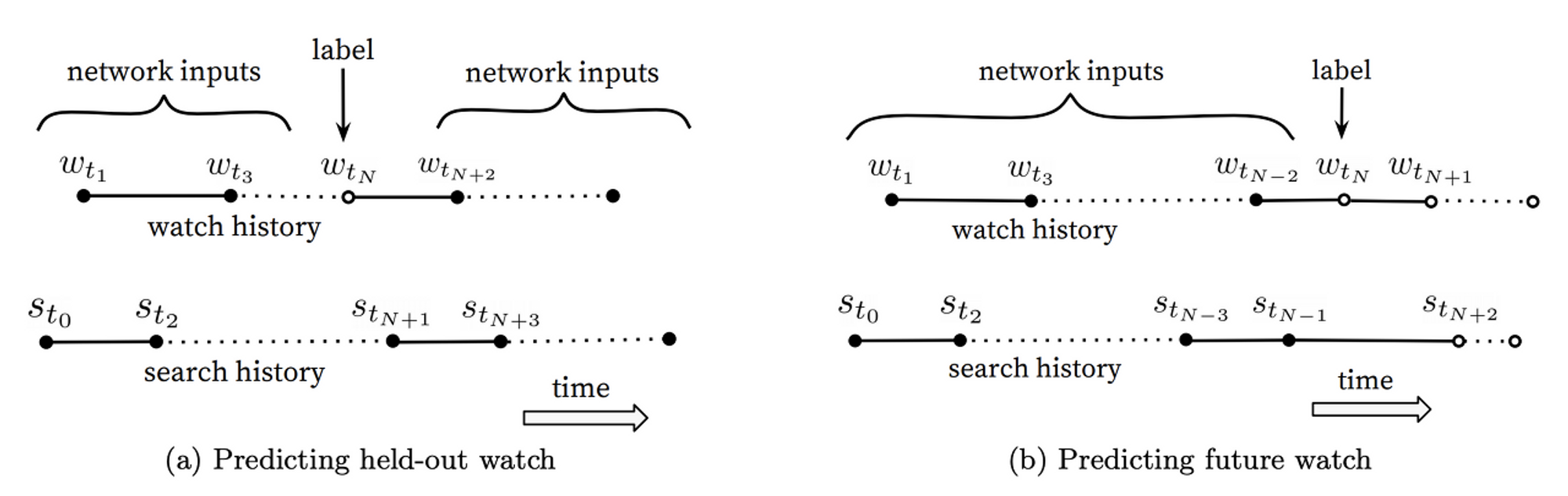
- Label and Context Selection
- YouTube 웹사이트 뿐 아니라 다른 웹사이트로부터의 유입까지 포함
- 영상의 소비 패턴은 비대칭
- 실제 라벨의 지점에서 랜덤하게 샘플링 X → 이전의 데이터만 샘플링
- 즉, 특정 지점에서의 과거 데이터만으로 다음 예측 진행
- 구조
-
-
Ranking
-
후보 아이템들을 특성화하고 교정하는 단계
-
점수가 비교되지 않은 다양한 후보 소스를 ensemble하는데도 중요
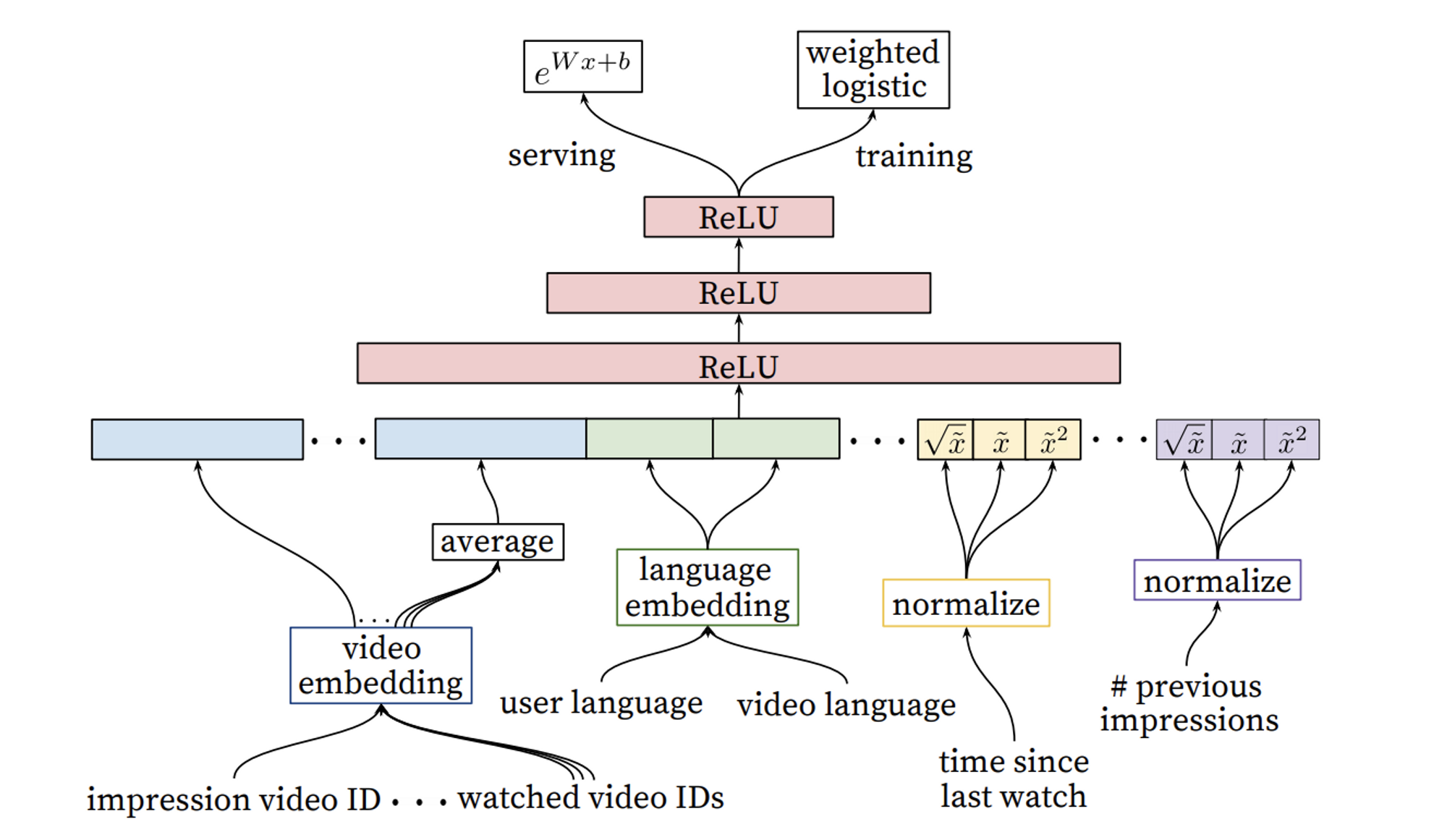
- 구조
- 앞의 모델과 같은 embedding 사용 / continuous feature는 normalize
- training 시 weighted logistic 사용
- A/B test를 통해서 계속 업데이트 - Modeling Expected Watch Time
- 추천 영상을 얼마나 오랫동안 볼지 예측하는 것이 목표
- 감상시간은 안 봤으면 0, 봤으면 본 시간을 값 → 감상 시간으로 가중치
- 원래는 CTR로 구축
- 구조
-
-
Conclusion
- 이 논문에서 사용한 deep collaborative filtering model은 YouTube에서 기존에 사용한 matrix factorization 방식보다 더 나은 성능
- input 데이터로 “영상의 나이”를 추가 → 성능 향상
- Ranking 모델의 경우 아직 고전 모델에 해당 하지만 이 논문에서 사용하는 모델이 기존 tree 혹은 linear 모델보다 더 나은 성능

좋은 글 잘 보고 갑니다^_^