Machine Learning by professor Andrew Ng in Coursera
Photo OCR
1) Problem Description and Pipeline
The Photo OCR problem
Photo Optical Character Recognition
-
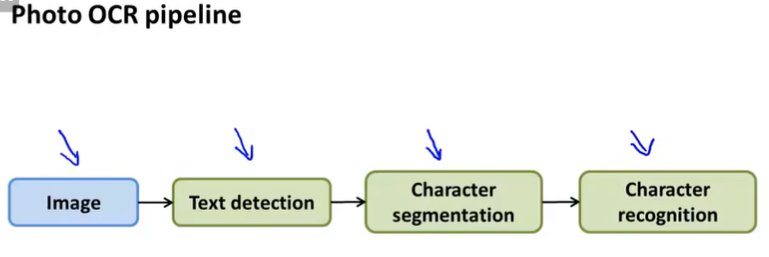
Text detection
주어진 사진에서 텍스트 부분을 감지한다.
sliding window -
Character segmentation
 1D sliding window
1D sliding window -
Character classification

이러한 시스템을 파이프라인 이라고 한다.
2) Sliding Windows
Text detection

1D Sliding window for character segmentation

3) Getting Lots of Data and Artificial Data
Aritificial data synthesis for photo OCR

데이터를 무한으로 만들어낼 수 있다.
Synthesizing data by introducing distortions
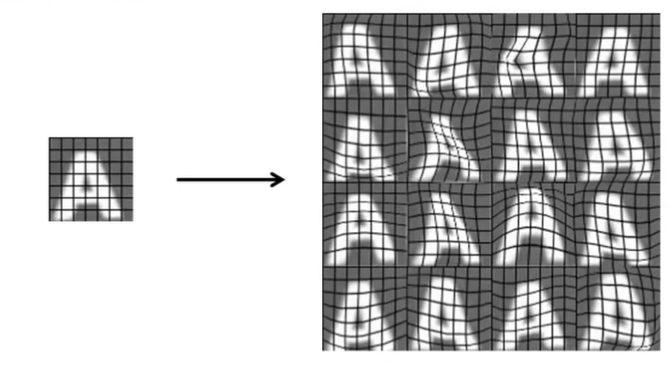
16개의 새로운 데이터를 만들어 냈다.
amplify
 의미없는 노이즈는 별 도움이 되지 않는다.
의미없는 노이즈는 별 도움이 되지 않는다.
Discussion on getting more data
- 위와 같이 데이터를 늘리는 노력을 하기 전에 우선 분류기가 low bias를 가졌는지를 확인해야 한다. 그래야 데이터를 늘리는 것이 의미가 있기 때문이다.
plot curve 그래프를 통해 low bias 여부를 확인한다.
만약 low bias 분류기가 아니라면 low bias가 될 때까지 feature의 개수를 늘리거나 neural network의 hidden unit 개수를 늘린다. - "How much work would it be to get 10x as much data as we currently have?"
라는 질문에 대해 생각해 본다.
- Artificial data synthesis
- Collect / label it yourself
- "Crowd source"
3) Ceiling Analysis: What Part of the Pipeline to Work on Next
Estimating the errors due to each component (ceiling analysis)
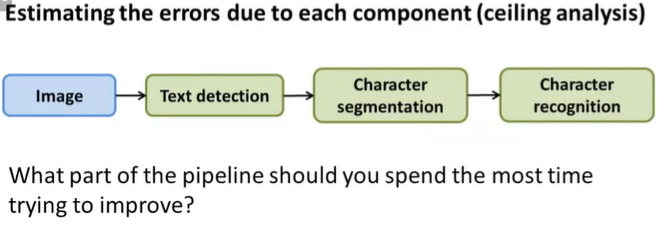
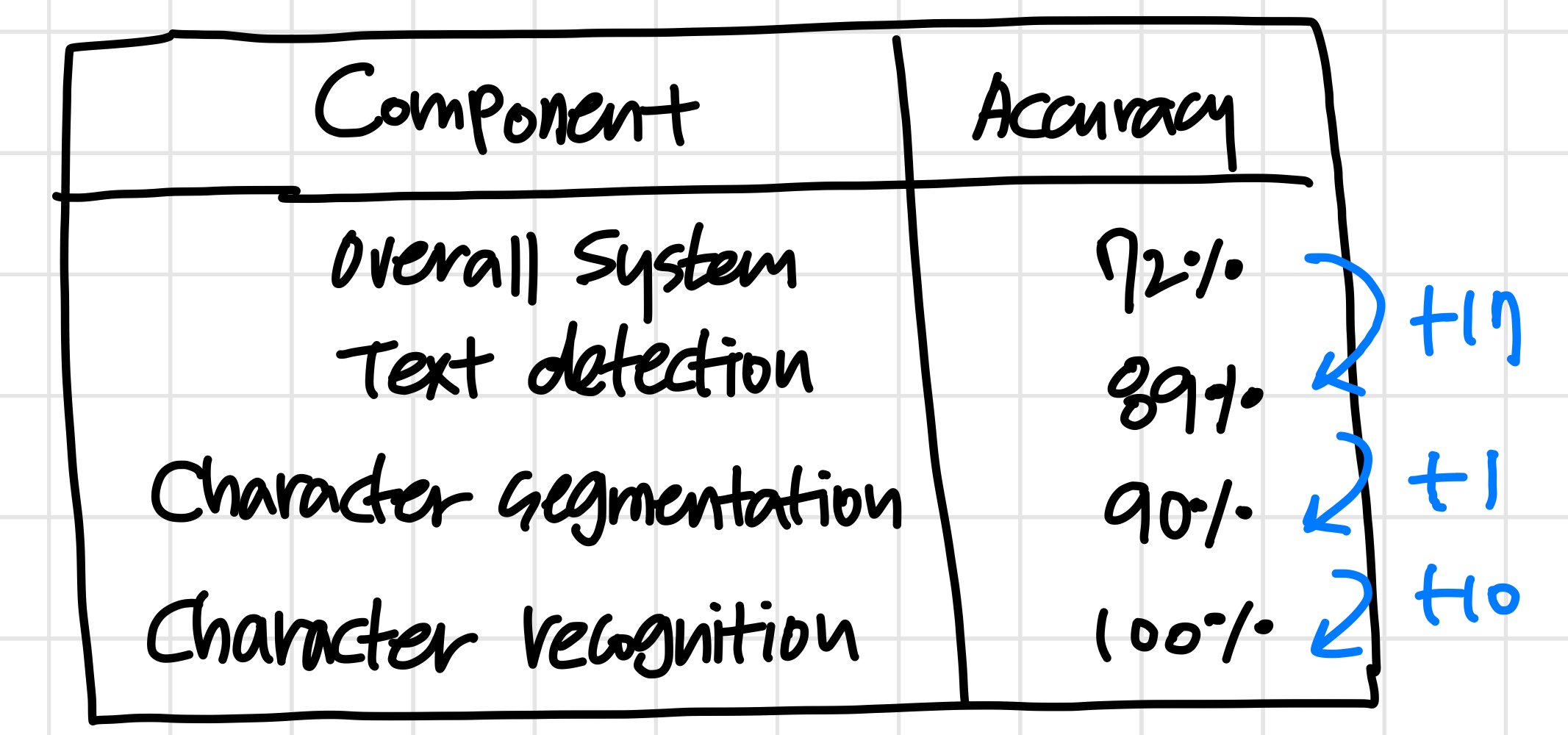
우선 전체 시스템의 accuracy는 72% 다.
1.
Text detection이 100%의 정확도를 가진다고 가정한다.
100% 정확도를 갖는 결과를 가지고 이후의 Character segmentation, Character recognition을 진행한다.
그러면 전체 시스템의 정확도는 89%가 된다.
2.
Character segmentation이 100%의 정확도를 가진다고 가정하고 나머지 단계들을 실행한다.
전체 시스템의 정확도는 90%가 된다.
3.
Character recognition이 100%의 정확도를 가진다고 가정한다.
전체 시스템의 정확도는 당연히 100%가 된다.
정리하면
- Text detection에 시간을 들여 정확도를 최대한 올렸을 때 최대 17(89 - 82)% 만큼의 성능을 높일 수 있다.
- Character segmentation에 시간들 들여 정확도를 최대한 올렸을 때 최대 1(90 - 89)% 만큼의 성능을 높일 수 있다.
- Character recognition에 시간을 들여 정확도를 최대한 올렸을 때 최대 10(100 - 90)% 만큼의 성능을 높일 수 있다.
ceiling , 최대 얼만큼 성능 향상을 할 수 있는지

개똥이