자바에서 병렬 작업이나 비동기 처리는 스레드 단위로 수행된다.
이러한 스레드의 생성과 관리를 효율적으로 처리하기 위해 Thread Pool을 사용한다.
ThreadPoolExecutor는 스레드 풀의 생성, 재사용, 큐 관리, 종료 등을 담당하는 핵심 클래스다. 즉,
여러 개의 스레드를 미리 생성해 두고,
작업이 들어오면 기존 스레드를 재사용하며,
스레드 생성과 종료에 드는 오버헤드를 줄여,
전체 성능을 향상시킬 수 있는 것이다!
또한 ThreadPoolExecutor는 Executor 인터페이스를 구현한 클래스라 ExecutorService와 함께 스레드 관리를 추상화하여
개발자가 직접 스레드를 관리하지 않아도 되도록 한다.
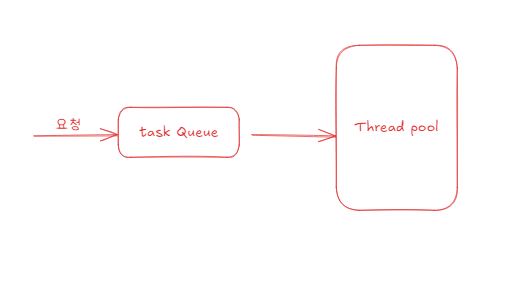
위 그림을 보자.
요청이 들어오면, 요청은 task Queue에 쌓여 순차적으로 처리된다.
이때, task Queue가 가득 찼음에도 불구하고 요청이 들어오면 어떻게 될까?
정답은 다음과 같다.
요청이 들어오면 — 현재 실행 중인 스레드 수가 corePoolSize 미만이면,
👉 새로운 스레드를 생성해 즉시 처리.
corePoolSize 이상일 때 — 남는 스레드가 없으면
👉 요청은 Queue에 저장되어 대기.
Queue가 가득 찼을 때 — 그래도 새로운 요청이 들어오면
👉 스레드 수를 maximumPoolSize까지 늘려 처리.
스레드도 최대치, Queue도 꽉 찼다면
👉 더 이상 받을 수 없어 RejectedExecutionException이 발생.그럼 ThreadPoolExecutor 사용의 장단점은 뭘까?
장점
성능 향상
매번 스레드를 새로 생성하고 종료하지 않아도 되므로 오버헤드가 줄고, 응답 속도가 빨라진다.
자원 관리 효율성
스레드 개수를 제한하여 시스템 자원을 안정적으로 관리할 수 있다.
작업 큐 관리
대기 중인 작업을 큐에 보관해 순차적으로 처리할 수 있다.
유연한 설정
코어 스레드 수, 최대 스레드 수, 큐의 크기, 거부 정책 등을 상황에 맞게 조정할 수 있다.
추상화된 구조
Executor와 ExecutorService를 통해 개발자가 직접 스레드 생명주기를 제어하지 않아도 된다.
단점
설정 복잡성
코어 수, 큐 크기, 거부 정책 등을 잘못 설정하면 오히려 병목이나 자원 낭비가 발생할 수 있다.
디버깅 어려움
여러 스레드가 동시에 동작하기 때문에 예외 추적이나 상태 파악이 어렵다.
메모리 점유
스레드를 미리 생성해두므로, 작업량이 적은 환경에서는 불필요한 자원 사용이 생길 수 있다.
부적절한 사용 시 위험
무한 큐나 너무 큰 풀 크기를 설정하면, 요청이 몰릴 때 OutOfMemoryError 등의 문제가 발생할 수 있다.
장단점을 잘 생각해서 써야겠지~
