JOIN FETCH는 SQL의 조인이랑은 다릅니다. JOIN FETCH는 JPQL에서 성능 최적화를 위해 제공하는 기능으로써, 연관된 엔티티나 컬렉션을 한번에 함께 조회가 가능하도록 하는 기능입니다.
예를 들어, Member엔티티와 연관 관계가 성립되어 있는 Team도 같이 조회하고 싶을때, JPQL에서는 'select m from Member m join fetch m.team' 으로 각 Member 엔티티와 해당 엔티티와 연관되어 있는 Team의 엔티티도 조회가 가능 합니다. SQL문으로는 'SELECT M., T. FROM MEMBER M
INNER JOIN TEAM T ON M.TEAM_ID=T.ID ' 와 동일 합니다.
1. JOIN FETCH X vs. JOIN FETCH O
JOIN FETCH X
String queryA = "select m from Member m";
List<Member> resultListA = em.createQuery(queryA, Member.class)
.getResultList();
for (Member member : resultListA) {
System.out.println("member.getUsername() = " + member.getUsername()
+ ", member.getTeam().getName() = " + member.getTeam().getName()); /**
* RESULT:
* select
* team0_.id as id1_3_0_,
* team0_.name as name2_3_0_
* from
* Team team0_
* where
* team0_.id=?
* member.getUsername() = MemberA, member.getTeam().getName() = TeamA
* member.getUsername() = MemberB, member.getTeam().getName() = TeamA
* Hibernate:
* select
* team0_.id as id1_3_0_,
* team0_.name as name2_3_0_
* from
* Team team0_
* where
* team0_.id=?
* member.getUsername() = MemberC, member.getTeam().getName() = TeamB
*/
- MemberA, teamA => DB => 영속성 컨텍스트에 teamA가 없기 때문에 SQL문으로 DB에서 가져옴
- MemberB, teamA => 1차 캐시 => MemberA때 teamA가 영속성 컨텍스트에 추가 됐기 때문에 영속성 컨텍스트/1차 캐시에서 가져옴
- MemberC, teamB => DB => 양속성 컨텍스트에 teamB가 없기 때문에 SQL문으로 DB에서 가져옴
- 그러므로, 만약에 각 회원이 각각 다른팀에 소속되어 있으면, 팀의 갯수 만큼 쿼리문이 날라감 => 성능 저하, N+1
- 이런 문제점을 해결하기 위해 fetch join 사용
JOIN FETCH O
String queryB = "select m from Member m join fetch m.team";
List<Member> resultListB = em.createQuery(queryB, Member.class)
.getResultList();
for (Member member : resultListB) {
System.out.println("memberJoinFetch.getUsername() = " + member.getUsername()
+ ", memberJoinFetch.getTeam().getName() = " + member.getTeam().getName()); /**
* RESULT:
* Hibernate:
* /* select
* m
* from
* Member m
* join
* fetch m.team *\/select
* member0_.id as id1_0_0_,
* team1_.id as id1_3_1_,
* member0_.age as age2_0_0_,
* member0_.MEMBER_TYPE as MEMBER_T3_0_0_,
* member0_.TEAM_ID as TEAM_ID5_0_0_,
* member0_.username as username4_0_0_,
* team1_.name as name2_3_1_
* from
* Member member0_
* inner join
* Team team1_
* on member0_.TEAM_ID = team1_.id
* memberJoinFetch.getUsername() = MemberA, memberJoinFetch.getTeam().getName() = TeamA
* memberJoinFetch.getUsername() = MemberB, memberJoinFetch.getTeam().getName() = TeamA
* memberJoinFetch.getUsername() = MemberC, memberJoinFetch.getTeam().getName() = TeamB
* /createQuery() 실행 시, 변화되어서 처리되는 쿼리문을 확인해보면, INNER JOIN을 이용해서 TEAM의 정보도 가져오는 것을 볼 수 있습니다. 이때, 프록시를 사용 하는것이 아니고, INNER JOIN을 통해 반환되는 값을 그대로 저장합니다.
일대다 관계 JOIN FETCH && Distinct
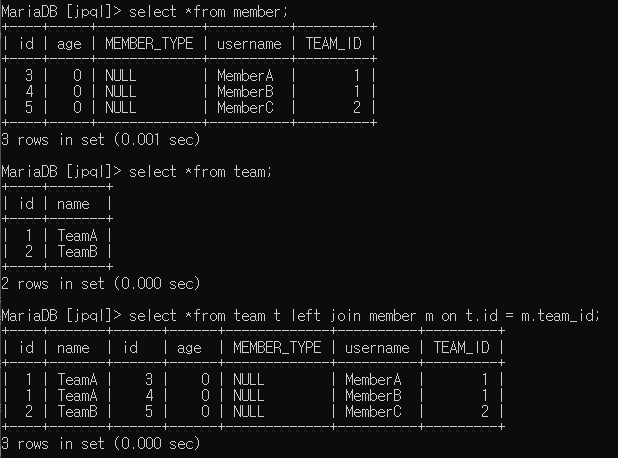
String queryA = "select t from Team t join fetch t.members";
List<Team> resultListA = em.createQuery(queryA, Team.class)
.getResultList();
for (Team team : resultListA) {
System.out.println("team.getName() = " + team.getName() +
", team.getMembers().size() = " + team.getMembers().size());
}
String queryB = "select distinct t from Team t join fetch t.members";
List<Team> resultListB = em.createQuery(queryB, Team.class)
.getResultList();
for (Team team : resultListB) {
System.out.println("team.getName() = " + team.getName() +
", team.getMembers().size() = " + team.getMembers().size());
}queryA 실행 시 결과:
team.getName() = TeamA, team.getMembers().size() = 2
team.getName() = TeamA, team.getMembers().size() = 2
team.getName() = TeamB, team.getMembers().size() = 1
queryB 실행 시 결과:
team.getName() = TeamA, team.getMembers().size() = 2
team.getName() = TeamB, team.getMembers().size() = 1
일대다 관계일때 JOIN FETCH를 실행하면 반횐되는 튜플은 총 3개이므로, queryA 실행 시 resultListA에 3개의 값이 들어가게 됩니다. 하지만, 이는 Team 엔티티 입장에서 봤을때, TeamA 객체가 중복으로 있는 것으로 볼 수 있기 때문에 중복을 제거할 필요가 있습니다. 중복 제거를 위해 queryB에서 보듯이 DISTINCT를 이용해 줍니다.
Distinct를 이용함으로써, Team 엔티티에서 봤을때 TeamA 객체, TeamB 객체가 하나씩 만 존재하며, TeamA 객체안에 각각 다른 Member가 2개 들어가 있는 것을 확인할 수 있습니다.
Distinct를 사용하지 않았을때는 , TeamA 객체가 2개로 중복이 있었는데, 어차피 각 객체에는 Member가 2개씩 들어가 있는 상태이기 때문에 중복 상태입니다.
SQL DISTINCT vs. JPQL DISTINCT

SQL에서 DISTINCT 이용 시, 값을 확인 할려는 모든 Column들이 서로 같은 경우에만 distinct하다고 보기 때문에, 위에서 봤던 예제를 SQL문으로 실행하면 총 3개의 튜플이 반홥됩니다. SQL 측면에서 봤을때는 , TeamA인 값이 2개여도 각각 username은 다르기 때문에 염연히 다른 값인것은 맞습니다.
반면, JPQL에서의 DISTINCT는 SQL문에도 DISTINCT를 추가시켜서 SQL문을 처리하지만, 애플리케이션에서 중복되는 엔티티도 제거해주기 떄문에 queryB 실행 결과가 나오게 됩니다.
JOIN FETCH 유의점
String query = "select t from Team t join fetch t.members";
List<Team> resultList = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();JOIN FETCH 랑 페이징 API(setFirstResult, setMaxResult, etc.)을 함께 사용하면 다음과 같은 경고를 남깁니다.
WARN: HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
이를 해결하기 위해서는 persistence.xml에 batch_fetch_size를 설정해 주던가, Team 엔티티에 @BatchSize(size = ?) 애너태이션을 추가해주면 되지만, 이는 나중에 더 깊게 보도록 하겠습니다.
