2주차의 주제는 주특기 언어 기초와 알고리즘이였고, 일주일 내내 알고리즘만 푸느라고 뇌가 0 or 1 로 사고하는 수준까지 이르게 되었다.. 머리 굴리느라 힘들기도 했지만 나는 다른 동료들과는 다르게 재미있었다. 1주차에 프로젝트를 만들 때에는 뭘하는지도 잘 모르면서 그냥 사용법만 익혀서 만들어냈다면 이번주차에는 하면 할수록 뭔가 배우는 것도 생기고 하나하나 문제를 풀어나가는 성취감도 있어서 힘들지만 보람찬 일주일이였다.
2주차의 핵심은 자바, 그 중에서도 자바의 꽃인 객체지향. 또 하나 중요한 주제를 꼽자면 자바의 메모리 구조. 이거야 말로 자바를 공부한 이래로 미뤄온 숙제 같은 녀석이다. 매번 공부해야지~ 하고 막상 건드리기 귀찮아서 묵혀놓은 주제. 이번 기회에 제대로 공부해 보았다. JVM, JRE, JDK는 무엇이며, 힙 영역이니, 스택 영역이니, 메서드 영역이니 하는 것들을 정리해 보려고 한다. WIL를 두 파트로 나누어서 먼저 메모리 구조에 대해 포스팅하고 다음으로 객체지향에 관해 포스팅하겠다 WIL 시작!
[1] JDK, JRE, JVM
메모리 구조를 공부하기 이 전에 이 세가지 용어에 대해 먼저 알고 지나가자. 처음에 자바를 공부하기 위해 JDK 뭐시기를 설치했었다. 또 여기서 OpenJDK와 OracleJDK로 나뉘는데 둘다 Oracle사가 관리하고 있으며 그냥 종류의 차이정도로 생각하고 넘어가도 될 듯 하다. JDK란 Java Development Kit(자바 개발 도구)의 약자로 자바로 소프트웨어를 개발할 수 있도록 여러 기능을 제공하는 키트이다. 여러 기능 중 몇가지만 소개해 보면
- apt : 어노테이션 툴 (@Overloading 같은거?)
- javac : 자바 소스 코드를 바이트 코드로 변환 해주는 컴파일러.
- java : javac가 컴파일한 파일을 해석 및 실행.
- jar : 서로 관련있는 라이브러리와 리소스를 하나로 묶어주는 툴
- JRE : Java가 동작하는데 필요한 JVM, 라이브러리 등 다양한 파일을 포함한다. Java Runtime Environment의 약자로 말그대로 Java가 잘 작동하게끔 환경을 조성해주는 역할을 한다.
여기서 JRE와 JVM이라는 용어까지 나오게 되었다. 내가 이해한 것이 맞다면 포함관계로 따지면 JDK > JRE > JVM 순인 것 같다. 그렇다면 JVM의 역할은 뭘까? JVM에 대해서는 조금 더 깊이 알아 보려고 한다.
[2] JVM
{1} 자바 구동 원리

지금까지 src 폴더에 ~.java 파일을 생성한 후 코드를 작성해왔다. 그 코드는 근데 컴퓨터가 읽을 수가 없다. 왜냐하면 우리가 지금껏 배워왔던 자바 문법들은 인간 친화적으로 만들어진 언어이기 때문이다.
이 코드를 컴퓨터가 해석할 수 있게끔 변환을 시켜줘야하는데 1차적으로 해석해주는 놈이 바로 위에 언급했던 javac라는 컴파일러이다. 컴파일러는 소스 코드(.java - 우리가 지금껏 작성해 왔던 코드)를 바이트 코드(.class)로 변환시켜 준다. 이 변환된 파일은 out이라는 폴더에 저장된다.
하지만 이 바이트 코드 역시 컴퓨터가 이해하지 못한다. 컴퓨터가 이해할 수 있는 언어는 0과 1로만 이루어진 기계어이다. 바이트 코드를 컴퓨터가 이해할 수 있도록 2차로 해석을 한번 더 해줘야 하는데 이를 JVM이 해석하게 된다.
논외로 번거롭게 왜 두번씩이나 해석을 해야만 하는걸까? 다른 언어의 경우 OS만 거치고 바로 하드웨어에 전달되는데 자바는 그렇지 않다. 이 부분이 자바의 철학인 "Write Once, Run Everywhere"에 해당하는 내용이다. 컴퓨터의 OS는 Windows, mac 등 여러가지가 있는데 이 OS마다 코드를 해석하는 방식이 다르기 때문에 다른 언어의 경우 OS마다 다른 코드를 작성해야 한다. 하지만 자바의 경우 JVM이 각 OS에 맞는 코드로 변환시켜 주기 때문에 자바를 한번 작성하면 어디서든 실행시킬 수 있다는 말이 나온 것이다.
{2} JVM의 구성
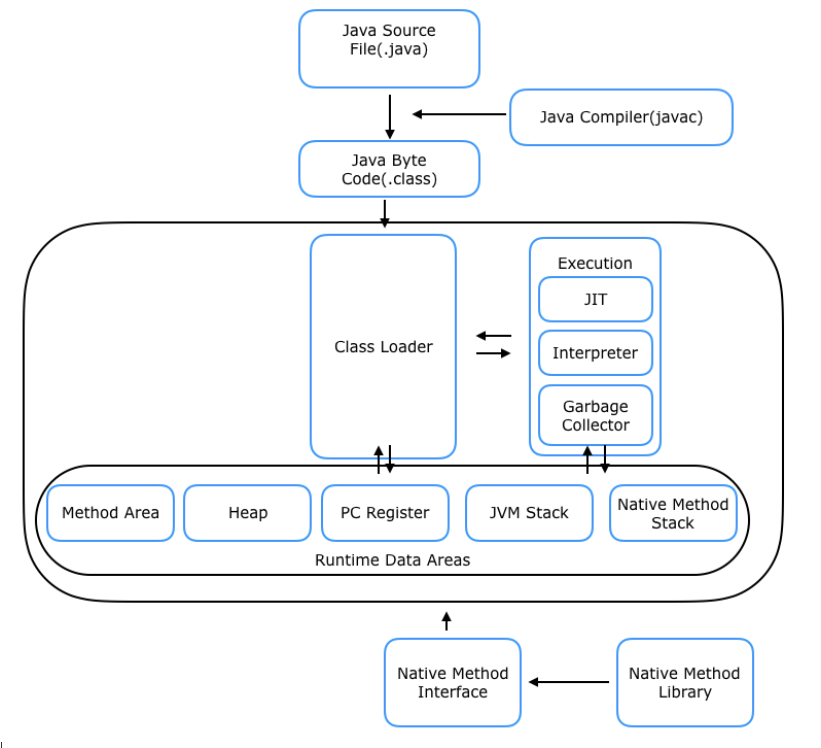
이 중 큰 단위인 Class Loader, Execution Engine, Runtime Data Areas 부터 살펴보자.
(1) 클래스 로더
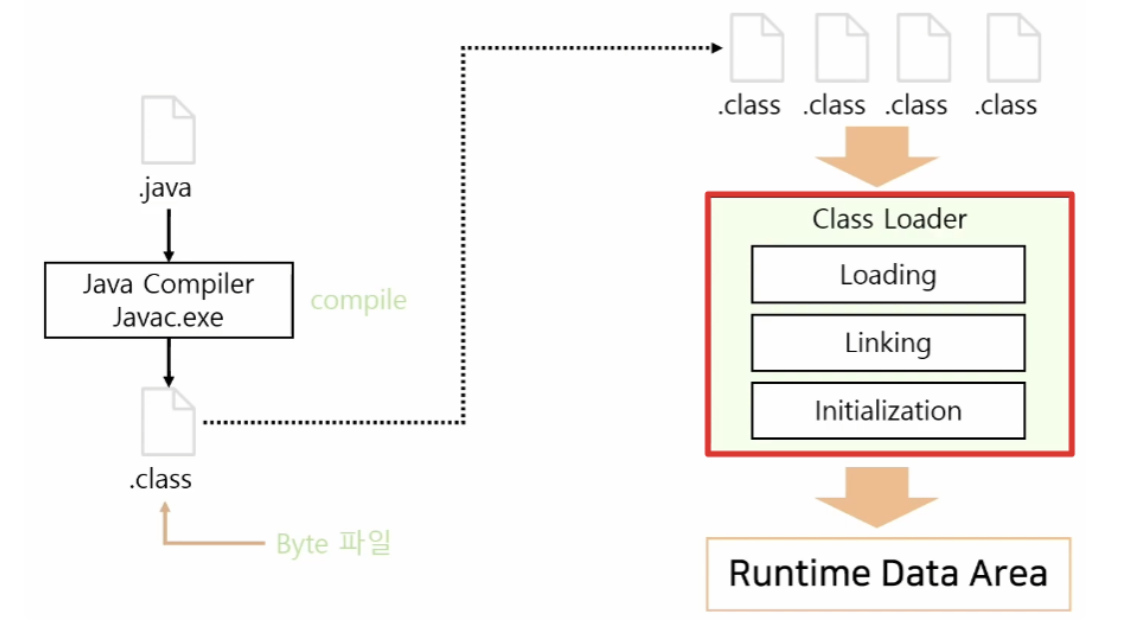
클래스 로더는 말그대로 클래스 파일(.class)를 메모리에 로드, 즉 적재하는 작업을 수행하는 모듈이다. 클래스 로더는 수많은 클래스 파일들을 한번에 메모리에 올리는 것이 아니라, 필요한 경우에 동적으로 메모리에 적재하게 된다. 이 때 클래스 로더가 적재하는 공간이 다음으로 설명할 Runtime Data Area이다.
(2) 런타임 데이터 영역
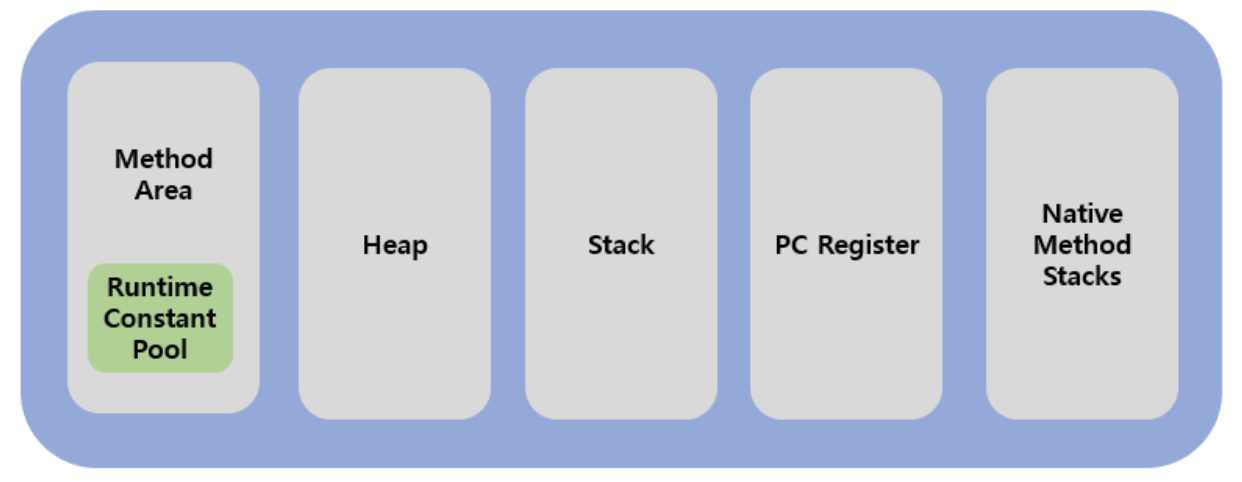
런타임 데이터 영역은 자바 어플리케이션이 실행이 되었을 때 사용되는 데이터들을 적재하는 공간이다. 런타임 데이터 영역도 여러 영역으로 나뉘지만 오늘 알아볼 영역은 Method Area, Heap Area, Stack Area이다. 이 중, Method Area와 Heap Area는 모든 쓰레드가 공유하는 영역이고, Stack Area는 각 쓰레드마다 개별 생성되는 영역이다.
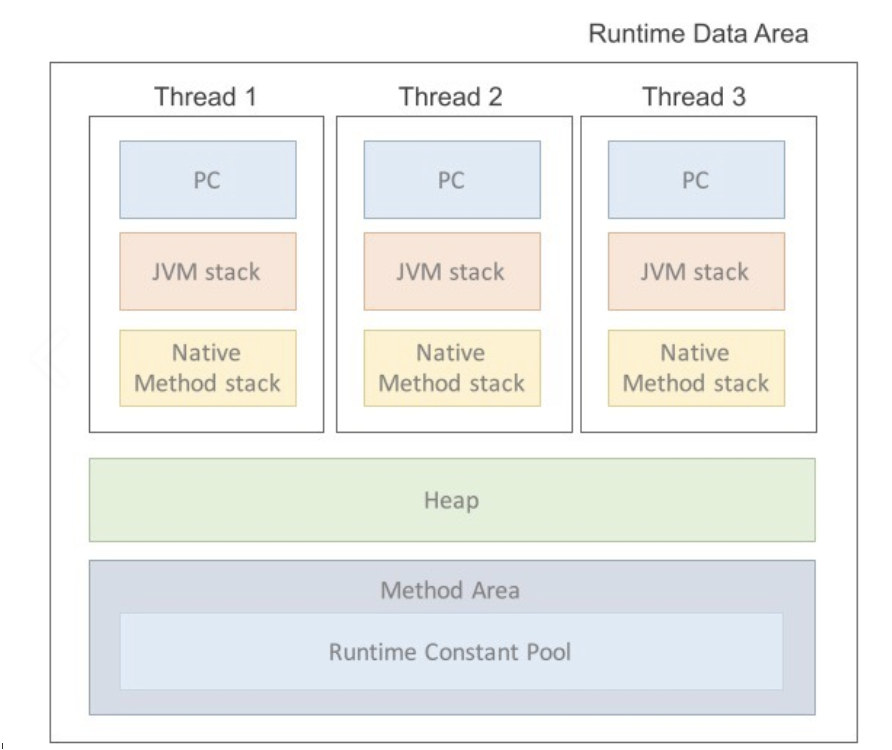
"1" 메서드 영역
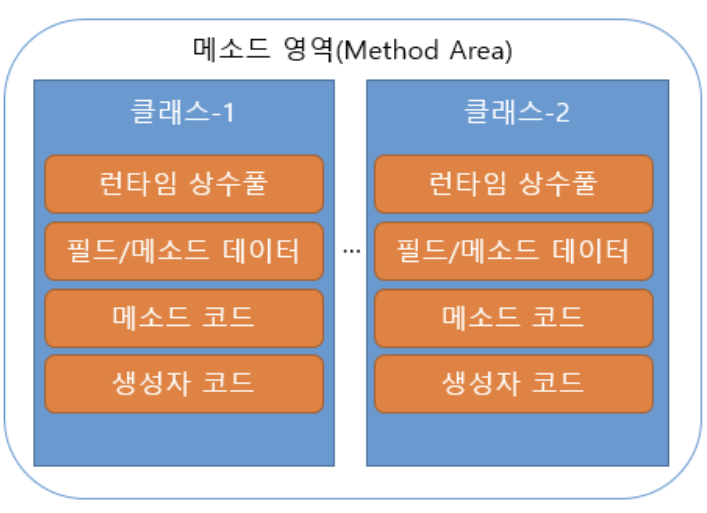
메서드 영역은 JVM이 시작될 때 생성되는 영역으로 바이트 코드를 제일 처음 메모리에 올릴 때 초기화되는 대상을 저장하기 위한 공간이다. JVM이 동작하고 클래스가 로드될 때 적재되서 프로그램이 종료될 때까지 저장된다. 이 영역에 저장되는 데이터들은 클래스 구조(Type, 접근제어자 등), 메서드(메서드 이름, 반환 타입 등)이다.
"2" 스택 영역
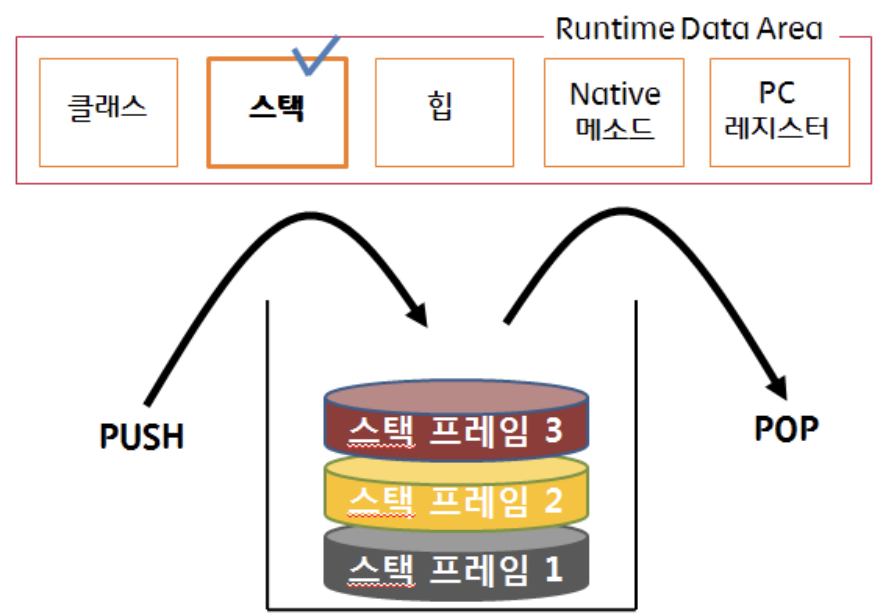
스택 영역은 int, boolean 등 기본 자료형을 생성할 때 저장하는 공간으로, 지역변수 등의 데이터가 저장된다. Stack의 말 뜻처럼 데이터 저장 방식이 LIFO(나중 데이터가 제일 처음 나가는)이다. 메서드를 호출할 때마다 스택 프레임(호출한 메서드만을 위한 공간)이 생성이 되고 메서드 안에 생성되는 값, 매개변수, 지역변수, 리턴값 등이 스택 프레임 안에 저장된다. 그리고 메서드의 수행이 완료되면 스택프레임이 제거되고 그 밑의 스택프레임이 또 수행하게 된다.
위에 언급한 것처럼 스택 영역에 저장되는 데이터는 기본 자료형 변수들의 값들이 저장된다. 그렇다면 참조형 변수는 어디에 저장될까? 먼저 참조형 변수의 동작 원리는 말그대로 reference 변수이므로 데이터는 다른 어떤 영역에 저장이 되고, 데이터가 저장되어 있는 주소가 참조 변수 안에 저장이 된다. 참조 변수에 저장되어 있는 주소값은 스택 영역에 저장되지만 그 주소가 가르키는 데이터의 값은 Heap 영역이라는 곳에 저장이 된다.
"3" 힙 영역
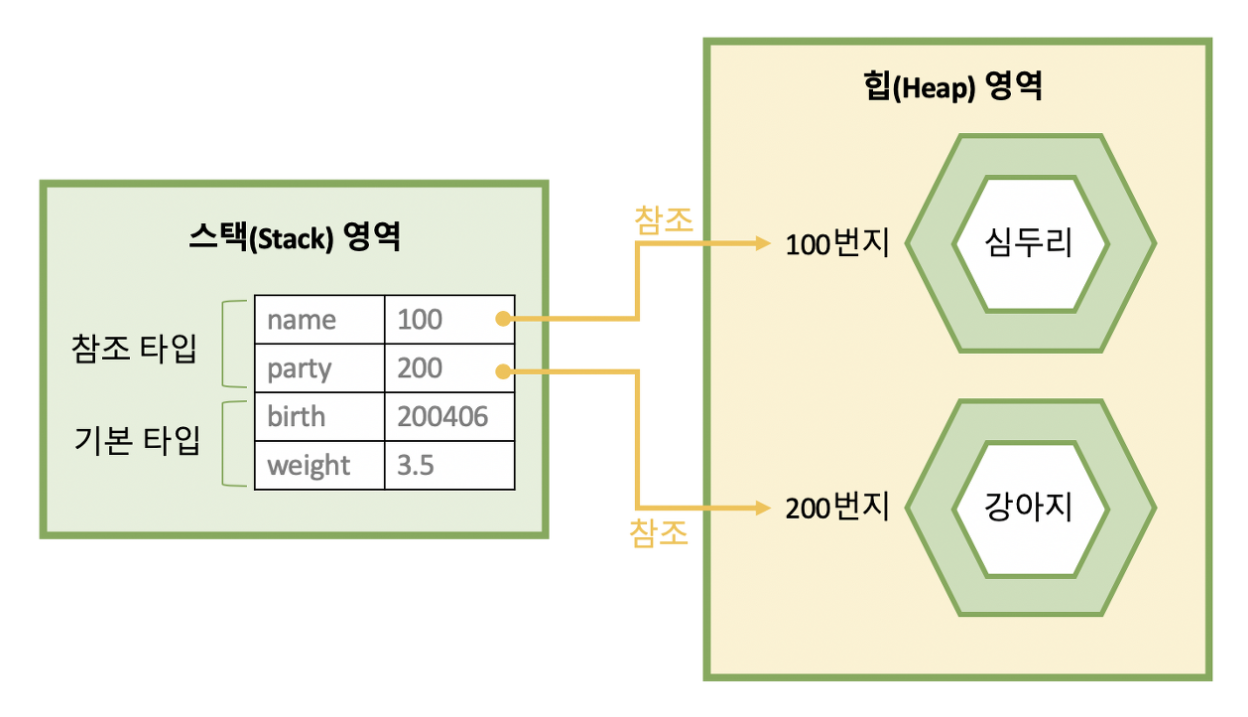
위에 설명했던 것과 같이 기본 타입 변수의 데이터나 참조 변수의 주소값은 스택 영역에 저장이 되고 참조 변수 주소값이 가르키는 데이터는 힙 영역에 저장이 된다. 여기서 한가지 알 수 있는 사실은 참조 변수에는 보통 클래스의 인스턴스 혹은 배열의 주소값 등이 저장된다. 이미 내가 알고 있었던 지식으로부터 힙 영역에 어떤 데이터들이 저장되어 있는지 유추해 볼 수가 있는 것이다.
그렇다면 예를 들어 배열의 어떤 요소를 수정해서 주소값이 달라졌다던가, 한 인스턴스를 가르키고 있던 참조변수가 다른 인스턴스를 가르키게 되어 주인이 없어진 데이터들은 어떻게 될까? 이 데이터들은 다음으로 이야기할 Execution Engine에서 처리하게 된다.
(3) 실행 엔진
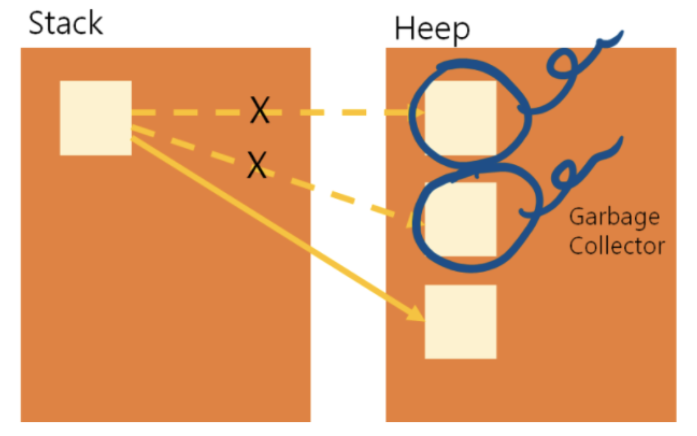
주인을 잃은 데이터는 실행 엔진 내의 가비지 컬렉터(Garbage Collector, GC)가 자동으로 삭제를 해준다.

실행 엔진의 이보다 더 중요한 역할은 클래스 로더를 통해 런타임 데이터 영역에 배치된 바이트 코드를 명령어 단위로 실행하는 역할을 한다. 위에 언급했듯이 바이트 코드(.class)는 기계가 읽을 수 없는 언어이기 때문에 실행 엔진이 바이트 코드를 기계가 실행할 수 있는 형태로 바꿔준다. 이미지에서 확인할 수 있듯이 실행 엔진 내의 인터프리터와 JIT 컴파일러 이 두 가지 방식을 혼합하여 바이트 코드를 실행한다.
