3주차에는 주특기인 Sping을 배우는 시간이다. Spring을 배우기에 앞서 JPA에 대해 알아보려고 한다.
[1] JPA
{1} 사전 지식
(1) RDBMS
Relational DataBase Management System, 관계형 데이터베이스 관리 시스템은 데이터가 하나 이상의 열과 행의 테이블(관계)에 저장되어 서로 다른 데이터 구조가 어떻게 관련되어 있는지 쉽게 파악하고 이해할 수 있도록 사전 정의된 관계로 데이터를 구성하는 정보 모음이다. 즉, 데이터 관리자가 사전에 데이터를 구조화 시켜서 테이블마다 논리적인 연결을 지음으로서 관계를 맺도록 해서 데이터의 CRUD를 더욱 쉽게 할 수 있도록 해주는 시스템이다.
(2) SQL
Structure Query Language, SQL은 관계형 데이터베이스에 정보를 저장하고 처리하기 위한 프로그래밍 언어이다. 관계형 데이터베이스는 위에 설명했듯이 데이터를 열과 행이 존재하는 테이블에 저장하며, 행,열은 다양한 데이터 속성과 값 간의 관계를 맺어준다. 이렇게 구조화된 데이터를 CRUD를 할 때 쓰이는 언어가 바로 SQL이다.
MySQL
MySQL은 Oracle사가 관리하는 오픈소스 관계형 데이터베이스 관리 시스템이다. SQL이 RDBMS에서 데이터를 CRUD하기 위해 사용되는 언어라면, MySQL은 이러한 SQL을 사용하는 오픈소스 RDBMS이다.
noSQL
not only SQL은 기존의 RDBMS가 가지고 있는 특성뿐만 아니라 비정형적인 데이터를 관리할 수 있는 데이터베이스 관리 시스템이다. 2000년대부터 인터넷이 활성화되면서 실시간 어플리케이션(SNS, 쇼핑몰 등)이나 빅데이터를 다루는데 noSQL을 사용한다. 사전 프로젝트와 1주차 프로젝트 때는 사용하면서도 몰랐지만 mongoDB가 noSQL의 대표적인 예이다. noSQL 데이터베이스는 데이터의 단순 검색이나 추가 작업에 있어 매우 최적화된 키값 저장 기법을 사용해서 응답 속도나 처리 효율에 있어서 매우 뛰어난 성능을 가지고 있다.
{2} JPA 탄생 배경
웹 어플리케이션을 만들기 위해서는 클라이언트 - 서버 - 데이터 베이스의 상호 작용이 있어야 한다. 클라이언트에서 특정 주소로 데이터를 요청하게 되면 서버에서는 그 주소에 필요한 데이터를 찾기 위해 데이터 베이스에서 데이터를 불러온다. 이 때 필요한 언어가 위에 언급했듯이 SQL이다. 따라서 서버 개발자는 객체 지향 언어(Java 등)을 사용해서 객체를 생성하고, 이 데이터를 관계형 데이터베이스에 저장하기 위해 SQL을 또 작성해야만 했다.
예를 들어 홈페이지의 회원을 관리하기 위해 Member라는 클래스를 만들고 각 회원의 정보를 담은 객체를 만든 후에, 이를 SQL문으로 작성해서 데이터베이스에 저장하고, 또 그 회원 정보를 필요로 할 때에는 SQL문에서 객체 지향 언어로 객체로 받아와서 클라이언트에 응답하는 등 지루한 코드가 반복되는 현상이 발생했다.
또한 OOP의 특징인 추상화, 캡슐화, 정보 은닉, 상속, 다형성 등에 따라 객체를 만들지만, RDB에는 데이터를 잘 정규화해서 보관하는 것이 목표이기 때문에 철학이 다른 두가지를 억지로 매핑하려고 하기 때문에 여러 문제가 생기곤 한다.
이런 이유들 때문에 개발자는 객체지향에 초점을 맞추기 보다는 SQL문을 이용해서 RDB에 데이터를 잘 보관하는데에 더 초점을 맞추게 되었다. 객체를 자바의 컬렉션에 저장하고 불러오듯이 DB에 저장할 수 있는 방법이 없을까? 에 대한 고민에서 나온 것이 바로 JPA이다.
{3} JPA란?
(1) ORM
Object Relational Mapping, 객체 관계 매핑이란 말그대로 객체(Object)를 관계형(Relational) 데이터베이스에 매핑을 하는데 객체는 객체대로 RDB는 RDB대로 설계하는 것이다. ORM은 각각 설계한 것을 중간에서 매핑해주는 역할을 하는 프레임워크이다. 앞서 언급했던 문제인 억지로 객체를 SQL문을 통해 RDB에 매핑함으로써 생기는 문제들을 해결할 수 있는 방법이 된다.
(2) EJB
Entity Java Bean은 과거에 자바 표준 ORM이였던 것으로 이를 통해 JDBC(자바에서 데이터베이스에 접속할 수 있도록 도와주는 자바 API)를 직접 제어하지 않아도 되었지만 복잡한 사용성과 빌드, 테스트 시에 불편함, 무거움 때문에 JPA로 대체되어 JPA가 현재 자바의 ORM 기술 표준이 되었다.
(3) JPA
EJB를 대체한 자바의 ORM 기술 표준이며, 객체는 객체 대로 RDB는 RDB 대로 설계를 하더라도 JPA가 자동으로 매핑을 해주기 때문에 SQL 문을 작성하지 않아도 되었기 때문에 유지보수를 할 때에도 SQL 문을 손댈 필요없이 필드만 변경해주면 되고, 또한 객체지향적인 코드를 작성할 수 있게 되었고, OOP와 RDB 사이의 패라다임 불일치를 해결해 주었다.
(4) Hibernate
JPA는 인터페이스의 모음이기 때문에 실제 동작하는 것이 아니다. 이를 사용하기 위해서는 JPA의 구현체인 ORM 프레임워크들 중 하나를 사용해야 하는데 그 중 가장 유명한 것이 Hibernate이다.
{4} 동작 방식
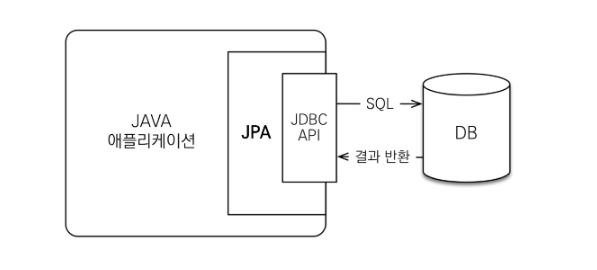
앞서 언급했지만 JPA(정확히는 JPA의 ORM 프레임워크)는 어플리케이션과 JDBC(Java DataBase Connectivity) 사이에서 동작한다. JPA 내부의 JDBC API를 사용해서 SQL을 호출하여 DB와 통신한다. 개발자가 ORM 프레임워크에 저장하면 적절한 INSERT SQL을 생성해서 데이터를 저장해주고, 검색을 하면 적절한 SELECT SQL을 생성해 결과를 객체에 매핑하고 전달해준다.
{5} 장점
(1) 생산성
JPA를 사용하면 자바 컬렉션에 데이터를 저장하듯이 JPA에게 저장할 객체를 전달하면 된다. SQL문과 OOP를 왔다갔다하며 지루한 코드를 작성하지 않아도 된다. RDB 중심에서 OOP 중심의 코드를 작성할 수 있게 되었다.
(2) 유지보수
이전에는 유지보수를 할 때 SQL문과 JDBC문 모두를 수정해야만 했지만 JPA가 이를 대신해 주기 때문에 수정할 코드가 줄었다.
(3) 패러다임 불일치 해결
OOP의 추상화, 캡슐화, 정보 은닉, 상속, 다형성 등의 철학과 RDB의 데이터 구조화의 철학이 불일치하는 현상을 해결해주었다.
