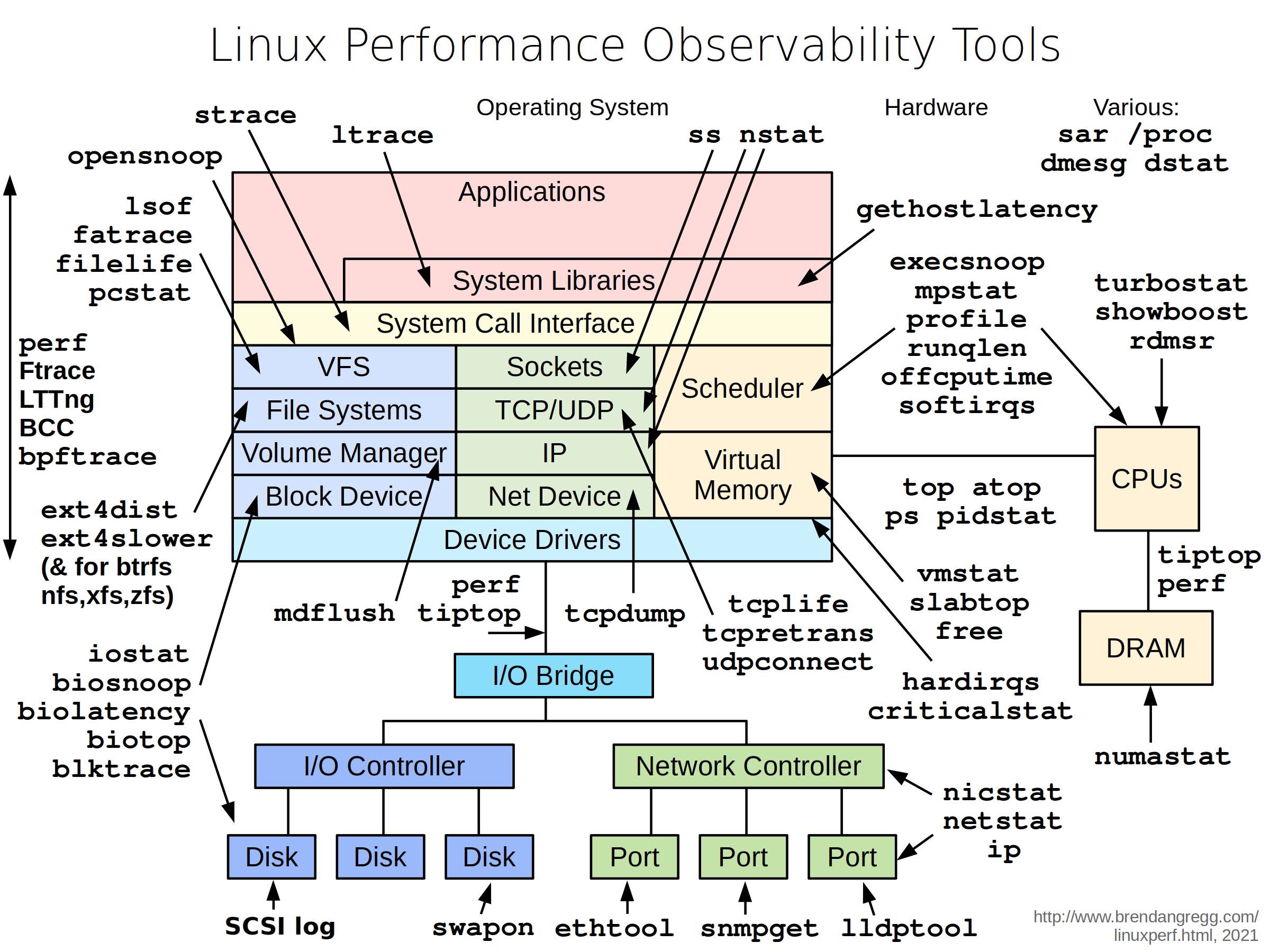
LiNUX 기본 성능분석 도구
리눅스 시스템에 대한 성능을 측청하는데 있어서, 별도의 sms 툴을 사용하는 것도 좋은 방법이되기도 하겠지만 Linux에서 제공해주는 명령어들만 가지고도 충분히 Linux Performance에 대한 이해를 높일수 있다.
전체 하드웨어의 동작을 이해하고, CPU부터 Memory 그리고 Disk I/O에 대한 항목들을 이해한다면, 생각보다 상세한 시스템 Linux 시스템 성능에 대한 자세한 Mesurement가 가능하리라 생각됩니다, 특히 툴이 제공하는 모니터링의 Obseravaility의 scope이 어디까지인지 이해하고 있다면 복잡하게 여겨졌던 보여졌던 관찰가능성에 대한 새롭게 이해도를 높일수 있다.
![[이미지 출처 : Brendan Gregg]](https://www.brendangregg.com/Perf/linux_observability_tools.png){kind=link}
[문서출처 : LinuxPerfTools]
Virtual Memory & Process 영역
vmstat 이해하기
-
Linux에서 vmstat 명령어는
프로세스,CPU의 동작상태,메모리, 페이징 블록에 대한 모니터링 정보와 함께 I/O의 트랩까지 상태정보를 통해서 Linux 자체에서 발생하는병목(Bottleneck)증상의 분석을 가능하게 해준다. -
vmstat의 명령어가 보여준 결과는 Linux가 재부팅이 되기전까지
누적된 데이타를 보여주지만CPU와 Memory 상태정보의 경우 즉각적으로 수집된 데이타를 보여준다.
Procs
r: The number of runnable processes (running or waiting for run time).
b: The number of processes blocked waiting for I/O to complete.
Memory
These are affected by the --unit option.
swpd: the amount of swap memory used.
free: the amount of idle memory.
buff: the amount of memory used as buffers.
cache: the amount of memory used as cache.
inact: the amount of inactive memory. (-a option)
active: the amount of active memory. (-a option)
Swap
These are affected by the --unit option.
si: Amount of memory swapped in from disk (/s).
so: Amount of memory swapped to disk (/s).
IO
bi: Blocks received from a block device (blocks/s).
bo: Blocks sent to a block device (blocks/s).
System
in: The number of interrupts per second, including the clock.
cs: The number of context switches per second.
CPU
These are percentages of total CPU time.
us: Time spent running non-kernel code. (user time, including nice time)
sy: Time spent running kernel code. (system time)
id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.-
vmstat 명령어에서:st값은 "steal time"으로 가상화 환경에서 CPU가 다른 가상 머신에 의해 사용되고 있는 시간의 비율을 나타낸다.st값이 갑작스럽게 증가한다면, 다음과 같은 성능 문제를 의심할 수 있다 -
CPU 자원 부족: 가상화 환경에서st값의 증가는 호스트 시스템의 CPU 자원이 부족하다는 신호일 수 있으며. 여러 가상 머신이 동일한 물리적 CPU를 공유할 때, 하나의 가상 머신이 다른 가상 머신의 CPU 자원을 침해할 수 있습다. -
과부하된 호스트: 호스트 머신이 너무 많은 가상 머신을 실행 중이거나, 특정 가상 머신이 과도한 CPU 자원을 소모하고 있을 때, 이로 인해st값이 증가할 수 있다. -
리소스 제어 문제: 가상화 관리 소프트웨어(예: VMware, Hyper-V, KVM)에서 자원 할당이나 제어 설정이 비효율적일 수 있다. 자원 할당이 적절하지 않거나 과도한 리소스 경합이 발생할 때st값이 증가할 수 있다. -
기타 시스템 병목: CPU 이외의 다른 자원(메모리, 디스크 I/O 등)이 병목 현상을 일으킬 경우에도st값에 영향을 줄 수 있다. 이 경우, 성능 문제는 다른 자원에서 발생하고 있지만 CPU 자원 경쟁으로 인해st값이 증가할 수 있다.
이러한 문제를 해결하기 위해서는 가상화 호스트의 리소스 사용 현황을 모니터링하고, 가상 머신의 CPU 할당을 조정하거나, 가상화 설정을 검토하여 자원 경합을 줄이는 것이 필요하다
vmstat 분석예제
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 13472 12176 55012 0 0 0 0 4 5 3 4 92 1 0
3 1 0 13472 12176 55012 0 0 0 0 6 8 4 5 86 4 1
4 0 0 13472 12176 55012 0 0 0 0 5 7 3 4 87 4 2-
st값이1%에서 2%로 증가한 경우, 이는 특정 시간 동안 CPU 자원이 다른 가상 머신에 의해 차단 되었음을 의미한다. -
출력 분석:
st값이 0%로 나타나는 경우: 현재 가상 머신의 CPU 자원이 다른 가상 머신에 의해 차단되지 않거나, 매우 적은 정도로 차단되고 있음을 의미한다.st값이 1% 또는 2%로 나타나는 경우: 가상 머신의 CPU 자원이 다른 가상 머신에 의해 일부 차단되고 있음을 나타내며. 이는가상화 호스트에서 자원 경쟁이 있음을 예상 할수 있다.
-
해석 및 조치:
st값이 5% 이상으로 높아지면, 호스트 시스템의 CPU 자원이 과부하 상태일 수 있으며, 가상 머신의 성능에 영향을 미칠 수 있다.- 이 경우, 호스트 시스템의 CPU 사용량을 확인하고, 가상 머신의 자원 할당을 조정하거나,
호스트의 CPU 자원을 증설하는 등의 조치를 고려해야 한다.
[참고 동영상 : Introduction to VMStat]
uptime 이해하기
uptime명령어는 Linux 시스템의가동 시간, 현재 시간, 시스템의 현재 사용자 수, 그리고 평균 부하(load average)를 표시하는 유용한 도구.- uptime 명령어는 시스템의 전반적인 상태를 간단하게 확인하는 데 사용되며, 특히 시스템의 부하와 안정성을 모니터링할 때 유용하다
$ uptime
10:17:11 up 7 days, 2:31, 3 users, load average: 0.34, 0.41, 0.39****uptime 각 필드의 의미
-
현재 시간 (10:17:11): 현재 시스템 시간이 표시.
-
시스템 가동 시간 (up 7 days, 2:31): 시스템이
재부팅된 후 가동된 총 시간을 나타낸다.
여기서 7 days는 시스템이 7일 동안 가동되었음을 의미하며, 2:31은 그 이후 추가된 시간(2시간 31분)을 의미한다. -
현재 사용자 수 (3 users): 현재 시스템에 로그인한 사용자 수를 표시한다.
-
평균 부하 (load average: 0.34, 0.41, 0.39): 시스템의 평균 부하를 나타내는 세 개의 숫자를 표시합니다. 이 숫자들은 각각 지난1분, 5분, 15분동안의 평균 부하를 의미합니다. -
평균 부하 (Load Average): 는 시스템의 실행 중이거나 실행을 기다리는 프로세스의 평균 수를 나타낸다. 이 값이 낮을수록 시스템이 한가하고, 높을수록 시스템이 바쁘다는 것을 의미합니다.예를 들어, CPU가 1개인 시스템에서는 평균 부하가 1.0이라면 CPU가 100% 사용 중임을 나타내고, 2.0이라면 CPU가 과부하 상태임을 나타냅니다. 여러 개의 CPU가 있는 시스템에서는 부하 값을 CPU 수로 나누어 생각할 수 있습니다.
uptime 분석 예제
$ uptime
15:23:45 up 365 days, 4:12, 2 users, load average: 0.15, 0.10, 0.08- 시스템 가동 시간 : 현재 시스템이
1년(365일)동안 재부팅 되지 않았음. - 시스템이 1년 이상 가동 됐을 경우
메모리나 기타 리소스의 누수 현상이 발생할 가능성 있음 - 커널패치 및 보안패치 등이 적용되지 않았을 가능성이 있음으로,
패치를 진행하는 것이 요구됨 - 시스템의 안정성을 위해서
정기적인 재부팅 계획을 시행함
Top 이해하기
top명령어는 Linux에서실시간으로 시스템의 프로세스와 성능을 모니터링할 수 있는 강력한 도구입니다.CPU 사용량, 메모리 사용량, 각 프로세스의 상태 등을 실시간으로 보여줌.
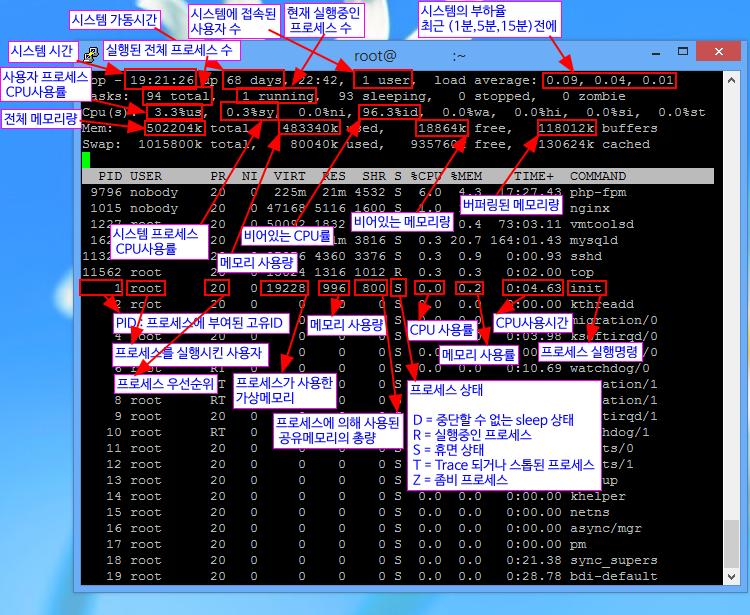
[이미지 출처 : 리눅스 서버 상태]
Process 정보
PID: 프로세스 ID를 표시USER: 프로세스를 실행 중인 사용자 이름PR: 프로세스의 우선순위(Priority)NI: 프로세스의 nice 값, 우선순위를 조정VIRT: 프로세스가 사용하는 가상 메모리의 총량RES: 프로세스가 사용하는 물리적 메모리의 양.SHR: 프로세스가 사용하는 공유 메모리의 양S: 프로세스의 상태를 표시다.
(R: 실행 중, S: 대기 중, D: 대기 중(중단 불가능), Z: 좀비 프로세스, T: 중단됨)%CPU: 프로세스가 사용하는 CPU의 비율.%MEM: 프로세스가 사용하는 메모리의 비율.TIME+: 프로세스가 시작된 이후의 총 CPU시간.COMMAND: 실행 중인 명령어의 이름.
프로세스 상태 코드
-
R (Running): 프로세스가 실제로 CPU에서 실행 중인 상태.
다중 CPU 시스템에서는 여러 프로세스가 동시에 실행될 수 있다. -
S (Sleeping):프로세스 대기 상태, 특정 이벤트(예: I/O 완료, 신호 수신 등)대기. 대개 짧은 시간 동안 지속되며, 이벤트가 발생하면 다시 실행 상태로 전환. -
D (Uninterruptible Sleep):프로세스 중단 불가능한 대기 상태에 있으며, 주로 디스크 I/O와 같은 작업을 수행할 때 발생. 이 상태에서는 프로세스가 신호를 받을 수 없으며. 예를 들어, 네트워크나 디스크에서 데이터를 읽는 동안 발생할수 있다. -
Z (Zombie):Child 프로세스가 종료되었지만, 아직 Parent 프로세스가 종료되지 않은 상태. 좀비 프로세스는 시스템 자원을 거의 사용하지 않지만, 부모 프로세스가 종료되거나 좀비 프로세스를 수거하지 않으면 시스템에 불필요한 PID를 차지하게 된다. -
T (Stopped): 프로세스 중단된 상태. 이 상태는SIGSTOP, SIGTSTP와 같은 신호로 프로세스가 중단되었을 때 발생한다. 디버깅 도구에 의해 프로세스가 추적되고 있을 때도 이 상태로 표시될 수 있다. -
t (Tracing stop): 프로세스가디버거에 의해 추적되고 있으며 중지된 상태. 주로ptrace시스템 호출에 의해 생성된다 -
I (Idle):프로세스가 현재 아무런 작업도 하지 않고 있는 상태. 일반적으로 유휴 상태는 시스템 리소스를 거의 사용하지 않는다. 이 상태는 일부 프로세스에서만 사용된다 (예: 커널 스레드). -
X (Dead): 프로세스가 더 이상 존재하지 않는 상태. 이 상태는 시스템에서 거의 볼 수 없으며, 특정 조건 하에서만 나타날 수 있다.
실시간 조정 옵션
k: 특정 프로세스를 종료합니다. (PID와 신호 번호 입력)r: 특정 프로세스의 nice 값을 변경합니다.f: 열 표시/숨김 메뉴를 엽니다.o: 정렬 기준을 변경합니다.l: load average와 uptime 정보 표시/숨김을 전환합니다.t: 요약 정보 표시/숨김을 전환합니다.m: 메모리 관련 정보 표시/숨김을 전환합니다.c: 명령어의 전체 경로 표시/숨김을 전환합니다.h: 도움말을 표시합니다.q: top 명령어를 종료합니다
[참고문서 : Top StackOverflow]
pidstat 이해하기
pidstat명령어는 Linux 시스템에서 실행 중인개별 프로세스에 대한 자세한 통계를 제공한다성능 모니터링: 과도한 CPU 또는 메모리를 사용하는 프로세스를 추적한다I/O 문제 해결: 높은 디스크 I/O를 발생시키는 프로세스를 식별하여 병목 현상 찾아낸다.시스템 최적화: 다양한 프로세스가 자원을 어떻게 사용하는지 이해하여 시스템 성능을 분석하고 최적한다
$ pidstat -u
08:10:09 UID PID %usr %system %guest %CPU CPU Command
08:10:09 0 1 0.00 0.00 0.00 0.00 0 systemd
08:10:09 0 2 0.00 0.00 0.00 0.00 0 kthreadd
08:10:09 0 3 0.00 0.00 0.00 0.00 0 rcu_gp
...pidstat 필드설명 I
Time (시간): 명령이 실행된 시간. hh:mm:ss 형식으로 표시된다.UID: 프로세스를 실행한 사용자의 사용자 ID.PID: 프로세스 ID입. 각 프로세스의 고유 식별자.%usr: 사용자 모드에서 소비된 CPU 시간의 백분율. 사용자가 실행한 프로그램이나 명령어가 CPU를 사용한 시간을 의미한다.%system: 커널 모드에서 소비된 CPU 시간의 백분율입.시스템 콜이나 커널 내부 작업이 CPU를 사용한 시간을 나타낸다.%guest: 가상 머신에서 실행되는 프로세스가 사용자 모드에서 소비한 CPU 시간의 백분율.%CPU: 해당 프로세스가 사용하는 총 CPU 사용량의 백분율. %usr와 %system의 합계로, 전체 CPU 시간에서 해당 프로세스가 얼마나 많은 CPU를 사용하고 있는지 보여준다.CPU: 프로세스가 실행되는 CPU 코어 번호. 멀티코어 시스템에서 프로세스가 어떤 코어에서 실행 중인지를 나타낸다.Command: 실행 중인 프로세스의 이름. 이 필드에는 프로세스를 시작한 명령어가 표시된다
pidstat 필드설명II
-
VSZ: 프로세스가 사용하는 가상 메모리의 크기(KB 단위).이는 프로세스가 차지하는 전체 메모리 공간을 포함한다. -
RSS: 프로세스가 실제로 사용하고 있는 물리적 메모리의 크기(KB 단위). 실제 메모리(RAM)에 상주하는 프로세스의 크기를 나타낸다. -
minflt/s: 프로세스가 초당 발생시킨 경미한 페이지 폴트의 수. 경미한 페이지 폴트는 메모리에서 직접 해결할 수 있는 페이지 폴트이다. -
majflt/s: 프로세스가 초당 발생시킨 중대한 페이지 폴트의 수. 중대한 페이지 폴트는 디스크에서 데이터를 가져와야 해결되는 페이지 폴트를 의미한다. -
kB_rd/s: 초당 프로세스가 읽은 데이터의 크기(KB 단위). -
kB_wr/s: 초당 프로세스가 쓴 데이터의 크기(KB 단위). -
kB_ccwr/s: 초당 프로세스가 강제적으로 동기화(write-back)된 캐시의 데이터 크기(KB 단위). -
cswch/s: 프로세스가 초당 발생시킨컨텍스트 스위치의 수. 컨텍스트 스위치는하나의 프로세스에서 다른 프로세스로 CPU 제어권을 전환하는 작업이다. -
nvcswch/s: 프로세스가 초당 발생시킨 비자발적(non-voluntary) 컨텍스트 스위치의 수.이는프로세스가 I/O나리소스 부족등으로 인해 강제로컨텍스트 스위치가 발생한 경우를 말한다. -
nivcswch/s: 프로세스가 초당 발생시킨 자발적(voluntary) 컨텍스트 스위치의 수입니다.프로세스가 스스로 CPU 사용을 중지하고 다른 프로세스로 전환된 경우를 말한다.
free 이해하기
- free 명령어는 메모리의 사용량을 나타내는 도구이다.
/proc/meminfo를 참조하여 메모리의 사용량 상태를 출력하게 된다.
total used free shared buff/cache available
Mem: 7985 1427 5143 98 1414 6196
Swap: 2047 0 2047free 필드설명
total: 전체 물리 메모리used: 사용 중인 메모리(used = total - free - buff/cache)free: 사용 가능한 메모리buff/cache: 버퍼 및 캐시 메모리available: 새로 시작된 프로세스에서 사용할 수 있는 메모리
메모리 사용량 확인 스크립트
#!/bin/bash
# 메모리 정보 가져오기
MEM_TOTAL=$(grep MemTotal /proc/meminfo | awk '{print $2}')
MEM_FREE=$(grep MemFree /proc/meminfo | awk '{print $2}')
BUFFERS=$(grep Buffers /proc/meminfo | awk '{print $2}')
CACHED=$(grep ^Cached /proc/meminfo | awk '{print $2}')
AVAILABLE=$(grep MemAvailable /proc/meminfo | awk '{print $2}')
# 값이 KB로 나오므로 MB로 변환
MEM_TOTAL_MB=$((MEM_TOTAL / 1024))
MEM_FREE_MB=$((MEM_FREE / 1024))
BUFFERS_MB=$((BUFFERS / 1024))
CACHED_MB=$((CACHED / 1024))
AVAILABLE_MB=$((AVAILABLE / 1024))
# 실제 사용량 계산 (Actual Used)
ACTUAL_USED_MB=$((MEM_TOTAL_MB - MEM_FREE_MB - BUFFERS_MB - CACHED_MB))
# 명목상 사용량 계산 (Nominal Used)
NOMINAL_USED_MB=$((MEM_TOTAL_MB - MEM_FREE_MB))
# 결과 출력
echo "Total Memory: ${MEM_TOTAL_MB} MB"
echo "Free Memory: ${MEM_FREE_MB} MB"
echo "Buffers: ${BUFFERS_MB} MB"
echo "Cached: ${CACHED_MB} MB"
echo "Available Memory: ${AVAILABLE_MB} MB"
echo ""
echo "Actual Memory Used: ${ACTUAL_USED_MB} MB"
echo "Nominal Memory Used: ${NOMINAL_USED_MB} MB"
slabtop 이해하기
slabtop 은 리눅스 시스템에서 커널의 슬랩 할당자(slab allocator) 상태를 실시간으로 모니터링할 수 있는 명령이다.커널이 메모리를 어떻게 사용하고 있는지, 특히 슬랩 캐시(slab cache) 가 어떻게 구성되어 있는지에 대한 중요한 정보를 제공한다.
Active / Total Objects (% used) : 204800 / 307200 (66.67%)
Active / Total Slabs (% used) : 3200 / 4800 (66.67%)
Active / Total Caches (% used) : 60 / 75 (80.00%)
Active / Total Size (% used) : 1024.00K / 1536.00K (66.67%)
Minimum / Average / Maximum Object : 0.02K / 0.03K / 0.10K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
102400 102400 100% 1.00K 1600 64 1024.00K kmalloc-1024
81920 40960 50% 4.00K 1280 32 5120.00K kmalloc-4096
30720 30720 100% 0.05K 480 64 240.00K buffer_head
20480 20480 100% 0.10K 320 64 320.00K dentry
10240 10240 100% 0.02K 160 64 80.00K inode_cacheslabtop 필드설명
-
Active / Total Objects (% used): 활성 상태의 객체 수와 전체 할당된 객체 수를 나타냅낸다. 괄호 안의 퍼센트는 활성 객체의 비율을 의미한다. -
Active / Total Slabs (% used): 활성 슬랩과 전체 슬랩의 비율을 보여준다.
슬랩은 객체를 할당하기 위한 메모리 블록이다. -
Active / Total Caches (% used): 활성 캐시와 전체 캐시의 비율을 나타낸다. -
Active / Total Size (% used): 활성 상태의 캐시가 사용하는 메모리 크기와 전체 캐시 메모리 크기를 나타낸다. -
Minimum / Average / Maximum Object: 객체의 최소, 평균, 최대 크기를 나타낸다.
Cache의 세부정보
OBJS: 해당 캐시에 할당된 전체 객체 수.ACTIVE: 현재 활성 상태의 객체 수.USE: 사용 중인 객체의 비율.OBJ SIZE: 객체 하나의 크기.SLABS: 할당된 슬랩의 수.OBJ/SLAB: 슬랩 하나당 할당된 객체 수.CACHE SIZE: 캐시가 차지하는 총 메모리 크기.NAME: 캐시의 이름 (예: kmalloc-1024, buffer_head, dentry).
slabtop 활용예시
-
메모리 사용 최적화: slabtop을 통해 비정상적으로 많은 메모리를 사용하는 슬랩 캐시를 식별할 수 있다. 예를 들어,kmalloc-4096이 매우 많은 메모리를 사용하고 있다면, 이와 관련된 코드나 커널 모듈을 점검하여 최적화할 수 있다. -
dentry와 buffer_head캐시 사용량이 지속적으로 증가하고, 메모리가 반환되지 않는다면메모리 누수가 발생하고 있을 가능성이 있다. 이는 주로 커널 모듈이나 드라이버에서 발생하는 버그로 인해, 메모리가 제대로 해제되지 않아서 발생한다.
mpstat 이해하기
mpstat 명령어는 시스템의 CPU 사용률을 모니터링하는 데 사용되는 Linux 유틸리티다. 이 명령어는 CPU 전체 및 각 개별 CPU(Core) 에 대한 상세한 사용률을 보여준다. 이를 통해 시스템의 CPU 자원이 얼마나 사용되고 있는지, 그리고 어느 부분에서 병목현상 이 발생하고 있는지 확인할 수 있다.
# mpstat -P ALL
Linux 4.15.0-60-generic (node09) 10/09/19 _x86_64_ (2 CPU)
13:00:37 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:00:37 all 8.45 0.04 2.07 24.08 0.00 0.07 0.00 0.00 0.00 65.29
13:00:37 0 8.47 0.03 2.07 24.25 0.00 0.12 0.00 0.00 0.00 65.06
13:00:37 1 8.42 0.04 2.08 23.92 0.00 0.03 0.00 0.00 0.00 65.51mpstat 필드설명
CPU: all은 전체 CPU에 대한 평균치를 나타내며, 각 번호는 개별 CPU 코어를 의미한다.%usr: 사용자 모드에서 CPU가 소비한 시간의 비율, 일반적인 응용 프로그램이 이 영역에 속한다%nice: 우선순위가 조정된 프로세스가 사용자 모드에서 소비한 시간 비율.%sys: 커널 모드에서 CPU가 소비한 시간의 비율. 시스템 호출 및 커널 작업이 이 영역에 속한다.%iowait: CPU가 대기 중인 시간 비율로, 주로 I/O 작업을 기다릴 때 발생한다.%irq: 하드웨어 인터럽트를 처리하는 데 소비된 시간의 비율.%soft: 소프트웨어 인터럽트를 처리하는 데 소비된 시간의 비율.%steal: 가상화 환경에서 CPU가 다른 가상 CPU를 기다리는 데 소비된 시간의 비율%guest: 가상 CPU가 실행하는 동안의 시간 비율.%gnice: 우선순위가 조정된 가상 CPU가 사용자 모드에서 소비한 시간 비율.%idle: CPU가 유휴 상태인 시간 비율.
ss 명령어 이해하기
ss 명령어는 기존의 netstat를 대체하는 명령어로 네트워크 소켓 정보를 빠르게 제공하는 역할을 하게 된다. ss는 socket statistics 의 약자로, Linux에서 TCP, UDP, RAW 소켓 및 UNIX 도메인 소켓과 같은 다양한 네트워크 상태를 확인할 수 있습니다.
ss 필드설명
ss -t: tcp 소켓에 대한 연결 정보를 표시.ss -u: udp 소켓에 대한 연결 정보를 표시.ss -l: Listen 하고 있는 모든 소켓에 대한 정보를 표시.ss -a: 모든 소켓 (Listen 하고 있는 소켓 포함)에 대한 정보를 표시.ss -n: 호스트 이름과 포트를 숫자 형태로 표시ss -p: 소켓에 연결된 프로세스를 표시ss -i: 네트워크 인터페이스의 통계 표시ss -s: 소켓의 요약 통계 표시ss state ESTABLISHED: 특정 소켓 상태를 필터링 (예: ESTABLISHED, LISTEN, CLOSED).ss -tulpn: 프로세스와 연결된 소켓 정보의 표시ss -r: Routing 테이블 정보 표시ss -tulpn | grep <포트번호>: 특정 포트로 연결된 프로세스 표시
ss 설치
RedHat 계열 리눅스 배포판.
sudo yum install iproute
Debian 계열 리눅스 배포판.
sudo yum install iproute
참고문서
