원본 논문
Flamingo: a Visual Language Model for Few-Shot Learning
Advances in neural information processing systems 2022
요약
Flamingo🦩라는 비주얼 언어 모델을 소개
이 모델은 주어진 소수의 예시로 새로운 작업을 빠르게 학습할 수 있는 능력을 갖추고 있으며, 텍스트와 이미지(비디오)를 결합하여 새로운 텍스트를 생성할 수 있도록 학습함. 이 모델은 다양한 벤치마크에서 탁월한 성과를 보였으며, 새로운 데이터 없이도 간단한 예시들로 높은 성능을 달성할 수 있다는 점이 주요 기여점
1. 도입부
현재 컴퓨터 비전에서 새로운 작업을 빠르게 배우는 것에 대한 연구가 잘 수행되고 있지만, 대부분의 방법들은 여전히 대규모 데이터를 사용해 사전 학습한 후, 관심 있는 작업에 맞게 모델을 미세 조정하는 방식에 의존하고 있음. 그러나 성공적인 미세 조정을 위해서는 수천 개의 주석이 달린 데이터 포인트가 필요하며, 작업별 하이퍼파라미터 조정이 필요할 뿐만 아니라 자원이 많이 소모됨.
최근에는 대조적 목적(contrastive objective) 방법을 사용하여 학습된 다중 모달 비전-언어 모델이 미세 조정 없이도 새로운 작업에 제로샷 적응을 가능하게 함. 하지만 이러한 모델은 텍스트와 이미지 간 유사성 점수만을 제공할 수 있어 분류와 같은 제한된 사용 사례에만 적용될 수 있는 한계가 있음.
이들은 언어 생성 능력이 부족하여 캡셔닝이나 비주얼 질문 응답과 같은 작업에는 적합하지 않음. 이를 극복하기 위해 시각적인 내용에 대한 언어 생성에 대한 탐구도 이루어졌지만, 아직 좋은 성능을 보여주지 못하고 있음.
본 논문은 이러한 한계를 극복하고, 다양한 비전 및 언어 작업에서 소수의 예시만으로 학습할 수 있는 비주얼 언어 모델인 Flamingo를 소개함. 이 모델은 몇 가지 입력/출력 예시만으로 다양한 작업에 적용될 수 있으며, 미세 조정 없이도 여러 작업에서 새로운 성능을 보여줌.
Flamingo 결과 예시
(무슨 동물에 대한 대답)

(동물 수에 대한 대답)

(영상 내용 설명)

2. 상세설명
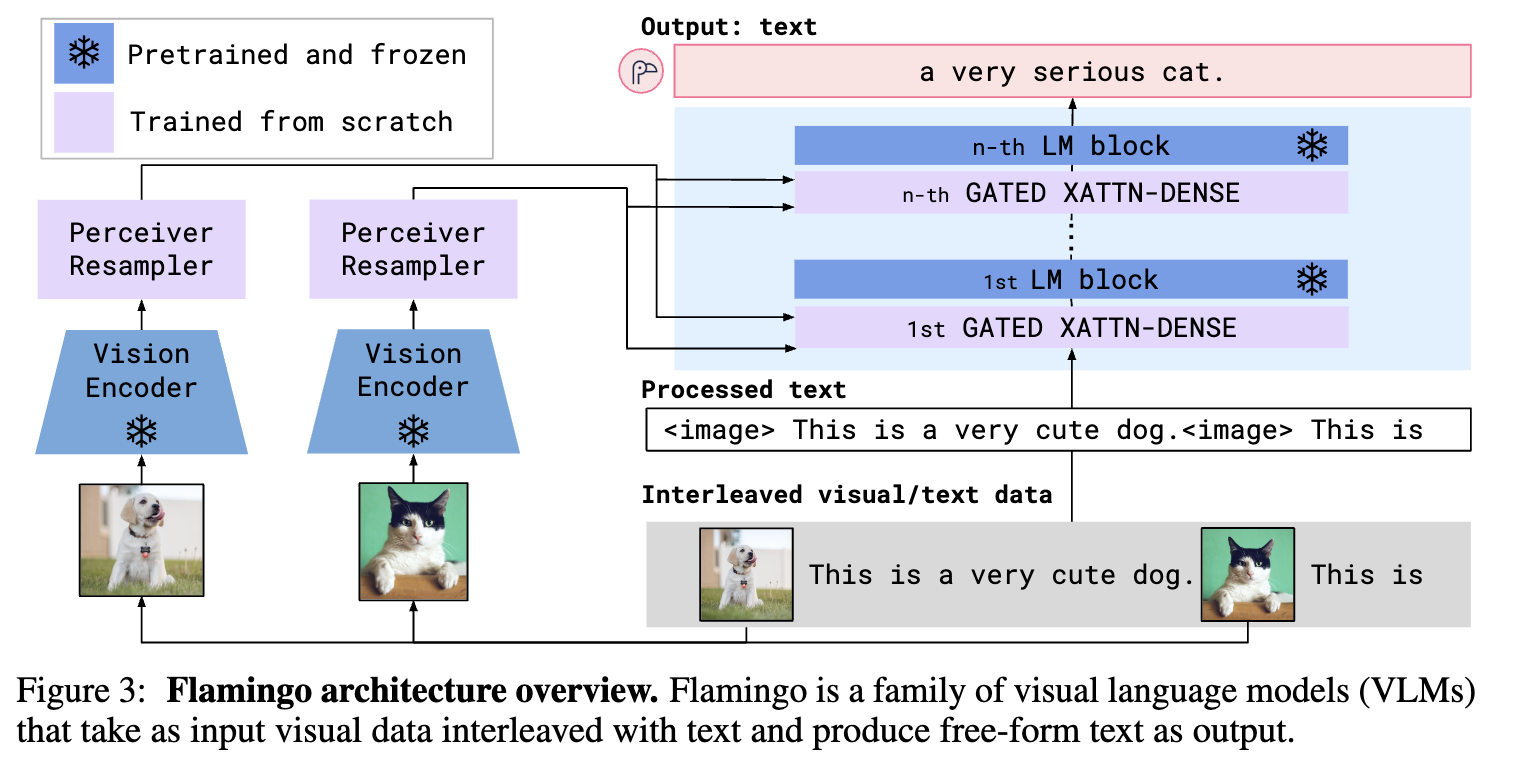
Flamingo는 위 그림과 같이 Vision encoder, Language model(LM) block로 나뉘며, Perceiver Resampler(연보라색), Gated XATTN-Dense가 있는 것이 특징
Vision encoder : CLIP text-image contrastive learning으로 학습된 비전 인코더를 불러와 사용함
Language model : Large text corpus로 학습된 Chinchilla를 사전학습 불러와 사용함
Perceiver Resampler : 비전 인코더의 출력을 고정된 크기로 mapping하는 역할(고정 크기만큼 작아져서 계산 효율적)
Gated XATTN-Dense : Query, Key, Value를 입력 받아 해당 정보가 가미된 벡터를 출력하는 레이어
다음으로 Perceiver Resampler와 Gated XATTN-Dense에 대해서 설명
Perceiver Resampler
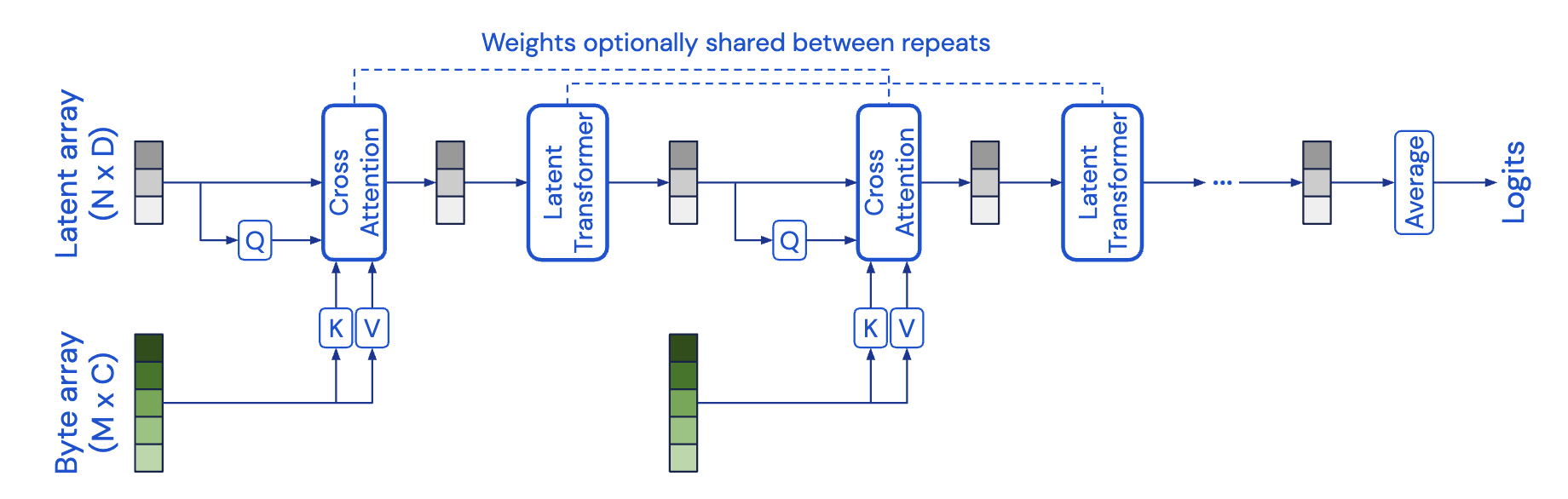
우선 Perceiver Resampler는 본 논문(2022)에서 새롭게 제안한 건 아니고 2021년 Perceiver: General Perception with Iterative Attention에서 제안됨. 본 논문은 Cross Attention에 입력하기 위한 리샘플링 방법을 사용한 것이라 보면 됨.
우선 설명 전에, Flamingo 모델에서는 우선 Vision Feature와 Text Feature를 같이 연산해주어 한다는 걸 생각해보자.
이때 Vision Feature는 Text Feature보다 일반적으로 훨씬 큰 차원을 갖기 때문에 이 둘을 동시에 연산하기 위해서는 Vision Feature의 차원을 Text Feature에 맞게 축소해줄 필요가 있음. (안 그럼 벡터의 차원도 안 맞고 연산 자체가 불가능하다)
위 그림에서는 아래쪽에서 고차원 벡터에 해당하는 Vision Feature를 초록색 계열로 표현하고 있는데, 이제 이 Vision Feature를 저차원으로 축소해야 함. (이때의 타겟 벡터(Latent)를 회색으로 표현)
Query로 들어가는 저차원 벡터는 Learned Latent Vector(그림의 위치정보를 신경망에 입력해서 나온 벡터)를 사용함. 이렇게 Learned Latent Vector는 Query로, Vision Feature를 Key, Value로 하여 Cross Attention을 수행
Gated XATTN-Dense
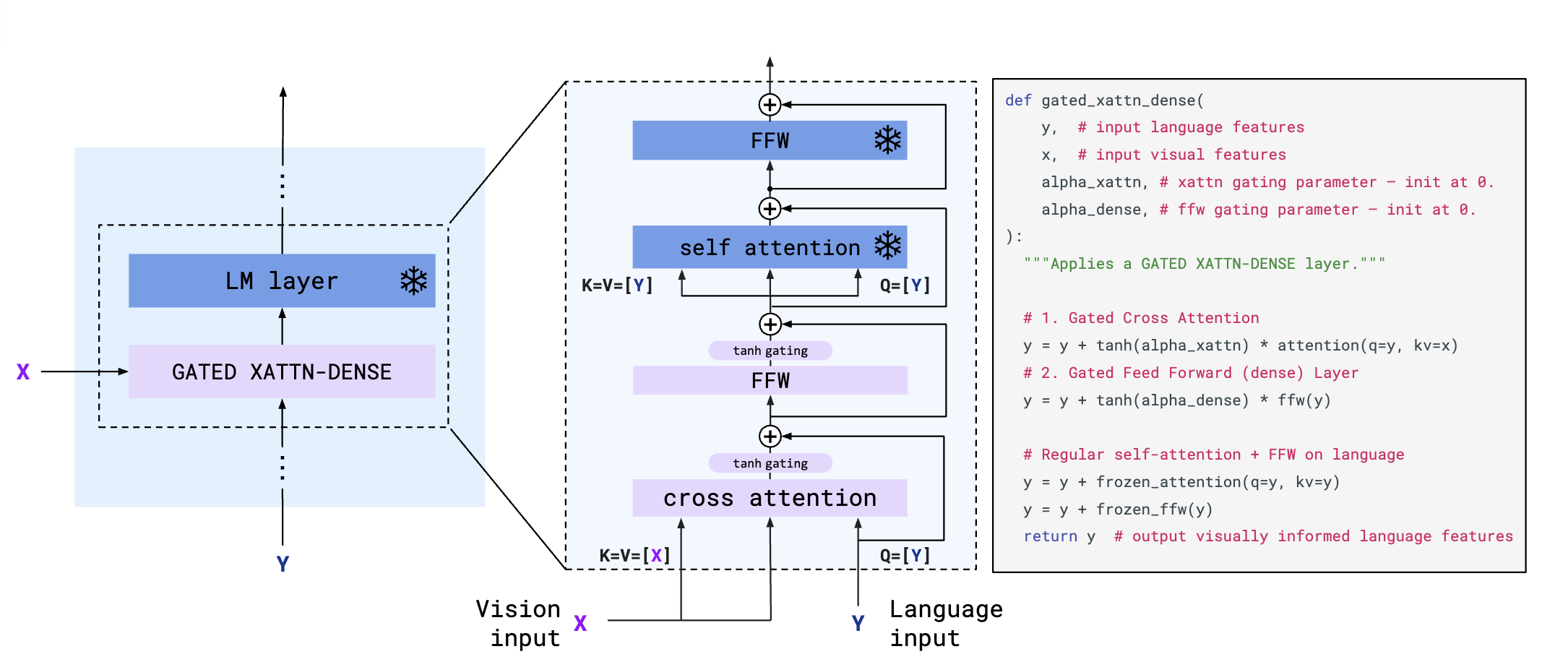
Gated XATTN-Dense는 앞서 Vision 정보와 Language 정보를 융합(Cross Attention)하여 Language가 가미된 비전 벡터를 얻는다고 생각하면 편함. 여기서 입력으로 요구되는 Query, Key, Value를 정해야한다. 본 모델은 비주얼-언어 모델이므로 최종 출력은 텍스트임. 따라서 Query 로는 Text Feature, 정보를 추가할 Key, Value로는 Vision Feature를 사용
본 논문에 사용하는 연산 순서는 위 그림을 통해 확인할 수 있음. 설명하자면 먼저 visual feature(x)에 대해 Cross Attention(q=y(language), kv=x) 연산 뒤에 feed forward(FFW) 레이어를 통해 weight와 bias를 (wx+b)계산하고, 이후 그 값(y)에 다시 self attenction(q=y, kv=y)를 연산, FFW 레이어를 거쳐 최종 y를 출력함
3. 실험 결과
본 논문에서 사용된 데이터 셋은 아래와 같음
- M3W (MultiModal MassiveWeb): 이 데이터셋은 4,300만 개의 웹페이지에서 수집된 이미지와 텍스트 데이터로 구성되어 있으며, 각 웹페이지에서 이미지와 텍스트의 위치 관계를 기반으로 시각 데이터를 추출
- ALIGN: 18억 개의 이미지와 대체 텍스트(alt-text) 쌍으로 구성된 데이터셋
- LTIP (Long Text & Image Pairs): 3억 1,200만 개의 이미지와 긴 설명 텍스트 쌍으로 구성된 데이터셋
- VTP (Video & Text Pairs): 평균 22초 길이의 2,700만 개의 짧은 비디오와 해당 비디오에 대한 문장 설명으로 구성된 데이터셋
이후 아래 두 조건으로 실험 진행
1. Few-shot learning on vision-language tasks
본 논문은 Few Shot Learning에 대한 결과를 위해 총 16개의 벤치마크를 사용하여 성능을 측정. 각 문제별(벤치마크)마다 모델을 Fine Tuning 하지 않고 단지 사전 학습을 완료한 Flamingo에게 몇 가지 예시를 제공하고 해결하도록 함
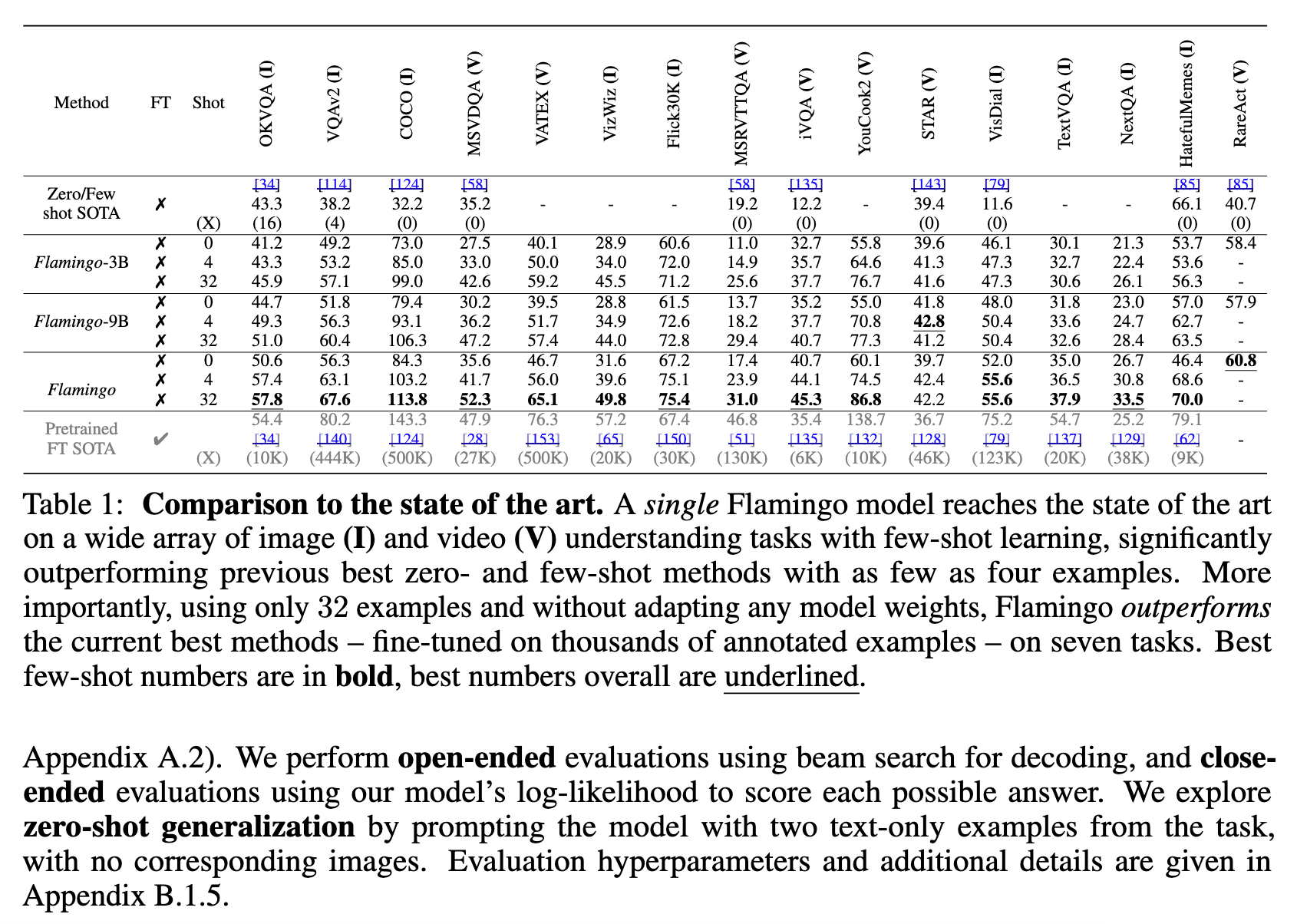
실험 결과 기존 SOTA 모델들 대비 성능이 거의 모두 좋았다고 함.
2. Fine-tuning Flamingo as a pretrained vision-language model
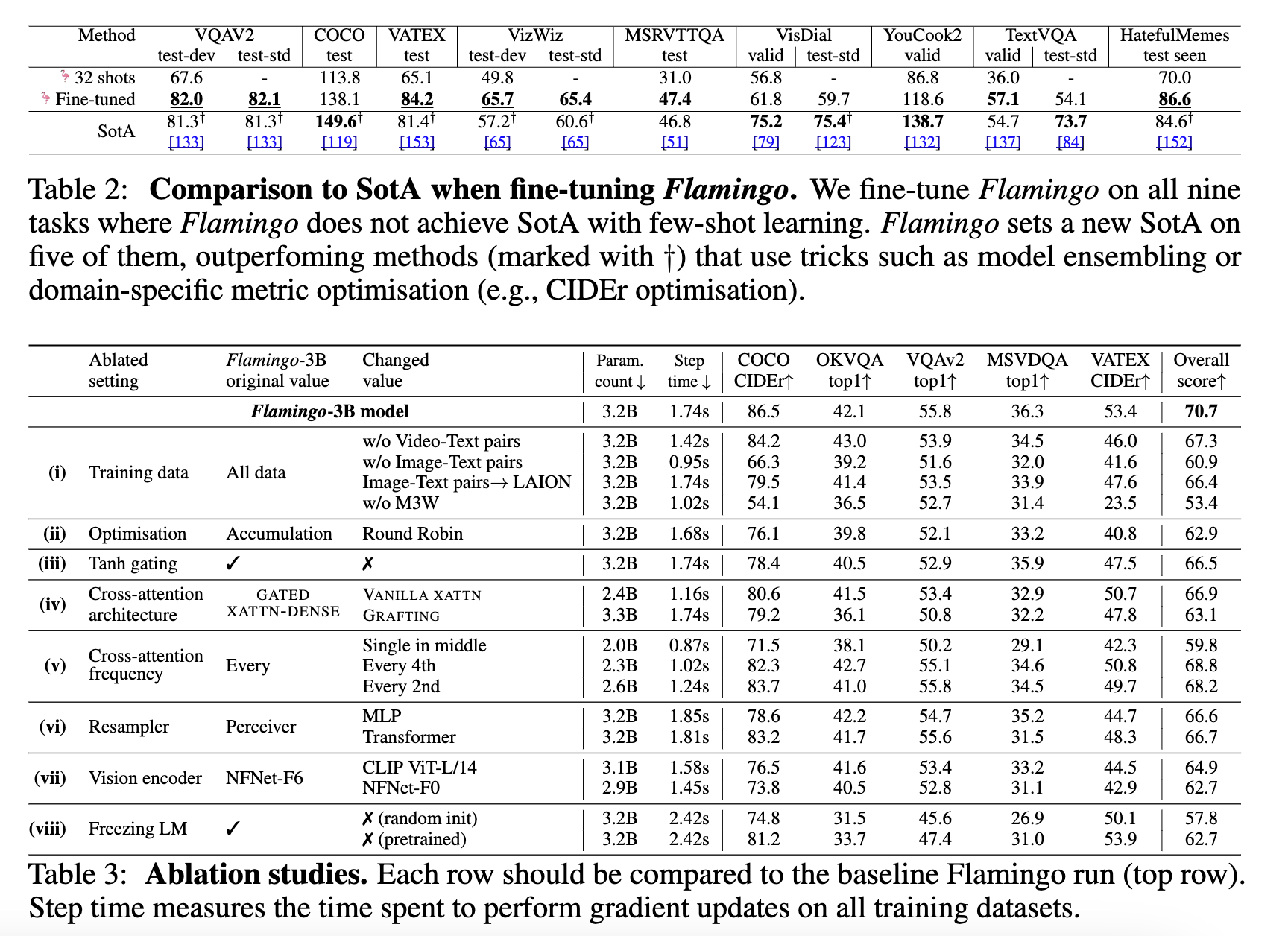
이번에는 문제들에 대해 추가 학습을 하여(Fine-tune) 성능을 산출한 결과, 대다수의 결과에서 좋은 성능을 보임
4. 결론
이 논문의 결론에서 저자들은 Flamingo 모델을 제안하며, 이미지 및 비디오 작업에 최소한의 작업별 훈련 데이터만으로 적용 가능한 범용 모델이라고 설명함.
Flamingo는 전통적인 비전 벤치마크를 넘어 대화와 같은 상호작용 기능을 보여주며, 다양한 시각적 작업에서 강력한 성능을 발휘하였고, 또한, 사전 학습된 대형 언어 모델과 강력한 비전 모델을 연결하는 것이 범용 시각 이해로 나아가는 중요한 단계임을 강조함.
사용방법
github를 참고하여 설치 및 활용할 수 있음.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
from PIL import Image
import requests
import torch
checkpoint_path = hf_hub_download("openflamingo/OpenFlamingo-3B-vitl-mpt1b", "checkpoint.pt")
model.load_state_dict(torch.load(checkpoint_path), strict=False)
"""
Step 1: Load images
"""
demo_image_one = Image.open(
requests.get(
"http://images.cocodataset.org/val2017/000000039769.jpg", stream=True
).raw
)
demo_image_two = Image.open(
requests.get(
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg",
stream=True
).raw
)
query_image = Image.open(
requests.get(
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg",
stream=True
).raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [image_processor(demo_image_one).unsqueeze(0), image_processor(demo_image_two).unsqueeze(0), image_processor(query_image).unsqueeze(0)]
vision_x = torch.cat(vision_x, dim=0)
vision_x = vision_x.unsqueeze(1).unsqueeze(0)
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer.padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer(
["<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of"],
return_tensors="pt",
)
"""
Step 4: Generate text
"""
generated_text = model.generate(
vision_x=vision_x,
lang_x=lang_x["input_ids"],
attention_mask=lang_x["attention_mask"],
max_new_tokens=20,
num_beams=3,
)
print("Generated text: ", tokenizer.decode(generated_text[0]))