개요 (회사에서 배운 것 정리하기)
쿼리문이 비정상적으로 오래걸려서 왜이리 쿼리가 오래 걸리는지 파악 하는 와중에 팀장님이 실행계획을 보라고 말씀해주셨고 옵티마이저로 실행계획을 확인했다. 확인 결과 join을 하는 view에 index가 존재하지 않음을 확인 할 수 있었다. 그래서 index와 옵티마이저를 정리할 건데 일단 옵티마이저 부터 정리해보자!
옵티마이저란?
옵티마이저는 SQL을 가장 빠르고 효울적으로 수행할 최적의 처리경로를 생성해주는 DBMS의 핵심엔진이다.
인간은 생각하기 위해 두뇌를 가지고 있고 컴퓨터는 cpu를 가지고 있으며 dbms는 옵티마이저를 가지고 있다!
가장 효율적인 방법을 찾는 일을 하는 것이 옵티마이저의 역활이다.
그럼 효율적인 방법을 옵티마이저는 어떻게 찾을까?
크게 두 가지 방법으로 찾는데 규칙기반, 비용기반 최적화이다.
| 항목 | 규칙 기반 옵티마이저 | 비용 기반 옵티마이저 |
|---|---|---|
| 개념 | 사전에 정의된 규칙 기반 | 최소비용 계산 실행계획 수립 |
| 기준 | 실행우선 순위(Ranking) | 액세스 비용(Cost) |
| 인덱스 | 인덱스 존재 시 가장 우선시 사용 | Cost에 의한 결정 |
| 성능 | 사용자 SQL작성 숙련도 | 옵티마이저 예측 성능 |
| 장점 | 판단이 매우 규칙적 실행 예상 가능 | 통계 정보를 통한 현실 요소 적용 |
| 단점 | 예측 통계정보 요소 무시 | 최소 성능 보장 계획의 예측 제어 어려움 |
| 사례 | AND 중심 양쪽 ‘=’ 시 Index Merge 사용 | AND 중심 양쪽 ‘=’ 시 분포도별 Index 선택 |
규칙기반 (Rule-Based Optimization, RBO )
RBO는 실행계획을 결정할 때 미리 결정해 놓은 계획대로 실행하는 방법이다.
RBO의 정의를 읽어보면 옵티마이저는 미리 결정해 놓은 계획이 있는 거 같다. RBO는 어떤 계획들을 가지고 어떤 우선순위를 가지고 있을까?
RBO는 실행 속도가 빠른순으로 규칙을 세워두고 우선 순위가 높은 방법을 채택하는 옵티마이저이다. 우선 순위는 15가지이고 아래와 같다.
| 순위 | 설명 |
|---|---|
| 1 | ROWID를 사용한 단일 행인 경우 |
| 2 | 클러스터 조인에 의한 단일 행인 경우 |
| 3 | 유일하거나 기본키(Primary Key)를 가진 해시 클러스터 키에 의한 단일 행인 경우 |
| 4 | 유일하거나 기본키(Primary Key)에 의한 단일 행인 경우 |
| 5 | 클러스터 조인인 경우 |
| 6 | 해시 클러스터 조인인 경우 |
| 7 | 인덱스 클러스터 키인 경우 |
| 8 | 복합 칼럼 인덱스인 경우 |
| 9 | 단일 칼럼 인덱스인 경우 |
| 10 | 인덱스가 구성된 칼럼에서 제한된 범위를 검색하는 경우 |
| 11 | 인덱스가 구성된 칼럼에서 무제한 범위를 검색하는 경우 |
| 12 | 정렬-병합(Sort-Merge) 조인인 경우 |
| 13 | 인덱스가 구성된 칼럼에서 MAX 혹은 MIN을 구하는 경우 |
| 14 | 인덱스가 구성된 칼럼에서 ORDER BY를 실행하는 경우 |
| 15 | 전체 테이블을 스캔(FULL TABLE SCAN)하는 경우 |
비용기반 (Cost-Based Optimization, CBO)
CBO는 쿼리를 수행하는 양 또는 시간을 기반으로 최적화하는 방식이다.
- 최근에 많이 사용하고 있는 옵티마이저 방식
- 오라클 10g 이후 공식적으로 비용 기반 옵티마이저만을 사용
- 실행 계획을 세운 뒤 ( 최대 2000 개) 비용이 최소한으로 나온 시행 계획을 수행한다.
- 규칙 기반 옵티마이저와 다르게 테이블, 인덱스, 컬럼 등의 다양한 객체 통계정보와 시스템 통계정보를 사용
- 통계 정보가 없는 경우 비효율적인 계획 생성 가능, 정확한 통계정보 유지 중요
CBO의 모드
비용기반 옵티마이저에는 여러 모드가 존재합니다. 모드에 따라서 비용을 구하는 방식들이 달라집니다.
CHOOSE
- 현재 잘 사용하지 않음
- 통계 정보를 가져올 수 있으면 CBO로 아니면 RBO로 작동
FIRST_ROWS
- 첫 건을 출력하는데 걸리는 시간 최소화
FIRST_ROWS_n
- SQL 실행 결과 출력 응답속도 최적화
ALL_ROWS
- SQL 실행 결과 전체를 빠르게 처리에 최적화
- 마지막으로 출력될 행까지 최소한의 자원 사용이 목적
- 오라클 10g 이후로는 이 모드가 기본값
옵티마이저 동작방식
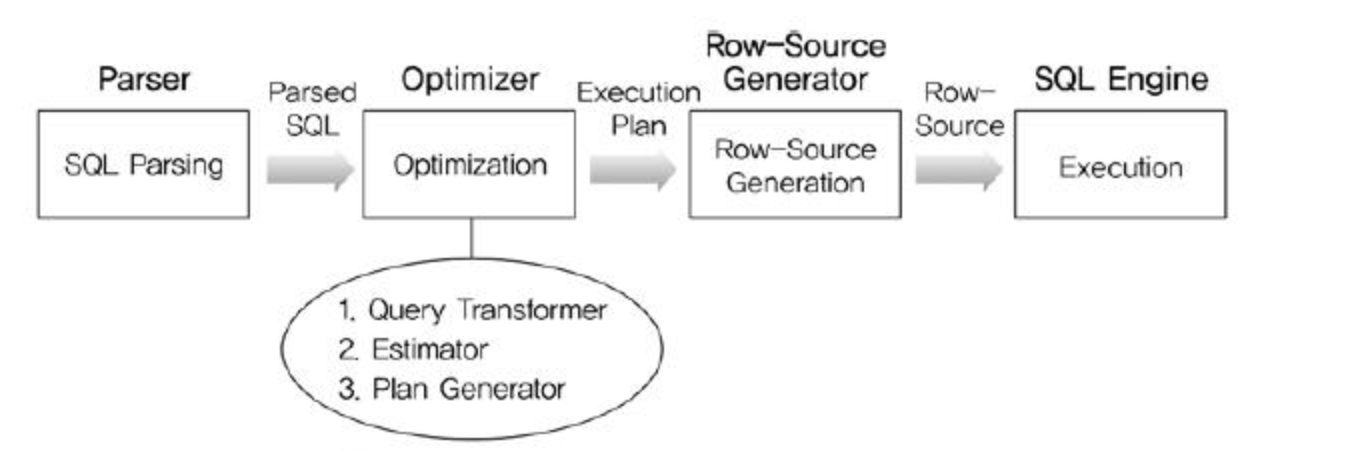
parser
- SQL 문장 분석 (문법 검사, 구성요소 파악)
- 파싱해서 파싱 트리 만듬
Query Transformer
- 파싱된 SQL을 보고 같은 결과 도출
- 좀 더 나은 실행 계획을 갖는 SQL로 변환 가능여부 판단
Estimator
- 시스템 통계정보 수집 실행시 소요되는 총비용 계산
Plan Generator
- Estimator를 통해 계산된 값을 토대로 후보군이 되는 실행계획 도출
Row-Source Generator
- 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행하는 코드나 프로시저 형태로 포맷팅
SQL Engine
- SQL을 실행한다.
옵티마이저에 영향을 끼치는 정보
SQL과 연산자 형태
- SQL을 어떤 형태로 작성 or 어떤 연산자를 사용했는지에 따라 옵티마이저의 선택이 변경될 수 있음
옵티마이징 팩터
- 인덱스, IOT, 클러스터링, 파티셔닝 구성에 따라 실행계획 및 성능이 달라진다.
DBMS 제약 설정
- 개체 무결성, 참조 무결성, 도메인 무결성 등을 위해 DBMS가 제공하는 (PK, FK, Check, Not Null) 제약 조건을 이용할 수 있다.
- 제약 조건은 옵티마이저가 쿼리 성능을 최적화하에 매우 중요한 정보 제공
옵티마이저 힌트
- 옵티마이저의 판단보다 사용자가 지정한 옵티마이저 힌트가 우선한다.
통계 정보
- 통계정보가 옵티마이저에게 미치는 영향력은 절대적이다. CBO의 모든 판단 기준은 통계정보에서 나온다.
주요 통계 정보
| 구분 | 세부 통계 정보 |
| 테이블 | 테이블의 전체 행의 갯수 |
| 테이블이 차지하고 있는 전체 블록 갯수 | |
| 테이블의 행들이 가지고 있는 평균 길이 | |
| 컬럼 | 컬럼 값의 종류 |
| 컬럼 내부 NULL 값의 분포도 | |
| 컬럼 값의 평균 길이 | |
| 컬럼 내부 데이터 분포의 추정치 | |
| index | LEAF BLOCK 수 : 데이터를 보관하는 블록 수 |
| LEVELS : 인덱스 트리의 LEVEL 정보 | |
| CLUSTERING FACTOR : 접근하고자 하는 데이터가 모여 있는 밀집도 | |
| 시스템통계 정보 | I/O 성능 및 사용률 |
| CPU 성능 및 사용률 |
옵티마이저 관련 파라미터 와 종류
- 모든 환경(SQL, 데이터, 통계정보, 하드웨어 등)이 동일 DBMS 버전을 업그레이드하면 파라미터 추가 또는 변경으로 옵티마이저가 다르게 작동할 수 있다.
- DBMS 종류가 다른 경우 옵티마이저가 다르게 작동할 수 있다.
옵티마이저의 한계
- 옵티마이저는 만능이 아니다.
- 컬럼의 통계 정보로는 조건절에서 사용되는 조건을 만족하는 데이터의 양이 어느정도 인지 알 수 없기에 비용계산 결과가 정확하지 않음.
- 비용산정시 쿼리문 단독으로 실행된다고 가정하기엔 운영 서버와 같이 쿼리가 동시 실행된다면 실제 비용은 달라질 수 있다.
- 히스토리 버킷이 최대 254개 까지만 사용할 수 있어, 254개 이상의 값을 갖는 컬럼의 경우 비용 예측 결과가 정확하지 않는 등의 문제가 있음
- 쿼리 튜닝시 쿼리 문의 실행계획을 꼭 봐야함
- 옵티마이저가 비효율적으로 작동하고 있다면 오라클의 힌트 같은 부가적인 장치를 통해 올바르게 작동될 수 있도록 유도 해야함
참고

하루 한 걸음 성장하는 개발자