빅데이터란?
- Big + data (큰) + 데이터
- 빅데이터를 어떻게 하면 학문적으로 정의 할 수 있을까?
- 스스로 정의 해보자!
0. Ex. 빅데이터 특징
- 3V: Volume(규모), Variery(다양성), Velocity(속도)
- 5V: 3v + Veracity(진실성), Value(가치)
- 7V: Validity(정확성), Volarllity(휘발성)
왜 5v가 되고 7v 가 됫을까에 대한 이유를 생각해보자 - 빅데이터의 목적은 가치 창출에 있다.(예측도 가치 창출을 위해 존재한다.)
- volume : 병렬 저장, 장애 허용 시스템 (장애가 나도 정상 적으로 돌아간다.)
- variety: 정형, 반정형, 비정형 의 특성을 다 가지고 있어야한다.
- velocity : 병렬 처리/ 분석
ETL VS ELT
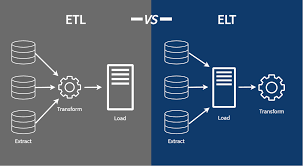
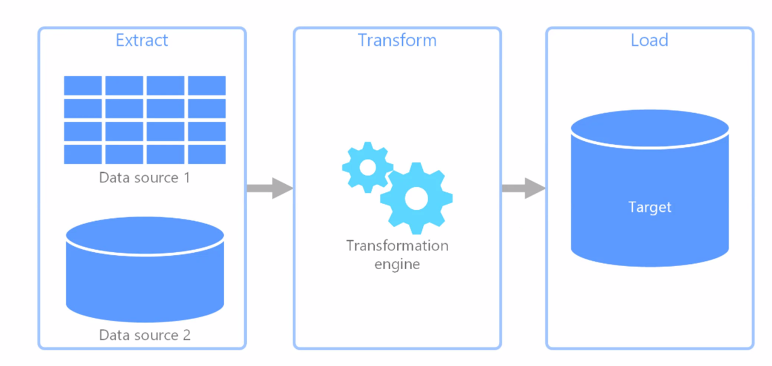
- Extract Transform Load : 정형 데이터를 저장하기 위한 툴이다.
- Extract Load Transform : 일단 저장한 후에 필요하면 수정해서 사용하자!
스키마란?
1. 빅데이터 연산처리 패러다임
Hadoop
- HDFS : 데이터를 저장
- MapReduce : 데이터를 처리한다.
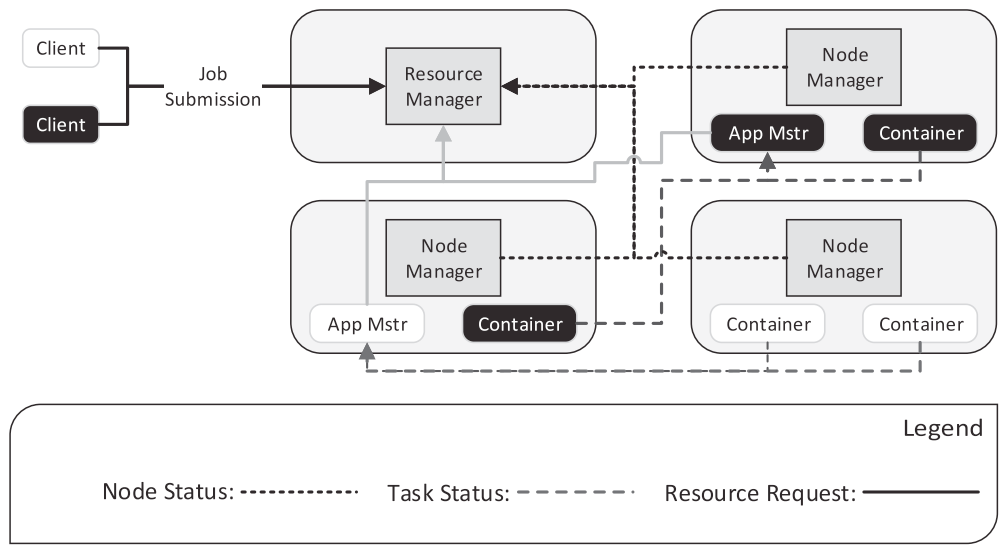
- yarn : job의 리소스 관리 및 스케줄 관리
MapReduce
Input -> input splits -> mapping -> shuffling -> reducer -> final output
Yarn (Yet Another Resource Negotiator)
2. MapReduce의 대체자, Spark
- 하둡과 스파크의 차이
- HADOOP : DISK I/O , 느리다
- SPARK : IN-MEMORY, 빠르다

| Spark | |
|---|---|
| 장점 | 단점 |
| 데이터 전처리 집계 | 단독사용보다 다른 기술과 결합시 좋은 효과가 나타남 |
| 스트리밍 데이터 처리, 배치 프로세싱 | DB를 대체 할 수 없음, 인덱스가 없어서 성능 x |
| 머신러닝 분석 | |
| 응답성이 좋고 Interactive한 연산에 유용 | 메모리뿐만 아니라 Cpu/Gpu 스팩도 중요 |

하루 한 걸음 성장하는 개발자