Continuous Pre-Training (CPT)
- output format, knowledge, and reliability 관점에서 파인튜닝된 LLM에 CPT의 영향 비교
https://arxiv.org/pdf/2401.03129
Straightforward Approaches
- Freeze layers
- Freeze modules
- Adapter
- LoRA
- IA3: element-wise multiplication of the model’s activations with a learned vector.
: rescale the key and value matrices in self-attention modules and the inner activations in feed-forward modules in each model layer
https://www.arxiv.org/pdf/2410.10739
https://arxiv.org/pdf/2408.14471
A Practitioner’s Guide to Continual Multimodal Pretraining
3.3 Designing Data-Centric Task-Sequences
FoMo-in-Flux 벤치마크의 데이터 작업 설계로 다양한 데이터셋 구성 방식을 통해 지속적 학습 중 발생할 수 있는 다양한 데이터 순서 연구
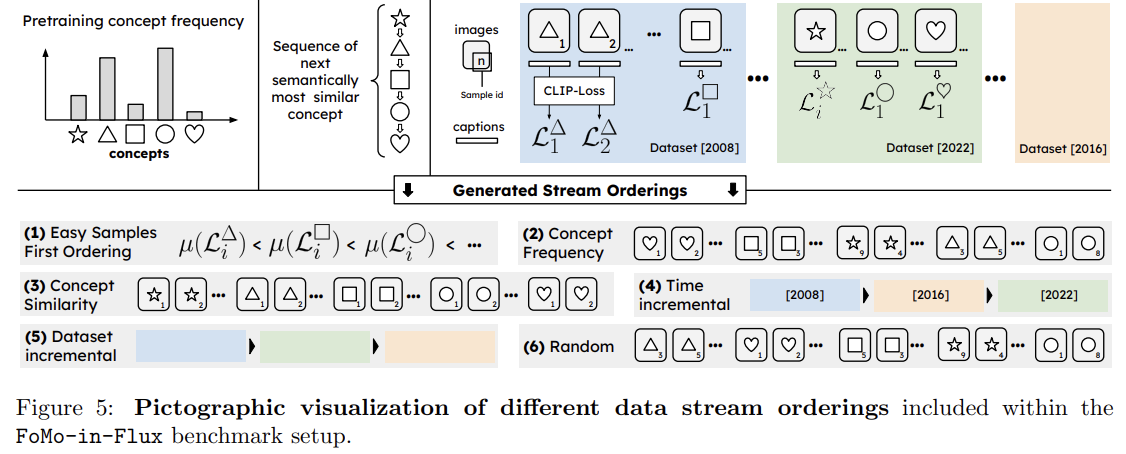
1. Easy-To-Hard Ordering: 학습이 쉬운 개념에서 어려운 개념으로 순차적으로 이동하도록 배치하여 성능이 점진적으로 향상됩니다. 기본 모델 성능(예: 대조 손실)을 기준으로 개념을 분류하여 순서를 정합니다.
2. Concept Frequency Ordering: 자주 등장하지 않는(길게 늘어진 꼬리 부분) 개념에서부터 자주 등장하는 개념 순으로 배치하여 드물게 발생하는 엣지 케이스부터 모델 개선을 시작합니다.
3. Concept Similarity Ordering: 개념 간의 유사성에 따라 유사한 개념을 연속적으로 학습하도록 배치하여 연관 개념 간의 잊힘을 줄입니다. 클래스 간의 유사도를 그래프화하고 최소 스패닝 경로를 구해 유사도가 높은 순서대로 배치합니다.
4. Time-incremental Ordering: 데이터셋의 연도를 기준으로 오래된 데이터부터 최신 데이터 순서로 배치하여, 더 오래된 데이터가 먼저 통합되도록 유도합니다.
5. Dataset-Incremental Ordering: 여러 데이터셋을 단계적으로 순차적으로 샘플링하여 순서를 만듭니다.
6. Random Ordering: 지속적 학습 설정에서 자주 사용되는 무작위 순서를 적용하여 비구조화된 사용자 요청을 모방합니다.
3.4 Verifying Downstream Datasets: Finetuning must improve Performance
생성된 캡션의 품질을 확인하고, 학습 파이프라인의 유효성을 점검하기 위해 각 데이터셋에 대해 CLIP-ViT-B/32 및 CLIP-ViT-B/16 모델을 10 에포크 동안 파인튜닝했습니다. 결과적으로, 초기 제로샷 성능이 일관되게 향상되었으며, 이는 FoMo-in-Flux 벤치마크에서 사용된 데이터셋과 생성된 캡션의 유효성을 뒷받침합니다.
5 Continual Pretraining: A Method Perspective
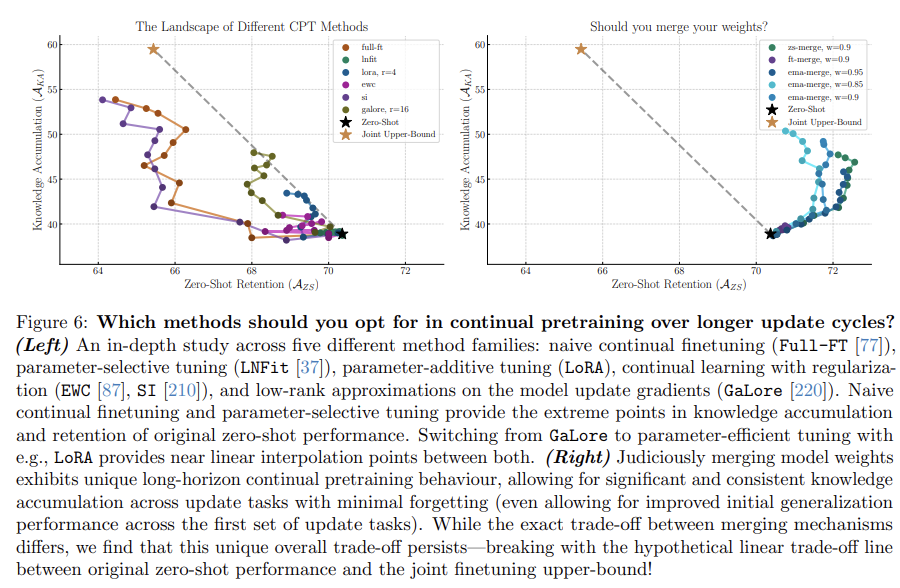
Model Merging으로 하는 간단한 continual finetuning이 긴 업데이트 싸이클에서 가장 효과적이다.
1. Model Merging 기법은 continual pretraining에서 유망한 동적 패턴을 보입니다. 짧은 학습 기간동안 base 일반화 성능이 향상되며, full continual pretraining sequence에서는 knowledge retention가 우수합니다. 또한, 지식 축적 면에서도 parameter-efficient tuning이나 full finetuning을 뛰어넘는 성과를 보입니다.
-
Parameter-efficient tuning 기법(LoRA, DoRA, VeRA)은 knowledge retention 능력을 높이는데 효율적으로 adapt하는데 한계를 보입니다. LNFit이나 BitFit처럼 특정 매개변수 선택적 튜닝 기법에서는 이런 문제가 심화됩니다. 반면 GaLore 같은 기법에서 사용되는 Low-rank approximations는 full finetuning and parameter-efficient finetuning 간의 knowledge 축적과 retention를 균형 있게 제공합니다.
-
제한된 연산 자원으로 Continual learning regularization 전략은 높은 정규화 수준에서는 한계가 있지만 낮은 수준에서는 부정적인 효과가 적습니다.
how different continual learning and finetuning strategies affect knowledge accumulation and zero-shot retention at the model level
-
Naive continual finetuning : 현실적인 대규모 벤치마크에서 주요 업데이트를 처리하는 주요 방식으로 minor update
-
Parameter-efficient tuning methods(LoRA): low-rank weight approximations를 통해 메모리 요구량을 줄이면서 새로운 task에 adapting하는 방법으로, 작은 사이즈나 minor update에 적합합니다. 한편, Zhao et al. [220] 연구는 optimization gradients (GaLore)에 low-rank 근사를 통해 모델을 파인튜닝 하는 GaLore 기법이 효과적임을 보였습니다.
-
Parameter-selective tuning method(BitFit, LNFit): bias나 normalization와 같은 특정 매개변수 집합만 업데이트하여 모델을 조정합니다.
-
Traditional regularization strategies: 최근 연구에서 Traditional regularization strategies는 모델이 scratch부터 학습되어야 하는 small-scale 시나리오에서 개발되고 테스트됬음에도 불구하고 파라미터와 feature space 모두에서 강력한 성능을 보였습니다.
-
Model merging: 서로 다른 태스크에서 학습된 모델을 aggregate해서 평균으로 사용하는 Model merging 방법은 non-continual learning에서 인기를 끌고 있는데, longer adaptation periods을 위한 continual pretraining으로 유망한 방법으로 제안되었습니다.
-
본 연구는 학습이 진행될수록 단일 프롬프트로 수렴하거나 오랜 학습 기간 동안 무작위 수준의 성능으로 감소하는 문제가 있는 prompt-tuning-based continual learning와 메모리 제한이 없을 때 성능 향상이 미미한 distillation-based CL methods은 제외하였습니다.
5.1 Parameter-efficient Finetuning and Continual Learning
Figure 7의 비교 결과에서 두 가지 극단적인 성과 경향이 나타났습니다(20회 업데이트 단계 기준)
- Naive contrastive finetuning은 장기적인 안정성에 문제가 있어 forgetting이 심하고 초기 update steps에서 획득할 수 있는 지식이 제한됩니다.
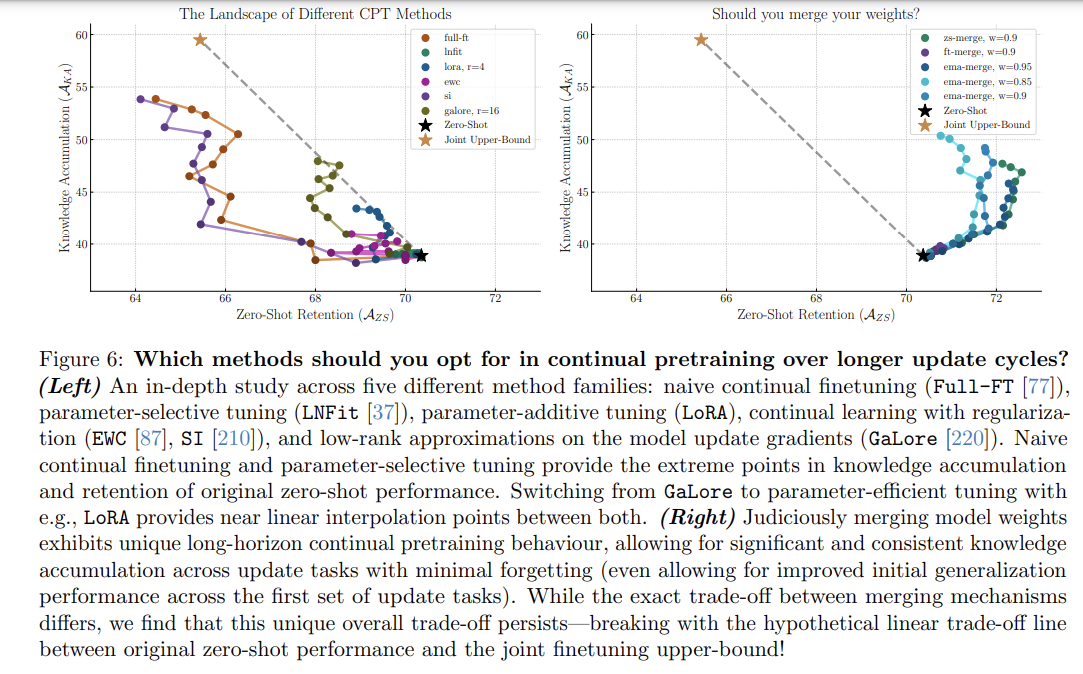
1. Strongest accumulation, weakest retention
Naive contrastive finetuning은 full update cycle에 걸쳐 knowledge accumulation에서 최고 성과를 보였지만, learning rate rewarming를 했음에도 제로샷 능력은 상당히 감소했습니다. continual contrastive finetuning에서 continual과 initial pretraining에 같은 목적식을 사용하고 이미지와 언어모델 각각 업데이트 하는 방식과 pretraining temperature 초기화 하는 방식을 사용했다.
2. Weakest accumulation, strongest retention.
LNFit 및 BitFit 같은 parameter-selective update methods는 지식 retention은 강하지만, 길고 복잡한 데이터에서 새로운 지식축적 능력은 약했습니다.
- simple finetuning으로 지식 축적과 parameter-selective updates 정도에 대한 knowledge retention 간의 trade off
- Strong accumulation, weak retention
GaLore는 모델의 forward pass가 모델학습하는 동안 더 낮은 rank gradient만 업데이트 하도록 수정함으로써 주어진 연산자원 내에 새로운 지식을 효과적으로 통합하는 능력과 원래의 제로샷 일반화 행동을 유지하는 것 사이의 적절한 균형을 제공합니다.
2. Decent accumulation, decent retention
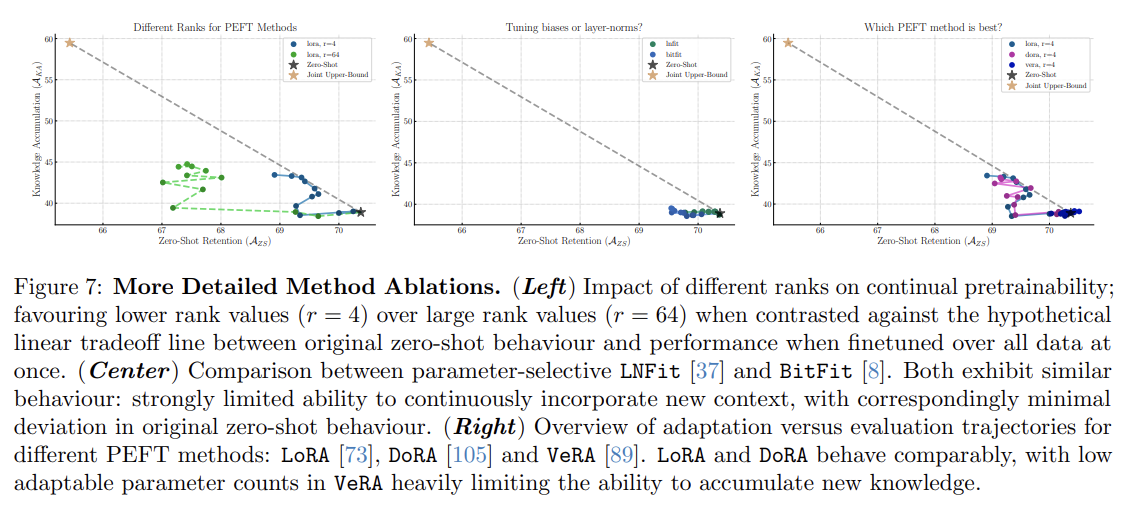
LoRA와 DoRA같은 Parameter-efficient tuning 방식은 지식 축적 및 망각이 전반적으로 적지만(특히 전체 미세 조정 대비), 지식 유지와 축적에서 GaLore와 비교했을 떄 효율적으로 linear reduction 됩니다. 이는 컨셉적으로 LoRA는 단일 domain finetuning tasks에서 효과적으로 learning하고 forgetting한다는 최신 연구 결과와 일치한다.
한편, VeRA는 튜닝 가능한 매개변수를 크게 줄여 parameter-selective tuning 방식과 유사한 성능을 보이며, 길고 복잡한 데이터에서 지식 축적 성능이 미미했습니다.
또한, accumulation-forgetting trade-off와 tunable parameter 수 간의 스케일링은 LoRA의 rank를 조정하여 해결할 수 있습니다. 그러나 초기 제로샷 성능과 파인튜닝 간의 hypothetical trade-off line에 비해 원래 일반화 성능의 손실이 달성 가능한 지식 축적보다 더 크다는 점이 주목할 만합니다.
일반화 성능의 손실은
단일 도메인 학습 및 공동 미세 조정 대비 지식 축적 성능의 한계로 작용했습니다.
지속 학습 정규화 방식의 성과 분석
정규화 방식 중 EWC(핑크, Fig. 6 좌)는 제로샷 유지 성능을 크게 향상시켰으나, 지식 축적 성능에서는 초기 성능과 큰 차이를 보였습니다. 반면 SI(퍼플, Fig. 6 좌)는 AKA와 AZS 모두에서 기본 미세 조정 대비 이점이 없었으며, 이전 연구들이 제안한 대규모 확장성의 이점을 확인하지 못했습니다.
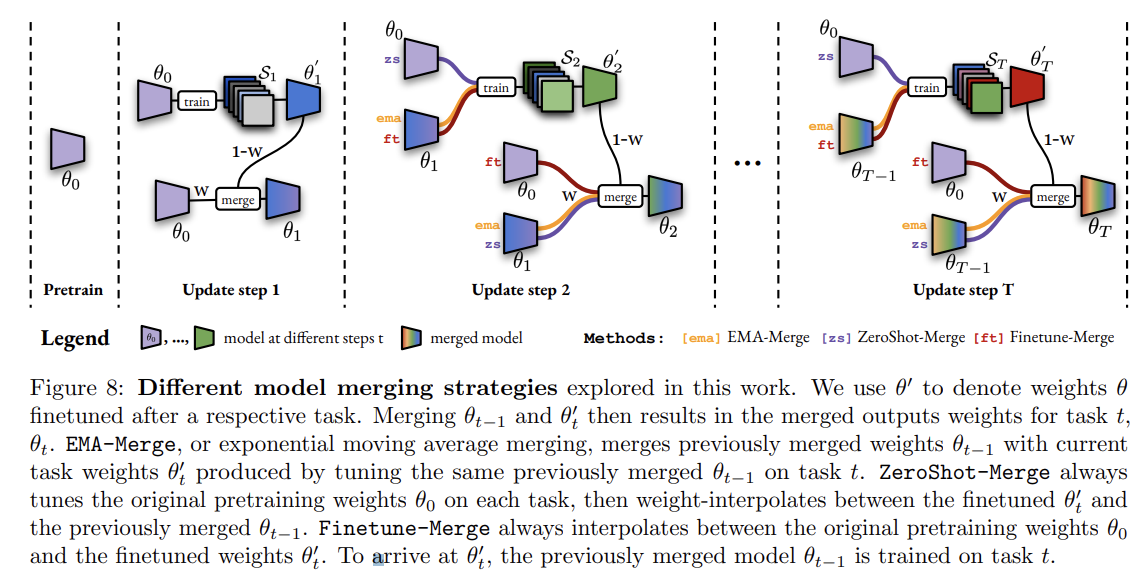
5.2 On the Benefits of Model Merging Techniques
1. Exponential-moving averaging (EMA-merge)
이전 병합된 가중치 θt−1을 태스크 t에서 미세 조정하여 가중치 θt를 생성한 뒤, θt−1과 θt를 병합하여 최종 가중치 θt를 만듭니다.
-
Continual fine-tuning and merging (Finetune-merge)
모델 초기 가중치 θ0와 미세 조정된 가중치 θt를 병합하여 θt를 생성합니다. EMA-merge와 동일하게 θt−1을 태스크 t에 맞게 조정해 θt를 만듭니다. -
Continual zero-shot merge (ZeroShot-merge)
초기 가중치 θ0을 유지하며 각 태스크에서 미세 조정된 가중치 θt와 이전 병합 가중치 θt−1을 병합하여 최종 가중치 θt를 생성합니다. 이들 병합 방식은 가중치 혼합 계수 w를 통해 새로운 가중치와 이전 가중치의 비율을 조정하며, w={0.85, 0.9, 0.95}에 대한 실험을 수행했습니다.
EMA-merge(파란색)와 ZeroShot-merge(초록색) 방식은 지식 축적(AKA)에서 좋은 성능을 보이며, 특히 제로샷 유지 성능에서 상당한 향상을 보여줍니다. 이 성능은 특히 첫 업데이트 태스크에서 두드러졌으며, 전체 업데이트 사이클 동안 소폭의 성능 향상을 유지했습니다.
혼합 계수 w를 변화시킨 결과, w 값이 높을수록 제로샷 유지 성능은 향상되었지만 지식 축적은 다소 제한되었습니다. 그러나 모든 실험 조건에서 고수준의 계속적 사전 학습 동적 특성은 일관되게 유지되었고, 초기 제로샷 성능과 합동 미세 조정 성능 상한선 간 가상의 선형 트레이드오프를 벗어나 유리한 결과를 제공했습니다.
이러한 성과는 이전 섹션의 다른 방법군들과 대조적으로, 제로샷 일반화 성능을 유지하면서도 강력한 지식 축적을 가능하게 했습니다.
6 Continual Pretraining: General Training Recipes
1. 학습률 및 스케줄의 중요성
장기 업데이트 주기에서 계속적 사전 학습을 진행할 때, 각 업데이트 작업에 대한 특정 스케줄 선택은 제한적인 영향을 미치지만, 초기 사전 학습 가중치에서의 편차에 따라 각 작업별 스케줄을 조정하는 메타 스케줄을 정의하면 망각을 크게 줄이면서도 지식 축적을 거의 동일하게 유지할 수 있습니다. 이러한 메타 스케줄은 추가 하이퍼파라미터 없이 자연스럽게 도출될 수 있습니다.
-
모델 크기의 중요성
모델 크기를 증가시키면 일반화 성능의 유지가 지식 축적과의 트레이드오프에서 훨씬 덜 중요해집니다. 증가된 용량은 모델이 높은 수준의 새로운 지식을 습득할 수 있도록 하며, 높은 망각률을 발생시키지 않게 하고 긍정적인 역전이를 가능하게 합니다. 따라서, 긴 모델 업데이트 사이클을 예상할 때는 초기 훈련 비용이 높더라도 더 큰 모델의 미래 안정성을 고려하는 것이 중요합니다. -
계산량 조정의 중요성
고정된 모델 크기에서 계산량을 증가시키는 것이 단순 미세 조정에서는 지식 축적과 망각의 트레이드오프를 개선하지 않지만, 모델 병합과 함께 추가적으로 계산량을 늘리면 지식 축적 및 망각 트레이드오프가 개선됩니다. -
전면적 모델 튜닝의 우수성
긴 업데이트 사이클에서는 고정된 이미지 또는 텍스트 인코더 훈련보다 전체 모델 튜닝이 더 효과적입니다. -
초기 안정성 문제의 완화
초기 안정성 격차 문제는 사전 학습과 이후의 계속적 사전 학습 소프트맥스 온도를 일치시킴으로써 강력하게 완화됩니다.
TL;DR
학습률 스케줄은 업데이트 사이클 기간을 고려해야 합니다.
더 큰 모델과 계산량(특히 모델 병합과 함께 증가시킬 경우)은 지식 축적이 초기 지식 유지에 미치는 영향을 줄이면서 전반적으로 더 나은 축적-유지 트레이드오프를 제공합니다.
이 섹션은 지속적인 사전 훈련 파이프라인 설계와 관련하여 특정 방법론적 업데이트 전략과 관련된 자유도를 조사합니다. 특히, 긴 마이너 업데이트 사이클에서의 파이프라인 속성을 연구합니다. 주요 내용은 다음과 같습니다:
학습률 및 일정의 중요성
섹션 6.1에서는 학습률의 중요성과 그 일정에 대해 논의하며, 초기 사전 훈련 일정과 지속적 사전 훈련 일정을 일치시킬 필요성과 메타 학습률 일정을 선택할 수 있는 옵션을 다룹니다.
모델 및 컴퓨팅 스케일링의 영향
섹션 6.2에서는 모델 크기와 할당된 컴퓨팅 예산 증가가 지식 축적과 제로샷 유지의 균형에 미치는 영향을 평가합니다. 이는 같은 모델 패밀리 내에서의 모델 크기 증가와 고정된 모델 크기 내에서의 컴퓨팅 예산 증가를 고려하여, 긴 마이너 업데이트 사이클에서 모델을 배치할 때 최적화해야 할 독립적인 축으로 다뤄집니다.
이미지 및 텍스트 인코더의 공동 조정의 관련성
섹션 6.3에서는 이미지 또는 텍스트 인코더를 고정한 훈련 방식과 비교하여, 두 인코더를 함께 조정하는 것의 중요성을 강조합니다.
소프트맥스 온도의 정렬 중요성
섹션 6.4에서는 초기 및 지속적인 사전 훈련 소프트맥스 온도를 일치시키는 것이 중요하다고 언급하며, 이를 통해 안정성 격차 문제를 최소화할 수 있음을 설명합니다.
이 섹션은 지속적인 사전 훈련 파이프라인 설계의 주요 요소를 강조하며, 각 요소가 긴 업데이트 사이클 동안 지식 축적과 유지에 미치는 영향을 최적화하는 데 중요하다는 것을 보여줍니다.
6.1 학습률, 일정 및 메타 일정
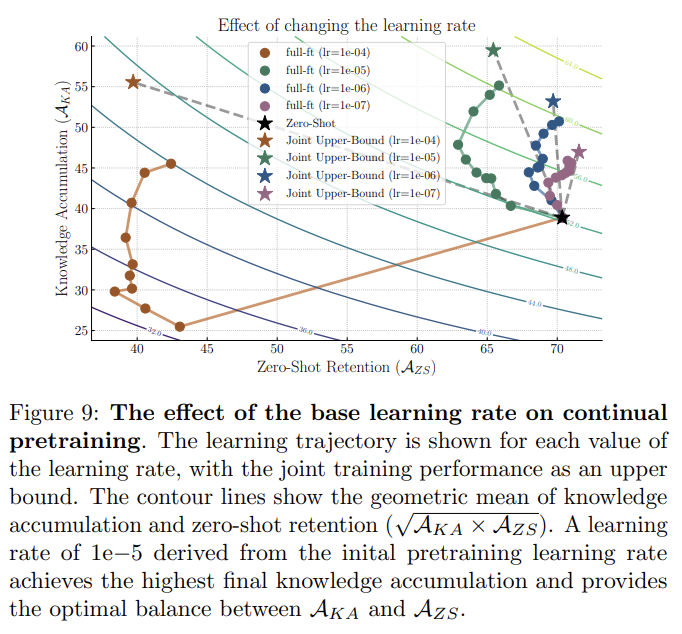
학습률 선택의 영향
지속적인 사전 훈련 문제에 대한 학습률을 정의하기 위해, 우리는 Cherti et al. [29]의 원래 사전 훈련 값(1e-3)에서 직접 도출합니다. 우리는 컴퓨팅 가용성의 실질적인 차이를 고려하여 정확한 피크 값을 수정했으며, 배치 크기로 bours = 512 대신 bopenclip = 88064를 사용했습니다. 일반적으로 사용되는 선형 크기 조정([53])과 제곱근 크기 조정([93])을 모두 테스트하여 각각 λscaled = bours/bopenclip · λopenclip를 도출했습니다. 초기 실험에서는 선형 크기 조정된 값을 반올림하여 λscaled = 1e-5로 설정하는 것이 두 옵션보다 약간 더 나은 성능을 보여주었습니다. 따라서 우리는 1e-5를 기본 학습률로 선택했습니다. 그림 9에서 보듯이, 이 최대 학습률의 대부분 직접적인 재사용은 지식 축적의 정도가 가장 높고, 제로샷 유지와 관련하여 가장 높은 기본 상호 작용을 달성합니다. 더 큰 학습률은 특히 초기 작업에서 높은 잊어버림 비율을 초래하며, 더 작은 학습률은 얻는 지식의 양을 제한합니다. 따라서 우리는 기본 학습률로 λscaled = 1e-5를 설정합니다.
지속적인 사전 훈련 학습률 일정
기본적으로, 학습률 일정은 각 작업에 대해 개별적으로 적용됩니다[20, 163, 16, 173, 109]. OpenCLIP 모델은 코사인 일정을 사용하여 훈련되므로, 우리는 각 작업에 대해 동일한 코사인 일정을 재적용하는 것의 영향을 먼저 연구합니다. 여기서 ηn ∈ [ηmin, ηmax]는 n 단계에서의 학습률이며, Ntask는 주어진 작업에 대한 업데이트 단계 수입니다. Ibrahim et al. [77]에서 추천하는 바와 같이, 우리는 Nwarm 반복을 위해 Cherti et al. [29]에서 사용된 초기 사전 훈련 피크 학습률 ηmax에 대해 선형 워밍업을 사용합니다.
추가적으로, 장기적으로 더 많은 유연성을 위해 학습률 일정의 전환, 예를 들어 무한 학습률 변형으로의 전환의 영향을 연구하기 위해, Zhai et al. [212]에서 도입된 역제곱근 일정(rsqrt)으로의 전환을 조사합니다. rsqrt 일정에는 이전에 감소된 학습률을 선형으로 식히기 위해 마지막 Ncool 단계가 사용되는 별도의 쿨다운 섹션이 포함되어 있습니다.
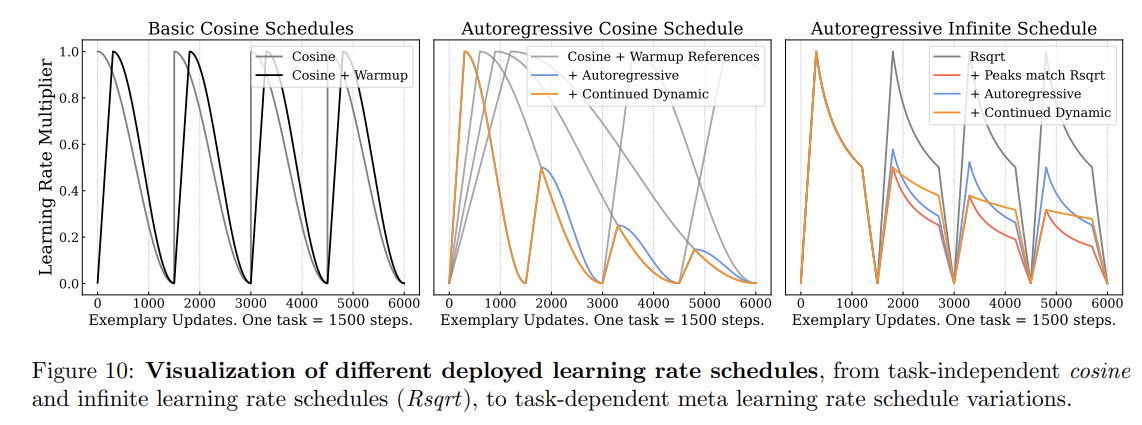
학습률 일정 및 메타 학습률 일정
학습률 일정의 시각화
모든 일정은 여러 작업에 걸쳐 그림 10(왼쪽 및 오른쪽)에 시각화되며, 사전 훈련 학습률 일정의 적용 결과(일치 및 변경)가 그림 11(가운데)에 시각화됩니다. 결과를 보면, 두 가지 학습률 일정 모두 지식 축적(AKA) 및 지식 유지에서 미미한 변화를 보이며, 긴 업데이트 주기에서는 원래 사전 훈련 일정과의 일치가 덜 중요함을 강조합니다.
메타 학습률 일정
이전 경우에는 각 중간 업데이트가 독립적으로 처리됩니다(그림 10 왼쪽의 일정 시각화 참조). 즉, 각 작업이 동일한 학습률로 워밍업 및 쿨다운되며 동일한 감쇠 및 쿨다운 동역학을 따릅니다. 그러나 이러한 지속적인 사전 훈련 업데이트가 연속적으로 발생하면서, 이전 작업에 대한 재앙적 잊음도 고려해야 합니다. 또한 각 작업 업데이트 시 모델은 사전 훈련 시작점에서 점점 더 멀어지는 방향으로 이동해야 합니다.
작업 수준의 잊음 및 사전 훈련에서의 이동 증가의 영향을 줄이기 위해, 우리는 메타 학습률 일정(meta LR scheduling)을 도입합니다. 이는 각 작업별 반복 수준의 학습률 일정을 통해 작업의 연속성을 고려하는 것입니다. 이러한 일정은 이전 작업 일정이 새로운 모든 작업으로 단순히 연장되는 가상의 시나리오에서 자연스럽게 파생됩니다(그림 10 중앙의 회색 가상 일정 참조).
특히 네 가지 메타 일정을 탐색합니다:
자기 회귀 코사인 일정: 각 작업 일정에 대해 ηmax를 선택하며, 현재 및 모든 이전 작업에 대한 가상의 코사인 일정을 기반으로 하여 워밍업이 이루어지며, 각 작업의 워밍업 과정과의 교차점에서 설정됩니다.
자기 회귀 계속 동적 일정: 동일한 ηTmax로 워밍업한 후, 모든 이전 단계 Nprevious와 현재의 포스트 워밍업 단계 Nwarm에 대한 가상의 코사인 일정에 따라 계속됩니다.
자기 회귀 rsqrt 일정: ηmax를 ηrsqrt(n′, N′task)로 설정하여 동일한 방식을 따릅니다.
기본 일정 연장: 가상의 기본 일정을 연장하여 계속하는 방식입니다.
“피크를 rsqrt에 맞추기”: 각 ηmax가 지속 동역학과 일치하며 표준 rsqrt 일정으로 계속됩니다.
지속적인 모델 업데이트에 대한 작업 및 메타 수준 학습률 일정의 영향은 그림 11에서 기본 20 작업 변형인 FoMo-in-Flux를 사용하여 단순 지속적 미세 조정을 참조 방법으로 시각화합니다. 긴 지속적 사전 훈련 시퀀스의 경우, 작업 독립 일정에서 메타 학습률 일정으로 전환하면 축적과 유지 간의 상호작용 행동이 눈에 띄게 변화합니다. 다양한 메타 일정 변형 내에서는 큰 차이가 없지만(그림 11 왼쪽 및 오른쪽 참조), 메타 학습률 일정은 초기 제로샷 전이 성능의 유지에 있어 훨씬 더 우수한 결과를 제공합니다.
코사인 학습률 일정에서 파생된 메타 일정의 경우, 학습률의 빠른 감소로 인해 축적된 새로운 지식이 심각하게 감소합니다(그림 10 왼쪽 참조). 반면, rsqrt 일정과 같은 무한 학습률 일정에서 파생된 메타 일정은 학습률의 감소가 덜 공격적이기 때문에 긴 기간의 지속적 사전 훈련 작업에 훨씬 더 적합합니다. 그림 10(오른쪽)에서 자가 회귀 rsqrt 메타 일정은 AKA의 거의 동일한 이득을 달성하면서 보유 지식을 크게 증가시키고, 초기 제로샷과 공동 미세 조정 간의 가상의 선형 무역 거래선을 초과합니다.
