- BERT는 bidirectional 언어모델로 pretrained 후 finetuning을 거쳐 NLU task를 잘 수행하지만, unidirectional 언어모델인 GPT는 NLU task를 수행하기에 다른 유형 대비 적합하지 못하다.
- 그러나 GPT3의 입력 프롬프트에 어떤 태스크인지 설명을 넣어주는 handcrafted prompts를 이용한 in context learning의 zero-shot, few-shot의 높은 성능은 기존의 생각이 틀렸음을 보여주었다.
- llm도 finetuning을 해주면 성능이 더 높아지지만 파라미터 사이즈가 워낙 크기 때문에 재학습을 하는데 시간과 자원이 많이 소요되어 현실적으로 어려움이 많다.
- 이러한 문제를 해결하는데 P-tuning과 LoRA가 있다. 둘다 사전 학습된 가중치는 그대로 두고, 별도로 추가된 레이어만 새로운 데이터로 학습하는 원리이다.
- P-tuning은 pre-trained language model(PLM)의 전체 weight를 fine-tuning하지않고, continuous prompt embeddings만 tuning하는 방법입니다.
P-tuning
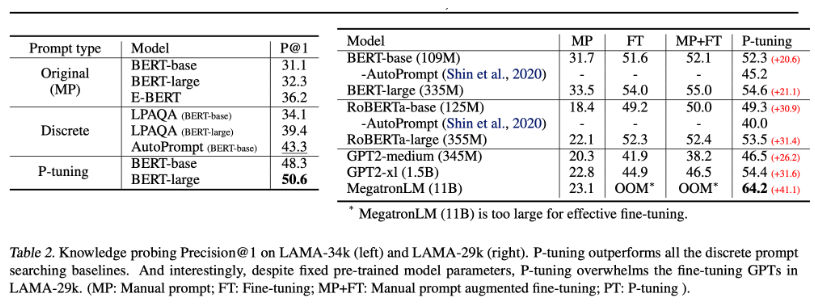
- 아래 테이블에서 확인할 수 있듯 handcrafted manual prompts를 어떻게 구성하느냐에 따라서 성능의 변화가 심한기 때문에 handcrafted manual prompts를 최적화하는 것은 매우 어렵다.

- 이와 관련하여 in-context learning의 성능을 높이기 위해 handcrafted manual prompts를 사용하는 것이 아닌 데이터로부터 discrete prompts를 찾는 방법들이 많이 연구되어 왔지만, 신경망이 본애 continuous하기 때문에 이는 sub-optimal이라고 볼 수 있다.
- 그래서 저자는 본 논문에서 continuous prompt를 데이터를 사용해서 학습하는 방법인 P-tuning을 제안한다.
P-tuning leverages few continuous free parameters to serve as prompts fed as the input to the pre-trained language models. We then optimize the continuous prompts using gradient descent as an alternative to discrete prompt searching.
Methods
-
discrete prompts의 경우 특정 template T를 만들어내는 함수가 p라고 하면,
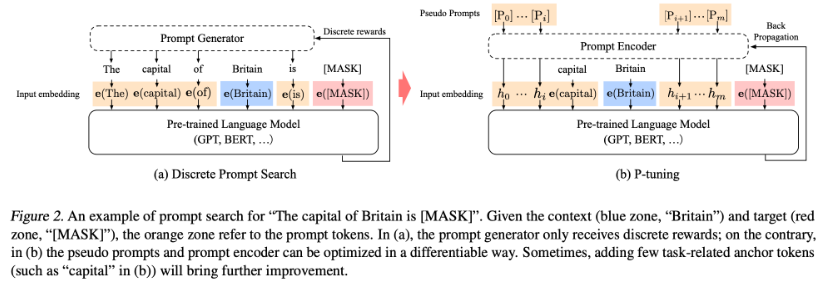
ex. The capital of Britain is [MASK] -> {e(The),e(capital),e(of),e(Britain),e(is),e([Mask])} -
continuous prompts의 경우 prompt 부분이 임의의 pseudo token(e.g. [PROMPT])의 sequence로 교체된다. 여기서 h는 pseudo token을 임베딩하는 모델인 프롬프트 인코더를 의미하며 논문에서는 bidirectional LSTM에 two-layer MLP를 얹은 model을 사용하였습니다.
ex. [PROMPT] ... [PROMPT] Britain [PROMPT] ... [PROMPT][MASK] -> {h([PROMPT]),h([PROMPT]),...,e(Britain),h([PROMPT]),...,h([PROMPT]),e([Mask])}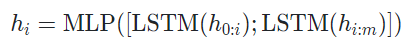
-
본 논문에서는 knowledge probing(LAMA)와 superglue에 1. Manual Prompt(MP), 2. Fine-tuning(FT), 3. Manual Prompt with Fine-tuning(MP+FT), 4. P-tuning 방법론으로 실험을 진행하였는데, LAMA에서는 P-tuning을 활용하는 방법이 다른 방법론들에 비해 대체적으로 성능이 좋음을 확인할 수 있었다. 특히 P-tuning의 경우 사전학습된 가중치를 업데이트하지 않고 프롬프트 인코더의 가중치만 업데이트 하기 때문에 파인튜닝과 달리 상대적으로 큰 모델을 사용할 수 있는 장점이 있다.
LoRA
LoRA는 사전 학습된 모델의 중간 중간에 adapter layer를 넣어 pretrained layer 와 adapter layer의 결과를 합쳐러 출력값을 생성한다. 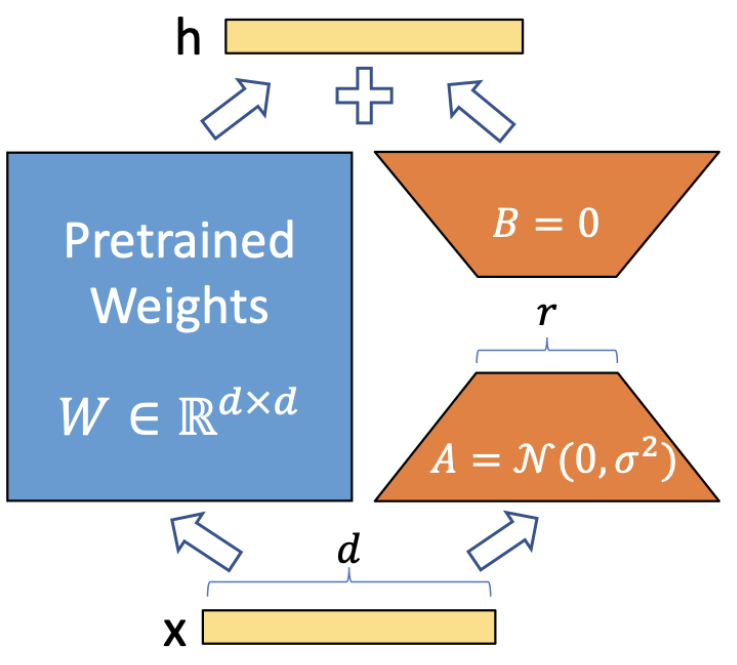
QLoRA
LoMo
Reference
https://arxiv.org/abs/2103.10385
