Transformer
Add and normalize
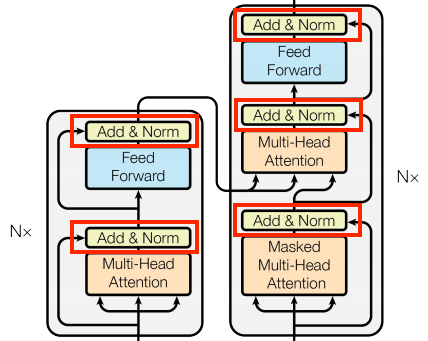
Add and normalize 블록은 residual connection 와 LayerNormalization layer입니다.
1. ~~residual connection은 gradient의 direct path을 제공해 벡터가 attention layer에 대체되는게 아닌 업데이트됩니다. ~~
2. Normalization은 아웃풋에 합리적인 scale을 줍니다.
The base attention layer
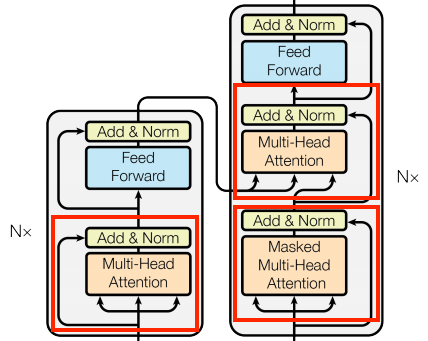
1. MultiHeadAttention
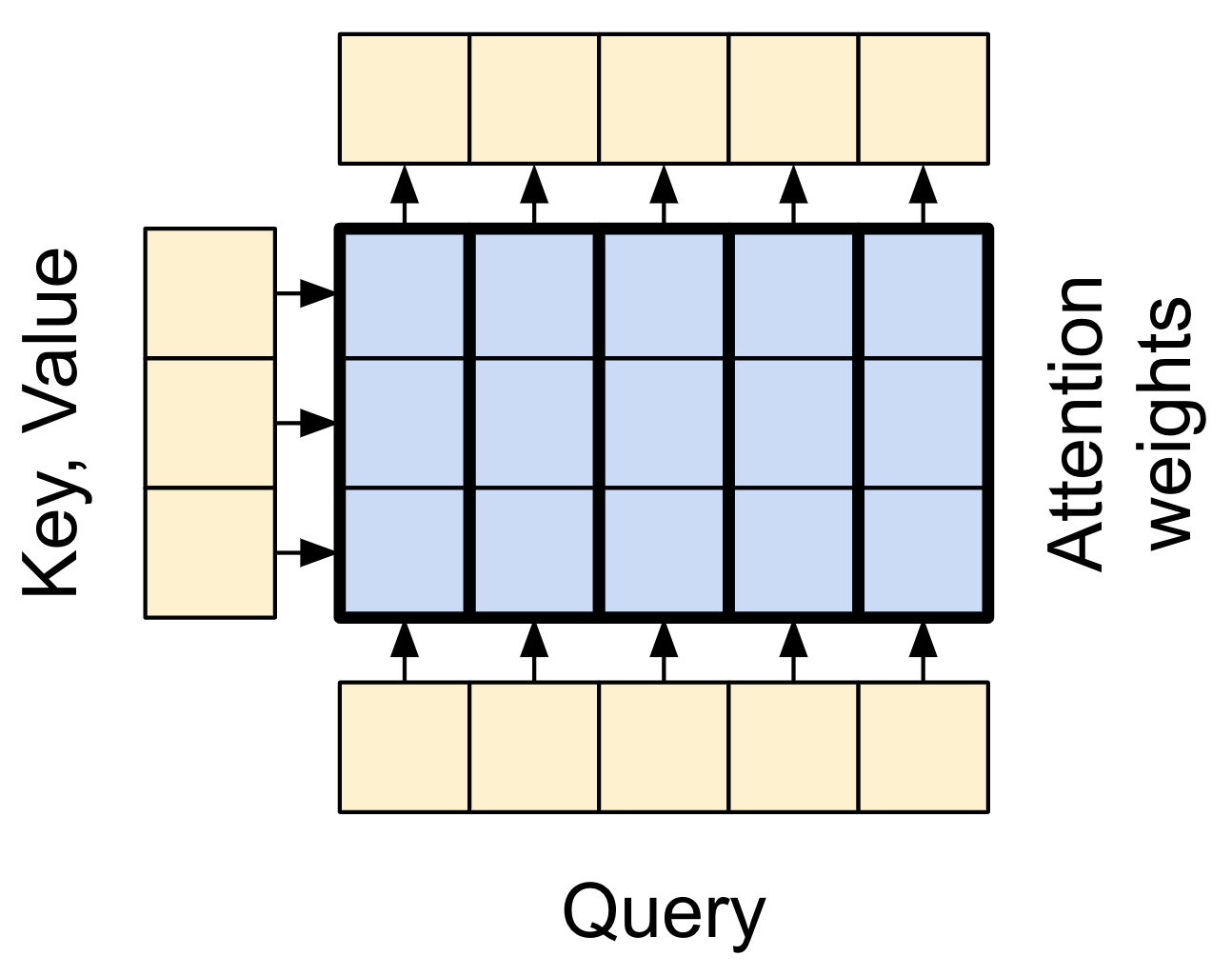
fuzzy, differentiable, vectorized dictionary lookup이다.
attention layer는 query와 key 벡터가 attention score에 매치하는 방법을 결정해 attention scores로 weighted된 모든 value를 평균내 반환합니다.
2. LayerNormalization
3. Add
The cross attention layer
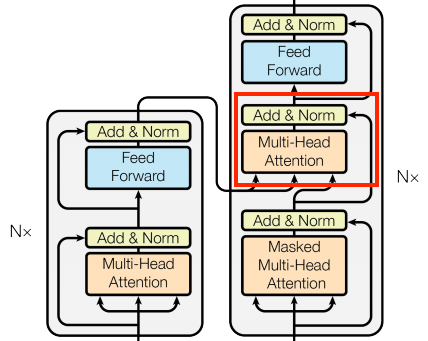
인코더와 디코더를 연결하는 레이어로 모델에서 가장 직접적으로 attention을 사용해 태스크를 수행합니다.
attention score는 cache하고 x, attn_output을 같이 layer normalization한다.
class CrossAttention(BaseAttention):
def call(self, x, context):
attn_output, attn_scores = self.mha(
query=x,
key=context,
value=context,
return_attention_scores=True)
# Cache the attention scores for plotting later.
self.last_attn_scores = attn_scores
x = self.add([x, attn_output])
x = self.layernorm(x)
return xReference
https://www.tensorflow.org/text/tutorials/transformer

Deep learning