Mongo DB 1편
MongDB 쓰는 이유
MongoDB 사용하는 가장 큰이유는 데이터 구조가 고정되어 있지 않아 변화에 유연하게 대응할 수 있고 대규모 데이터를 처리하기 위한 확장이 쉽기 때문입니다.
데이터 구조가 고정되어 있지 않은 예시는 아래와 같습니다.
-- 1. 기존 테이블 구조 확인 (이름, 이메일만 있음)
-- DESC users;
-- 2. 서비스 운영 중에 필드를 추가하려면 'ALTER' 명령 실행
-- 데이터가 수백만 건이면 이 명령을 실행하는 동안 테이블이 잠길(Lock) 수 있습니다.
ALTER TABLE users ADD COLUMN mbti VARCHAR(10) DEFAULT NULL;
-- 3. 데이터 삽입
INSERT INTO users (name, email, mbti) VALUES ('김철수', 'chul@example.com', 'ENFP');코드를 입력하세요/ 별도의 'ALTER' 과정 없이 바로 저장 시도
// 기존 사용자 (필드 2개)
const user1 = {
name: "이영희",
email: "young@example.com"
};
// 새로운 사용자 (필드 3개 - mbti 추가)
// DB 설정을 건드리지 않고 그냥 데이터를 보냅니다.
const user2 = {
name: "박지민",
email: "jimin@example.com",
mbti: "ENFP"
};
// MongoDB 컬렉션에 삽입 (두 데이터의 모양이 달라도 오류 없이 저장됨)
db.users.insertMany([user1, user2]);그렇다면 MongoDB가 대규모 확장이 쉽다는 것은 무엇일까요?
그전에 수평적, 수직적 확장 개념부터 설명하도록 하겠습니다.
수직적 확장은 단순히 데이터베이스 서버의 성능을 향상 시키는 것이고 수평적 확장은 리소스 풀에 더 많은 시스템 서버가 추가되어 DB를 전체적으로 분산 시킵니다.
Mongodb는 사용자가 갑자기 100만 명, 1,000만 명으로 늘어나도 서버를 옆으로 계속 붙여서 수평적 확장을 통해 확장이 쉽다는 뜻입니다.
그렇다면 왜 RDB는 수평적 확장에서는 관리하기 어려운지 한번 알아보겠습니다.
RDB 수평적 확장
RDB에서 수평확장을 하는 방식을 샤딩(Sharding) 이라고 합니다. 개념 자체는 단순해요. 데이터를 구간별로 잘라서 여러 디바이스에 나눠 저장하는 것입니다.
예를 들어 사용자 테이블이 있다면, 1~2번 사용자는 디바이스 A에, 3~4번 사용자는 디바이스 B에 저장하는 식입니다. 그런데 문제는 관계 테이블이 생기는 순간부터 시작됩니다.
"사용자가 영상을 업로드했다", "사용자가 영상을 시청했다" 같은 관계 데이터는 어떤 기준으로 나눠야 할까요? 최악의 경우 1번 사용자 정보는 A 디바이스에, 해당 사용자의 시청 기록은 B 디바이스에, 그 영상 데이터는 새로 추가된 C 디바이스에 흩어질 수 있습니다.
즉, 특정 사용자에 대한 데이터를 조회하려면 여러 디바이스를 동시에 탐색해야 하는 상황이 생깁니다. 디바이스가 늘어날수록, 관계가 복잡해질수록 이 문제는 기하급수적으로 커집니다.
NoSQL 수평확장
NoSQL은 구조 자체가 다릅니다. 관계를 분리하지 않고, 한 사용자에 관련된 모든 데이터를 하나의 컬렉션에 묶어서 저장합니다. 데이터 중복이 생기더라도 이를 허용하는 대신, 조회 효율을 극대화하는 방식입니다.
덕분에 수평확장을 할 때는 단순히 구간만 잘라서 디바이스에 나눠 담으면 됩니다. 1번 사용자의 정보, 시청 기록, 업로드 영상 정보가 전부 A 디바이스 안에 있기 때문에, 디바이스가 추가되더라도 다른 디바이스를 탐색할 필요가 없습니다.
MongDB 샤딩
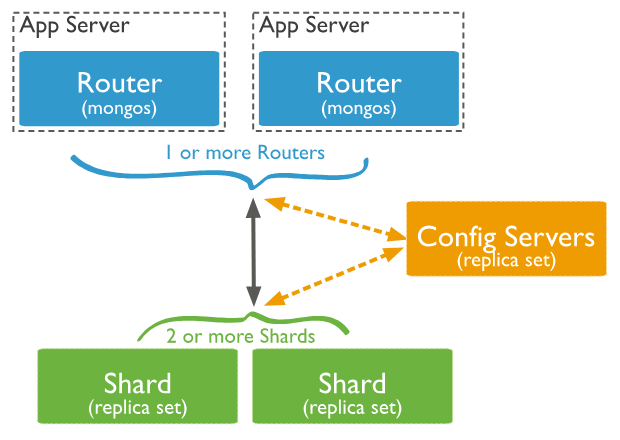
샤딩이란 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있는 기술을 말합니다. 복제와는 전혀 다른게 단순히 데이터를 복사해서 여러서버에 두어 고가용성을 위한 솔루에 해당하기 때문입니다.
MongoDB에서 샤딩을 구현하려면 총 3종류의 서버가 필요합니다.
Config Servers
- Sharded Cluster의 메타 데이터, Configuration 등을 저장하는 서버.
- 클러스터 전체 구조를 구성하는 데에 있어 핵심 정보를 담고 있기 때문에, 대부분 Replica Set으로 두 개 이상의 노드를 두는 것을 권장합니다.
Mongos (Router)
- 중개자 역할을 합니다. 어플리케이션 서버와 Shard Cluster 간의 인터페이스를 제공하며, 쿼리 라우터의 역할도 수행합니다. (MongoDB는 특정 Shard에 접속하여 직접적으로 DB에 엑세스할 수 없습니다.)
- Config Server의 정보를 기반으로 Data Chunk의 위치를 찾아가는 역할을 수행하며, 이때 Config Server의 메타 데이터에 대한 캐싱도 수행합니다..
- Sharded Cluster에서 최소한 1개 이상의 Mongos 서버가 존재해야 합니다.
shard
- 실제적으로 데이터가 저장되는 저장소의 역할을 합니다.
- 분산 처리가 샤딩의 목적이므로, Sharded Cluster에서 최소한 2개 이상의 Shard 서버가 존재해야 한다. 또한 각 샤드마다 Replica Set으로 구현하는 것도 가능합니다.
Replica set
MongoDB의 Replica set이란 같은 데이터셋을 가지고 있는 여러 mongos 프로세스 그룹입니다.
Replica set은 크게 세 가지 역할로 나눌 수 있습니다.
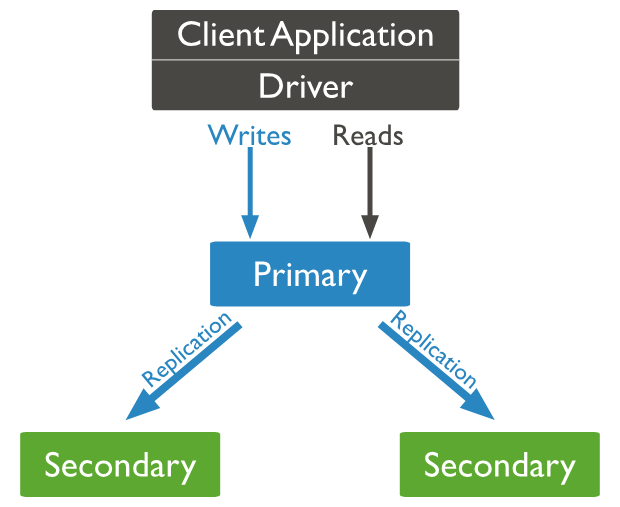
Primary: 클라이언트에서 DB로 읽기 및 쓰기 작업을 합니다.
Secondary: 프라이머리로부터 데이터를 동기화 한다. Primary에 장애가 발생한 경우, 투표를 통해 Primary가 될 수 있습니다. 클라이언트 단에서 read preference 설정을 하면 secondary도 read operation을 수행할 수 있습니다.
Arbiter: 데이터를 동기화하지는 않으며 primary 선정을 위한 투표권만 주어집니다.
