MongoDB 모델링 패턴
MongoDB 모델링 패턴 정리
MongoDB는 Document 방식을 사용하기 때문에 RDBMS와는 다른 방식으로 모델링을 해야한다.
Model Tree Structure
같은 Collection에서 데이터가 서로를 참조하는 Tree 구조를 가지고 있을 때 사용할 수 있는 패턴은 다섯 가지가 있다. 소개하는 모든 패턴은 아래 트리 구조를 기준으로 구성했다.
Books
└── Programming
├── Databases
│ ├── MongoDB
│ └── dbm
└── Languages1. Parent References
각 Document가 부모 노드를 참조하는 방식이다.
[
{ _id: "MongoDB", parent: "Databases" },
{ _id: "dbm", parent: "Databases" },
{ _id: "Databases", parent: "Programming" },
{ _id: "Languages", parent: "Programming" },
{ _id: "Programming", parent: "Books" },
{ _id: "Books", parent: null }
]- ✅ 부모 Document를 바로 찾아야 하는 경우 적합
- ❌ 하위 트리를 모두 탐색해야 하는 경우 적합하지 않음
2. Child References
각 Document가 자식 노드 목록을 배열로 가지는 방식이다.
[
{ _id: "MongoDB", children: [] },
{ _id: "dbm", children: [] },
{ _id: "Databases", children: ["MongoDB", "dbm"] },
{ _id: "Languages", children: [] },
{ _id: "Programming", children: ["Databases", "Languages"] },
{ _id: "Books", children: ["Programming"] }
]- ✅ 자식 Document를 바로 찾아야 하는 경우 적합
- ❌ 부모 탐색은 Parent References보다 느림
3. Array of Ancestors
조상 노드 전체를 배열로 저장하는 방식이다.
[
{ _id: "MongoDB", ancestors: ["Books", "Programming", "Databases"], parent: "Databases" },
{ _id: "dbm", ancestors: ["Books", "Programming", "Databases"], parent: "Databases" },
{ _id: "Databases", ancestors: ["Books", "Programming"], parent: "Programming" },
{ _id: "Languages", ancestors: ["Books", "Programming"], parent: "Programming" },
{ _id: "Programming", ancestors: ["Books"], parent: "Books" },
{ _id: "Books", ancestors: [], parent: null }
]- ✅ 조상 Document를 즉시 알아야 하는 경우 적합 (Breadcrumb 등에 활용)
- ✅ 하위 Document를 모두 찾아야 하는 경우 적합
- ❌ 여러 부모를 가지는 구조에는 적합하지 않음
4. Materialized Paths
조상 경로를 String 타입으로 저장하는 방식이다. Array of Ancestors와 유사하지만 정규식으로 하위 트리 탐색이 가능하다.
[
{ _id: "Books", path: null },
{ _id: "Programming", path: ",Books," },
{ _id: "Databases", path: ",Books,Programming," },
{ _id: "Languages", path: ",Books,Programming," },
{ _id: "MongoDB", path: ",Books,Programming,Databases," },
{ _id: "dbm", path: ",Books,Programming,Databases," }
]- ✅ 하위 트리 탐색 속도가 Array of Ancestors보다 빠름(Materialized Paths같은 경우에는 정규표현식으로 찾을 수 있기 때문)
- ❌ 공통 부모 탐색이 필요한 경우엔 더 느려질 수 있음
5. Nested Sets
left, right 번호를 이용해 트리 범위를 표현하는 방식이다.
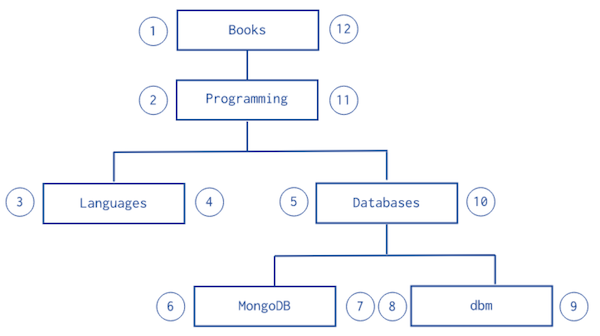
[
{ _id: "Books", parent: 0, left: 1, right: 12 },
{ _id: "Programming", parent: "Books", left: 2, right: 11 },
{ _id: "Languages", parent: "Programming", left: 3, right: 4 },
{ _id: "Databases", parent: "Programming", left: 5, right: 10 },
{ _id: "MongoDB", parent: "Databases", left: 6, right: 7 },
{ _id: "dbm", parent: "Databases", left: 8, right: 9 }
]- ✅ 하위 트리 탐색이 가장 빠르고 효율적(숫자 대소 비교를 통해서 연산을 하기 때문)
- ❌ 데이터 추가/삭제/변경 시 번호 재계산 비용이 크기 때문에 정적인 구조에만 적합
Model Relationships
MongoDB도 RDBMS와 마찬가지로 1:1, 1:N, N:M 관계를 구성할 수 있다. RDBMS가 참조 방식만 제공하는 것과 달리 MongoDB는 참조(Reference) 와 포함(Embed) 두 가지를 제공한다.
참조: Foreign Key처럼 키를 이용해 연결
포함: Document 안에 Object로 데이터를 직접 저장
1:1
가급적 Sub Document로 Embed하는 것이 좋다. Document 크기가 너무 커지는 경우에만 분리한다.
1:N
1이 N을 참조하거나, N이 1을 참조하는 두 가지 방법이 있다.
// 1이 N을 참조하는 방식
// Movie Collection
{ title: "Star Wars", reviews: [1, 2, 3] }
// Review Collection
[
{ _id: 1, comment: "Good" },
{ _id: 2, comment: "Good" },
{ _id: 3, comment: "Good" }
]// N이 1을 참조하는 방식
// Movie Collection
{ title: "Star Wars" }
// Review Collection
[
{ _id: 1, title: "Star Wars", comment: "Good" },
{ _id: 2, title: "Star Wars", comment: "Good" },
{ _id: 3, title: "Star Wars", comment: "Good" }
]N:M
1:N에서 1이 N을 참조하는 방식으로 서로 참조하면 구성된다.
Modeling Pattern
MongoDB는 Subquery나 Join을 제공하지 않는다. Aggregation으로 유사하게 사용할 수 있지만 여러 Collection을 참조할수록 성능이 크게 저하되기 때문에 권장하지 않는다.
이를 보완하기 위해 모델링 패턴을 활용한다. 아래는 자주 쓰이는 여섯 가지 패턴이다.
1. Attribute 패턴
동일한 성격의 필드를 하나로 묶어서 인덱스 수를 줄이는 패턴이다.
// Before
{
title: "Star Wars",
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00")
}
// 이 경우 필요한 인덱스
{ release_US: 1 }
{ release_France: 1 }
{ release_Italy: 1 }
// ...// After (Attribute 패턴 적용)
{
title: "Star Wars",
releases: [
{ location: "USA", date: ISODate("1977-05-20T01:00:00+01:00") },
{ location: "France", date: ISODate("1977-10-19T01:00:00+01:00") },
{ location: "Italy", date: ISODate("1977-10-20T01:00:00+01:00") },
{ location: "UK", date: ISODate("1977-12-27T01:00:00+01:00") }
]
}
// 인덱스 2개로 해결
{ "releases.location": 1, "releases.date": 1 }2. Extended Reference 패턴
관계가 있는 Document에서 자주 사용하는 데이터를 미리 복사해두는 패턴이다.
MongoDB에서 Join 성능은 열악하기 때문에 보통 쿼리를 두 번 날려 연관 데이터를 불러온다. 데이터가 많아질수록 이 방식도 부담이 되기 때문에 자주 참조하는 필드를 아예 해당 Document에 저장해두는 것이다.
// Order Collection (Extended Reference 적용)
{
order_id: 12345,
customer_id: "abc",
// 자주 쓰이는 고객 정보를 미리 저장
customer_name: "John Doe",
customer_email: "john@example.com",
items: [...]
}3. Subset 패턴
관계가 있는 Document 사이에서 자주 사용하는 데이터 일부만 Embed하는 패턴이다. Extended Reference와 비슷해 보이지만 다르다.
예를 들어 상품 Document에 리뷰를 전부 Embed하면 Document가 너무 커지고, 별도 Collection으로 분리하면 쿼리를 두 번 날려야 한다. 이 때 최신 5개 리뷰만 상품 Document에 저장해두는 식으로 해결할 수 있다.
// Product Collection (Subset 패턴 적용)
{
_id: 1,
title: "어떤 상품",
price: 10000,
// 최신 리뷰 5개만 저장
top_reviews: [
{ user: "유저A", comment: "좋아요", rating: 5 },
{ user: "유저B", comment: "별로에요", rating: 2 },
// ...
]
}
// Review Collection (전체 리뷰는 별도 보관)
[
{ product_id: 1, user: "유저A", comment: "좋아요", rating: 5 },
// ...
]데이터 수정이 발생하면 양쪽을 모두 수정해야 한다. MongoDB를 주력으로 사용한다면 정말 많이 쓰이는 패턴이다. 꼭 기억해두자.
4. Computed 패턴
통계 수치를 데이터 삽입 시점에 미리 계산해서 저장하는 패턴이다.
집계 함수는 데이터가 많을수록 성능이 느리기 때문에, 조금의 오차가 허용된다면 별도 필드에 미리 계산된 값을 저장해두는 것이 낫다.
{
movie_id: 1,
title: "Star Wars",
total_viewers: 9500000, // 미리 계산해서 저장
screenings: [...]
}5. Bucket 패턴
하나의 필드를 기준으로 Document를 묶는 패턴이다. 실시간으로 데이터가 들어오는 시계열 데이터에 특히 적합하다.
// Before: 측정값마다 Document 하나
{ sensor_id: 12345, timestamp: ISODate("2019-01-31T10:00:00.000Z"), temperature: 40 }
{ sensor_id: 12345, timestamp: ISODate("2019-01-31T10:01:00.000Z"), temperature: 40 }
{ sensor_id: 12345, timestamp: ISODate("2019-01-31T10:02:00.000Z"), temperature: 41 }// After: Bucket 패턴 적용
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{ timestamp: ISODate("2019-01-31T10:00:00.000Z"), temperature: 40 },
{ timestamp: ISODate("2019-01-31T10:01:00.000Z"), temperature: 40 },
// ...
{ timestamp: ISODate("2019-01-31T10:42:00.000Z"), temperature: 42 }
],
transaction_count: 42,
sum_temperature: 2413
}- ✅ 필드 추가/삭제에 용이하고 인덱스 크기 절약 가능
- ⚠️ BSON 크기 제한(16MB)을 넘지 않도록
start_date,end_date로 범위를 제한하는 것이 좋음
6. Schema Versioning 패턴
Document에 버전 정보를 기록하는 패턴이다. 서비스를 운영하다 보면 스키마가 바뀌는 경우가 생기는데, 이 패턴을 쓰면 기존 데이터를 급하게 마이그레이션하지 않아도 된다.
// v1 Document
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}
// v2 Document (Schema Versioning 적용)
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}schema_version 필드를 조건으로 넣어 조회하면 충돌 없이 서비스를 운영할 수 있다. 우선 이렇게 해결해두고, 천천히 마이그레이션을 진행하면 된다.
마치며
Extended Reference, Subset, Computed 패턴은 실무에서 자주 등장하므로 잘 숙지해두자.
