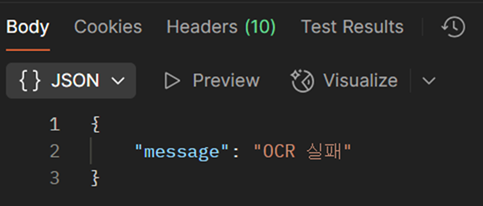
CNN 기반 OCR 라이브러리는 Docker 빌드 타임이 너무 오래 걸려 사용할 수 없다. 반면 용량이 가벼운 Tesseact는 인식률이 떨어진다. 어떻게 할까?
배경
‘돈쭐’(GitHub)은 사용자 참여를 기반으로 한 착한 소비 인증 플랫폼 웹서비스로, 선한 영향력을 가진 ‘착한 가게’들을 발굴하고 응원하는 데 초점을 맞춘다. 사용자는 직접 가게에 방문하고 영수증을 인증함으로써 선행 소비를 기록하며, 이를 통해 가게를 홍보하고 포인트를 적립하여 기부함으로써 사회적 가치에 기여할 수 있도록 설계되었다.
요구 사항
사용자는 가게 후기를 작성하기 위해 카메라를 통해 영수증 사진을 촬영해 서버로 전송한다. 서버는 사진에서 결제일시와 사업자번호 정보를 추출한 다음, '도용 방지를 위해 3일 이내에 소비한 영수증으로만 인증 가능', '중복 제보 방지를 위해 한 가게는 30일마다 인증 가능' 등 비즈니스 로직 제약사항에 적합한 영수증인지 확인한다.
제약 조건
EasyOCR 등 CNN(합성곱 신경망) 기반 라이브러리는 모델 자체의 용량이 수백 MB 이상으로 크고, PyTorch 같은 딥러닝 프레임워크에 대한 의존성도 포함하고 있어 Docker 이미지 빌드 시 용량과 시간이 지나치게 많이 소모되었다.
프로젝트 마감까지의 기한이 몇 주 정도로 여유롭지 않았고, 프론트와 백엔드 모두 로컬에서 빠르게 테스트하며 병렬적으로 작업해야 하는 상황이었기 때문에 무거운 이미지로 인해 빌드나 배포가 지연되는 문제는 치명적이었다.
따라서 가볍고 확장성이 높은 Tesseract를 선택하여 빌드에 성공했지만, 이번에는 인식률이 떨어진다는 문제가 있었다.
문제 해결
Tesseract의 낮은 인식률 문제를 해결하기 위해, 영상처리 수업에서 배운 기법을 응용해 직접 전처리 파이프라인을 설계했다.
- Upscaling
우선 저해상도 텍스트의 인식률을 개선하기 위해 upscale하였다. 단순히 크기만 키우는 방식은 글자를 뭉개지게 만들어 오히려 인식에 불리해질 수도 있겠다는 생각이 들었다. 어떤 보간(interpolation) 방식이 유리할지 비교해봤고, 그중 Bicubic Interpolation을 선택했다.
실제로 Bilinear로 키운 이미지에서는 글자가 뭉개지는 현상이 있었고, 주변 4x4 픽셀을 참고하는 Bicubic으로 보간한 이미지에서는 글자가 더 부드럽고 선명하게 보존되었다. 연산 비용이 더 많이 들지만 유의미한 정도는 아니었다.
- Grayscaling

OCR에 색상값은 불필요하고, 또한 어떤 영상처리 기법은 Grayscale 또는 Binary 이미지 전용으로 설계되어 있어, 컬러 이미지의 경우 기준값 설정이 어렵고 결국 결과가 불안정해질 수 있다는 문제가 있었다.
따라서 grayscaling을 통해 색상 정보를 제거하여 연산 비용을 줄였다.
- Otsu Thresholding

Tesseract가 글자와 배경을 더 명확히 구분할 수 있게 해주기 위해 Otsu Thresholding을 사용하였다. 원본 영수증 이미지들은 조명, 인쇄 상태, 촬영 각도 등에 따라 밝기나 대비가 제각각이었고, 이런 상황에서 고정된 임계값으로 이진화를 시도하면 어떤 이미지에선 글자가 날아가고, 어떤 이미지에선 배경 노이즈까지 글자로 인식되는 문제가 생겼다. 그래서 이미지 히스토그램을 분석해서 최적의 임계값을 자동으로 계산해주는 Otsu 알고리즘을 사용했다.
Otsu는 intra-class variance를 최소화하는 이진 임계값을 자동 계산하는 방식으로, 이미지의 밝기 분포에 따라 동적으로 threshold를 설정한다. 이를 통해 Tesseract가 인식해야 할 텍스트 경계를 보다 뚜렷하게 만들었고, 글자 윤곽이 부정확한 이미지도 어느 정도 정리되었다.
- Morphological Opening

여전히 작은 점이 노이즈로 남아 있어 이를 정리하기 위해 Morphological Opening을 적용했다. 침식(Erosion)과 팽창(Dilation)을 순서대로 적용하는 연산인데, 먼저 침식 단계에서는 글자보다 작은 크기의 노이즈나 점들이 제거된다. 이 과정에서 글자의 윤곽도 일부 깎이는데, 이후 진행되는 팽창 단계에서 깎인 부분을 다시 복원한다.
이 과정을 통해 배경에 흩어져 있는 잡음은 효과적으로 제거되면서도, 글자의 형태는 무너뜨리지 않고 되살릴 수 있었다. 특히 영수증처럼 저해상도에 글자 간격도 좁은 이미지에서는 단순한 필터링보다 이런 형태 기반 연산이 더 안정적인 결과를 주었고 덕분에 Tesseract가 더 깔끔한 입력을 받아서 인식률이 눈에 띄게 상승했다.
Otsu가 노이즈에 민감한데 왜 Opening을 먼저 적용하지 않았냐는 피드백이 있었다. Morphological Opening은 Binary 이미지에만 적용할 수 있는데, Grayscale 상태에선 침식/팽창 연산이 제대로 적용되지 않고, 오히려 침식 과정에서 글자가 깨질 위험이 있었다. 따라서 먼저 Otsu로 배경과 문자를 이진화해서 대비를 확실히 만든 후에 노이즈를 제거하였다.
회고
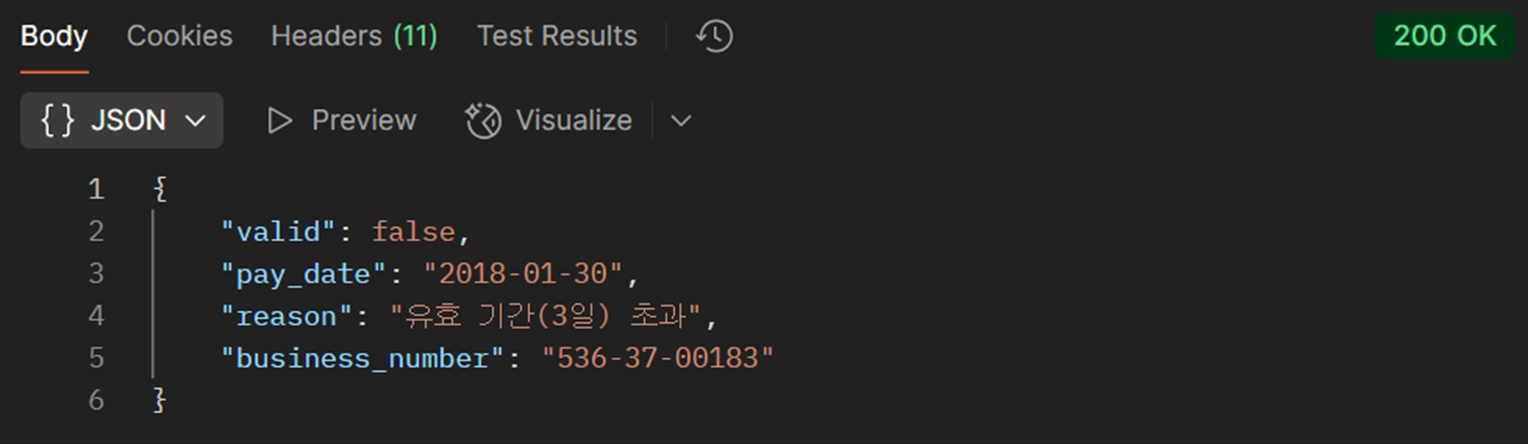
Tesseract는 성능이 가장 좋은 옵션은 아니었지만, 우리가 가진 시간적/환경적 제약을 고려했을 때 최선의 선택이었다. OCR 인식률이 낮다는 문제가 있었지만, 영상처리 기반 전처리를 통해 내부 테스트셋(20건) 기준 추출 성공률이 55%에서 80%로 상승했으며, 실제 테스트 이미지 대부분에서 날짜와 사업자번호를 안정적으로 추출할 수 있었다.
이번 과정을 통해, 기술 선택은 성능뿐 아니라 개발 효율, 유지보수성, 팀 환경 등 다양한 요소를 함께 고려해야 함을 깨달았다. 특히, 영상처리를 활용한 OCR 성능 개선은 단순 기술 적용을 넘어 시스템 전반의 트레이드오프를 조율하는 경험이었기에 의미가 깊었다.
