Software Testing
Software Testing의 목적
소프트웨어 테스팅은 소프트웨어의 결함이 존재함을 보이는 과정이다. 그래서 쉽게 말하면, 현재 소프트웨어에 존재하는 결함이나 버그를 찾는 것이 소프트웨어 테스팅의 목적이다.
결함(Defect)

실패(Failure)
예상했던 결과와 다르게 나온다던가, 프로그램 성능이 계획했던 것보다 너무 느리다던가 하는 것들이 Failure이다.
오류(Error)
오류는 우리가 프로그래밍하면서 겪어봐서 알겠지만, 프로그램 내부 상태의 부적절함으로 인해 발생한다. 그래서 오류가 발생하면 프로그램 내부에서 발생한 문제이기 때문에, 반드시 결함으로 이어지지 않기도 해서 발견하기가 어려운 경우도 있다. 오류는 프로그램의 결점(Fault)에 의해 발생한다.
결점(Fault)
버그라고도 불리는 결점은 정적인 형태의 결함으로, 코드 상의 문제에서 발생한다.
결점 또한 마찬가지로 반드시 오류나 실패를 야기시키지는 않는다. 오류나 실패가 발생하지 않지만 버그가 존재할 수 있다는 말이다.
소프트웨어 테스팅이 어려운 이유
1. test input이 일단 버그가 발생하는 코드 라인까지 도달해야한다.
2. 버그라인에 도달하더라도, 버그가 반드시 에러를 발생시킨다는 보장이 없다.
3. 에러가 발생하더라도, 에러가 반드시 실패를 보여준다는 보장이 없다.
Exhaustive Testing and Random Testing
Exhaustive Testing은 랜덤 값에 의해 생성되는 모든 조합의 경우의 수를 전부 고려하여 테스팅을 진행하는 기법이다. 이 테스팅을 통해 절대적으로 이 프로그램의 결함을 밝혀낼 수 있다고는 하지만, 시간도 오래걸리고, 복잡한 로직에서는 어마어마한 비용이 소요된다.
Random Testing이 그 예시인데, Random Testing은 임의의 독립적인 입력을 생성하여 프로그램을 테스트하는 블랙박스 소프트웨어 테스트 기술이다. Exhaustive Testing과 같이 사실 이 방법으로 테스팅을 진행하면, 실질적으로 효율성이 극도로 떨어지게 된다.
그래서 소프트웨어 공학에서는 소프트웨어 테스팅을 위한 효율적인 기준을 마련했다.
Code Coverage
Coverage Metrics
Coverage Metrics의 기본 출발점은
"프로그램의 더 많은 부분을 cover할 수록, 프로그램에서 버그를 찾기가 더 수월해진다."
에서 출발한다. 즉, 얼마나 이 프로그램이 가질 수 있는 경우의 수를 잘 충족시켜서 테스트를 진행하는가에 대한 이야기이다.
Code Coverage
Computer Science에서 Code Coverage(Test Coverage)는 프로그램의 소스코드가 특정 테스트 케이스 집합에서 실행될때, 이 테스트 케이스들이 얼마나 이 프로그램이 실행할 수 있는 경우의 수를 충족시키는지를 나타내는 지표이다. 그래서 단위는 퍼센트(%)를 사용한다.
Code Coverage가 중요한 이유는 테스트 코드를 작성하는데 필요한 기준이기 때문이다. 테스트 코드는 최대한 이 코드에서 발생할 수 있는 시나리오를 고려해야하는데, 그것을 효율적으로 가능하게 해주는 기준을 잡을 때 Code Coverage가 사용된다. 즉, 코드 커버리지는 Human Error를 최소화시켜주는 지표라고 할 수 있다.
Various Coverage Metrics
Code Coverage를 측정하는 측정 수단은 내가 듣는 수업에서는 5가지로 배웠다.
- Line Coverage
- Statement Coverage
- Branch Coverage
- Condition Coverage
- Path Coverage
Line Coverage
Line Coverage는 가장 쉽게 이해할 수 있는 Code Coverage 방식이다.
말 그대로 테스트 케이스가 실행되었을 때, 작동하는 소스 코드 Line의 비율이다.
int x = 10; if (z++ < x) y = x + z;위 코드와 같은 경우는 1개의 Line이 있다.
하지만, Line이 기준이기 때문에, 코딩 스타일과 포맷에 따라서 제대로 Code Coverage를 판단하지 못할 가능성이 높다.
같은 코드라도
int x = 10;
if (z++ < x) y = x + z;이렇게 하면 2 Lines가 되기 때문이다.
1 Line 예시에서는 만약 조건문이 테스트 케이스에 의해 실행되지 않더라도,
int x = 10;위 코드가 실행되기 때문에, Line 1은 실행된 것이라 Line Coverage는 100%가 된다.
하지만 같은 조건에서 2 Lines 예시는 50%가 된다. Line 2는 실행되지 않기 때문이다.
Statement Coverage
Statement Coverage는 Line Coverage와 비슷하지만, Line이 아닌 Statement로 판단한다.
그래서 아까와 같은 코드가 있다면,
int x = 10; if (z++ < x) y = x + z;Statement Coverage에서 3개의 statement를 가지는 것으로 판단한다.
그래서 Statement는 테스트 케이스를 통해 작동되는 statement의 비율을 의미한다.
Branch Coverage(Decision Coverage)
Decision Coverage라고도 하는 Branch Coverage는 CFG(Control Flow Graph)를 그려야 이해할 수 있다.
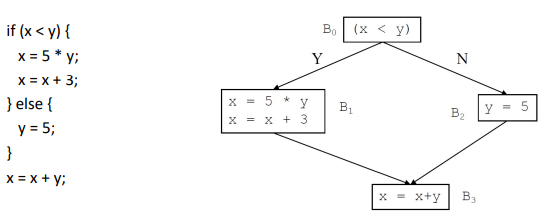
위 그래프가 CFG이다. 각각의 Node들을 basic block이라고 부르고, 그 Node들을 연결하는 선들을 Branch라고 부른다.
Branch Coverage는 총 Branch 개수에 대한 실행된 Branch의 개수의 비율이다.
Branch Coverage = (# of executed branches)/(total number of branches)
만약 test set이 {(x=1, y=2)}라면, 왼쪽 Flow로 진행되기 때문에, 50%의 Branch Coverage를 가지게 된다.
- Branch Coverage & Statement Coverage
여기서 잠시 Branch Coverage와 Statement Coverage에 대해 조금 더 생각해보자.
Branch Coverage와 Statement Coverage는 서로 어떤 관계를 갖고 있을까?
만약 같은 코드와 테스트 케이스에서 Statement Coverage가 100%를 가진다면, 그것이 Branch Coverage가 100%를 갖는 것을 보장할 수 있을까?
반대로 같은 코드와 테스트 케이스에서 Branch Coverage가 100%를 가진다면, 그것이 Statement Coverage가 100%임을 보장할 수 있을까?
아래 코드를 보자.
int absolute(int x) {
if (x < 0) x = -x;
return x;
}그리고 test set은 {x = -1} 이다.
자, 여기서 statement Coverage는 100%이다. test set에 의해 함수 absolute의 body 안에있는 모든 statement가 실행되기 때문이다.
그런데 Branch Coverage는 50%이다. 조건문 if(x<0)에서 2개의 Branch가 발생하는데, test set은 하나의 branch만 작동시키기 때문이다.
즉, statement Coverage가 100%임은 Branch Coverage가 100%임을 보장할 수 없고, 반대로 Branch Coverage가 100%임은 statement Coverage가 100%임을 보장할 수 있다. 모든 조건문의 True Branch와 False Branch를 모두 작동시킨다는 것은 어쨌든 모든 조건문이 작동한다는 것이고, 나머지는 당연하게도 조건 없이 작동하기 때문에, 모든 Statement가 실행됨을 보장할 수 있는 것이다.
Branch Coverage > Statement Coverage, Branch Coverage subsumes statement coverage
Branch Coverage의 한계
Branch Coverage는 단순히 조건문의 Truth Value에 따라 나누어지는 Branch의 개수가 Code Coverage의 기준이 된다. 그 말은 만약 조건문에 들어가는 조건의 갯수나 상태에 따라, Bug가 발생해도 찾을 수 없고, Branch Coverage가 100%라도 결함이 발생할 수 있다는 의미가 된다.
간단한 예시를 하나 들어보려고 한다.
if (C1 && (C2 || fun())
statement1;
else
statement2;위와 같은 코드에서 C, C++, Java와 같은 프로그래밍 언어에서는 short-circuiting이라는 개념이 적용된다. 위와 같이, 조건문에서 &&와 같은 연산자를 사용해 AND 조건을 걸어줄때를 가정해보자.
A && B
위 조건문에서 만약 A가 False라면 B가 True라도, 결과는 False가 된다.
그래서 short-circuiting은 이런 상황에서 A가 False면 그 뒤의 조건을 확인하지 않고 False를 결과로 반환해버린다.
||와 같은 OR 연산자도 마찬가지로
A || B
일때, A가 True이면 볼 것도 없이 결과는 True이기 때문에, B를 실행시키지 않는다.

이때 다시 예시 코드로 돌아가보면, {(C1: true, C2: true), (C1: false)}와 같은 테스트 케이스만 있어도, branch Coverage는 100%가 된다. True와 False 결과를 모두 가질 수 있기 때문이다. 하지만 이 상황에서 fun()은 실행 자체가 되지 않는다.
이때 fun()에 오류가 있어도 현재 테스트 케이스로는 절대 fun()의 결함을 발견할 수가 없다. Branch Coverage가 100%인데도 말이다.
그래서 더 높은 수준의 Code Coverage를 원한다면 더 디테일한 기준을 가진 Code Coverage Metrics가 필요하다.
Condition Coverage
Condition Coverage는 이제 Branch Coverage와 다르게, 조건이 기준이다. 즉, 조건문에서 참 거짓으로 판단되는 각각의 Truth value들이 판단의 타겟이 된다.
Branch Coverage에서 봤던 예제를 다시보자.
if (C1 && (C2 || fun())
statement1;
else
statement2;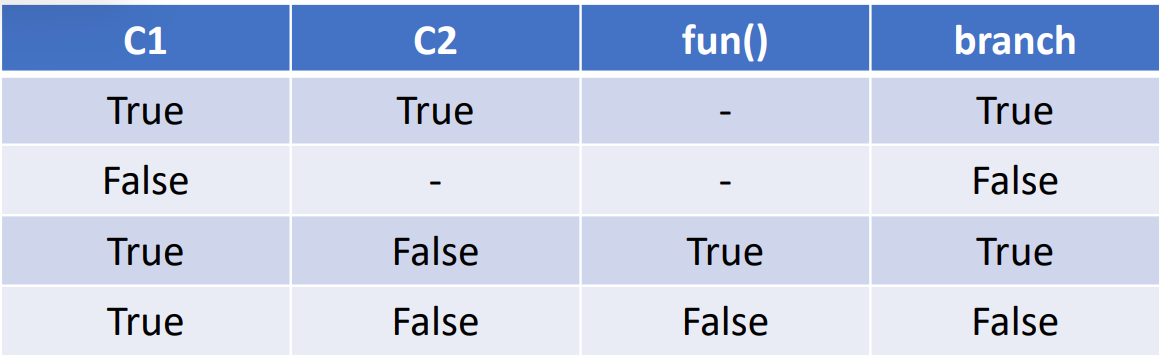
위 표처럼 아까와 같은 예제이지만, Coverage를 판단하는 방식이 다르다.
Condition Coverage에서는 각 피연산자(ex. C1, C2, fun())가 True와 False로 한번씩 실행되었는지의 비율을 보는 것이기 때문에, 조건문의 결과에 중점을 두는 Branch Coverage와 다르다.
Condition Coverage vs Branch Coverage
그렇다면 Condition Coverage는 Branch Coverage의 문제를 해결했으니, 만약 Condition Coverage가 100%라면 Branch Coverage도 100%를 달성할 수 있을까?
정답을 바로 이야기하자면, 아니다. 그럴수도 있지만, 아닐 수도 있다. 위 예시의 경우에는 Condition Coverage와 Branch Coverage가 모두 100%이다. 하지만, 아래 예시를 보자.
boolean f(boolean e) {
return false;
}
if (f(a & b)) {
...
}자 이 경우에는 테스트 케이스로 {(a:True, b:False), (a: False, b: True)}를 생각해볼 수 있다.
이 경우, a와 b 두 피연산자가 각각 True와 False값을 한번씩 가졌으니, Condition Coverage는 100%이다. 하지만 f(A & B)가 작동하게 되면, 무조건 결과로 False를 리턴하게 되어있으므로, Branch Coverage는 50%가 된다. 그래서 Condition Coverage와 Branch Coverage는 서로 포함되는 관계가 아니다.
Multiple Condition Coverage
분명 방금 Condition Coverage의 정의에 대해 이해했다면, 이렇게 생각을 했을 것이다.
단순히 조건의 True False Value만 판단한다면, 조건들이 가질 수 있는 모든 조합을 고려할 수 없지 않나?
맞다. 그래서 모든 가능한 Truth 조합을 요구하는 Coverage인 Multiple Condition Coverage가 존재한다.
아래 코드를 보자
if (x < 0 | y < x) {
x = 5 * y;
x = x + 3;
}
x = x + y;여기에는 if(x<0 | y < x) 라는 조건문이 존재한다. 그리고 x<0과 y<x라는 두개의 조건이 있다. 이때 Multiple Condition Coverage를 고려하려면 테스트 케이스를 어떻게 작성해야할까?
바로 모든 조합의 조건을 테스트 케이스로 작성하는 것이다.
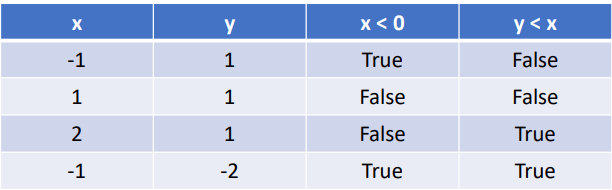
이렇게 하면 100%의 Multiple Condition Coverage를 달성할 수 있게된다.
하지만 여기서도 문제가 발생한다.
하나의 조건당 2개의 조합이 발생하는데, 2개의 조건이 있으면 4개의 조합, 3개의 조건이 있으면 8개의 조합으로, 조건이 많다면 테스트 케이스가 엄청나게 많아지게 된다.
과한 양의 테스트 케이스는 비용 문제를 야기시키고, 소프트웨어 공학은 이런 비용 문제를 해결하고 싶어한다.
Modified Condition/Decision Coverage(MC/DC)
그래서 이번에는 MC/DC를 설명하고자 한다.
MC/DC는 개별 조건식이 '다른 조건식의 영향을 받지 않고', 전체 조건식의 '결과'에 '독립'적으로 영향을 주는 테스트 케이스 도출 기법이다. 일반적으로 N개의 조건식이 있다면, N+1개의 테스트 케이스가 생성된다.
아래 표를 보자.
조건문은 if (A & B & C) 이다.
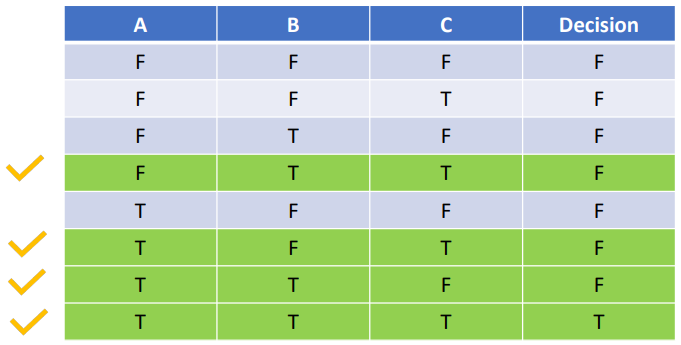
원래 Multiple Condition Coverage를 100% 충족시키려면, 총 8개의 테스트 케이스가 필요하다. 하지만 위 MC/DC의 결과를 보면 4개의 테스트 케이스면 충분하다고 말한다.
저 4개의 테스트 케이스를 도출해내는 방법은 어렵지 않다.
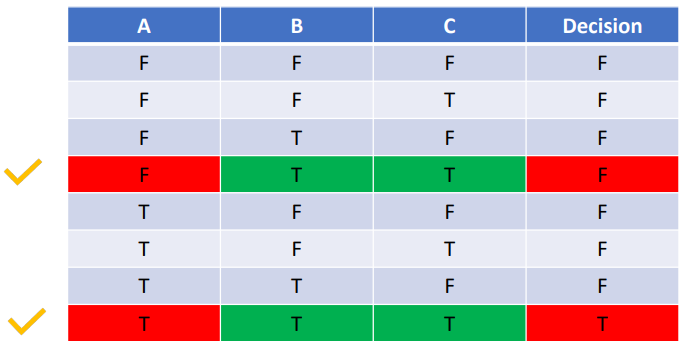
위 표에서처럼,
1. 다른 조건식의 영향을 받지 않고,
2. 결과에 독립적으로 영향을 주는
3. 개별 조건식의 Truth Value를 찾아서
4. MC/DC의 테스트 케이스로 선정한다.
이렇게 각 개별 조건식에 대해 위 과정을 수행하면 4개의 테스트 케이스를 도출할 수 있다.
핵심은 다른 조건식의 영향을 받지 않으면서 결과에 독립적으로 영향, 즉 결과값을 T/F로 다르게 낼 수 있는 테스트 케이스를 찾아내는 것이다.
좀 더 쉽게 말하면 예를 들어 하나의 개별 조건식을 선정했다면, 결과를 T/F로 구분하는 두개의 테스트 케이스가 만들어 질 것이다. 이때, 이 테스트 케이스는 두개를 서로 비교해봤을 때 우리가 선정한 개별 조건식 외에는 다른게 없어야 한다. 그래야 결과에 독립적으로 영향을 주는 개별 조건식을 설명하는 것이기 때문이다.
연습삼아 아래 문제를 풀어보는 것을 추천한다.
왜 저 4개의 테스트 케이스가 MC/DC가 되는지, 그것을 어떻게 하면 찾을 수 있을지 조금만 고민하고 직접 해보면 알 수 있다.
if(A | (B && C))
if(A || (B && C))

