Longest Common Subsequence(최장 공통 부분수열)과 Longest Common Substring(최장 공통 문자열) 에 대해 설명하세요
Keyword
부분 수열, 불연속, 문자열, 연속, DP, 2차원 배열, 점화식, 문자간 비교, 왼쪽 대각
Script
먼저 subsequence와 substring의 차이를 말씀드리면, subsequence는 부분수열로, 연속되지 않은 문자열도 고려하지만 substring은 문자열로, 연속된 문자열을 의미합니다.
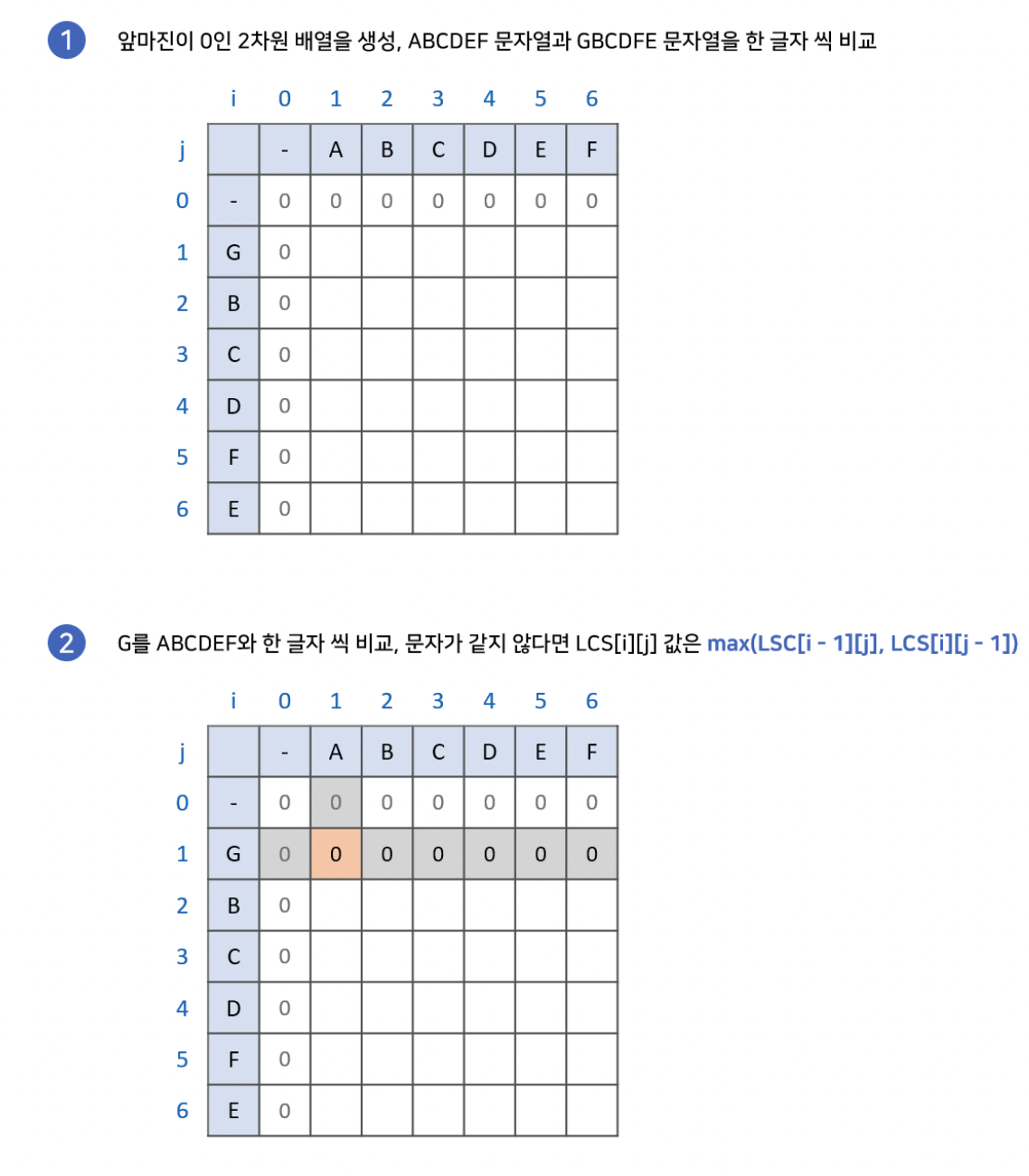
LCS 문제는 DP를 이용해서 빠르게 해결할 수 있습니다. 두 경우 모두, 2차원 배열에 각 축을 비교 대상인 문자열을 매핑하고 0으로 초기화 합니다. 그리고 점화식과 문자간의 비교를 이용해서 배열을 채워나갑니다.
먼저 더 간단한 알고리즘을 가진 최장 공통 문자열에 대해 이야기하자면, 만약 배열의 특정 지점에서 각 축의 문자가 같다면, 왼쪽 대각의 수에 1을 더한 값을 해당 지점에 넣어주는 점화식을 사용합니다. 이 방식으로 배열의 모든 지점을 탐색하고, 가장 큰 수를 가지는 지점으로부터 왼쪽 대각선을 따라가며 최장 문자열을 찾습니다.
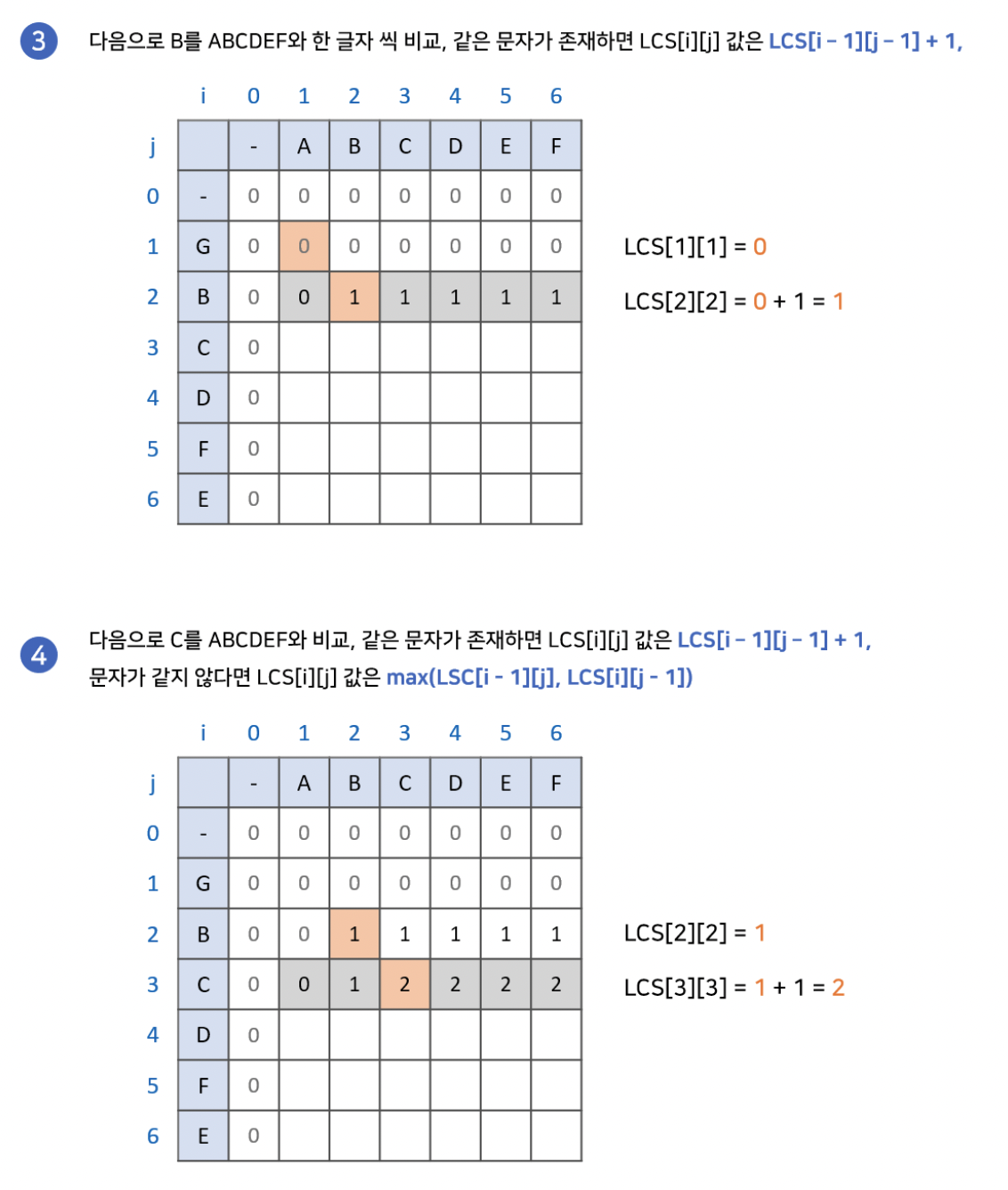
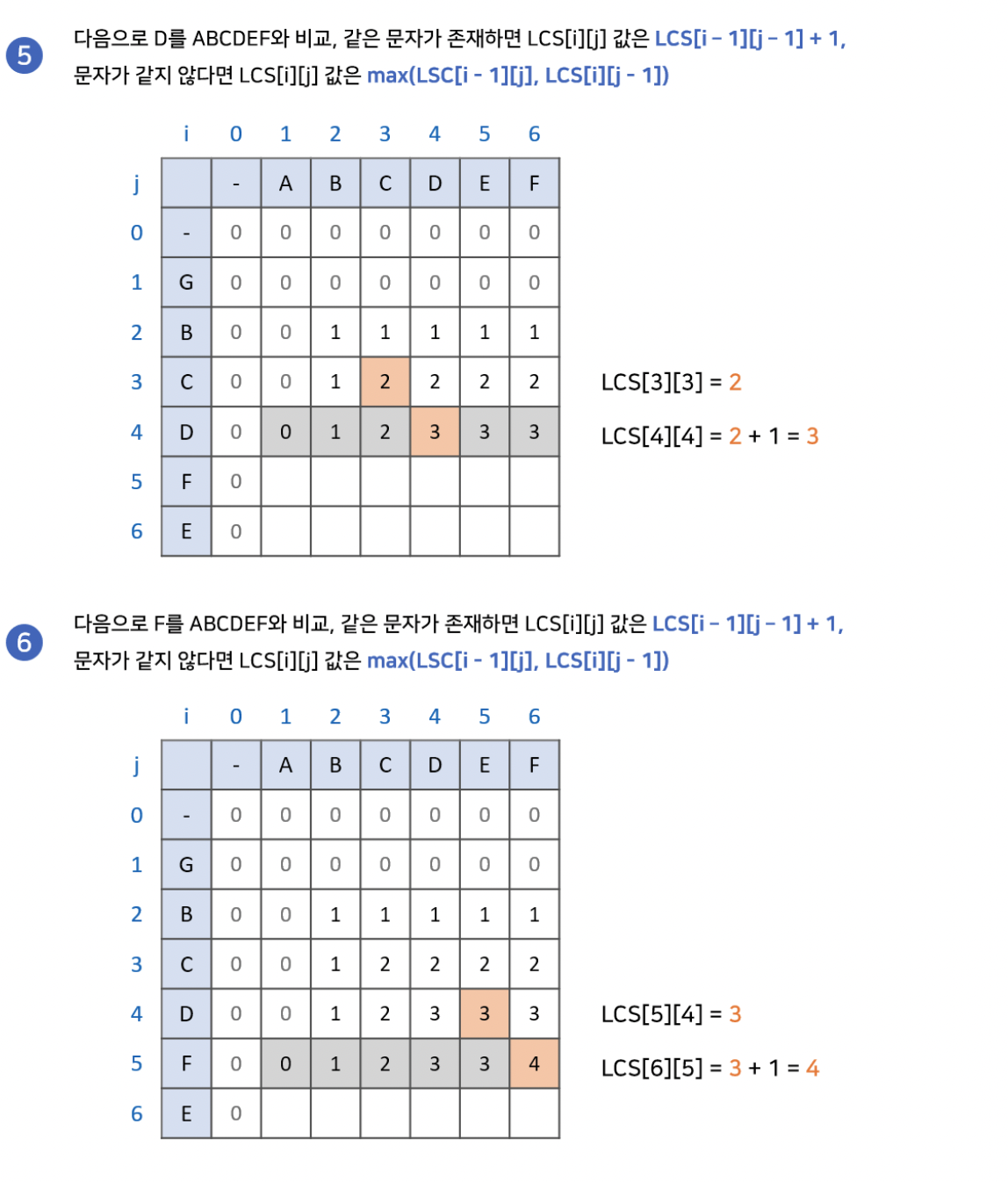
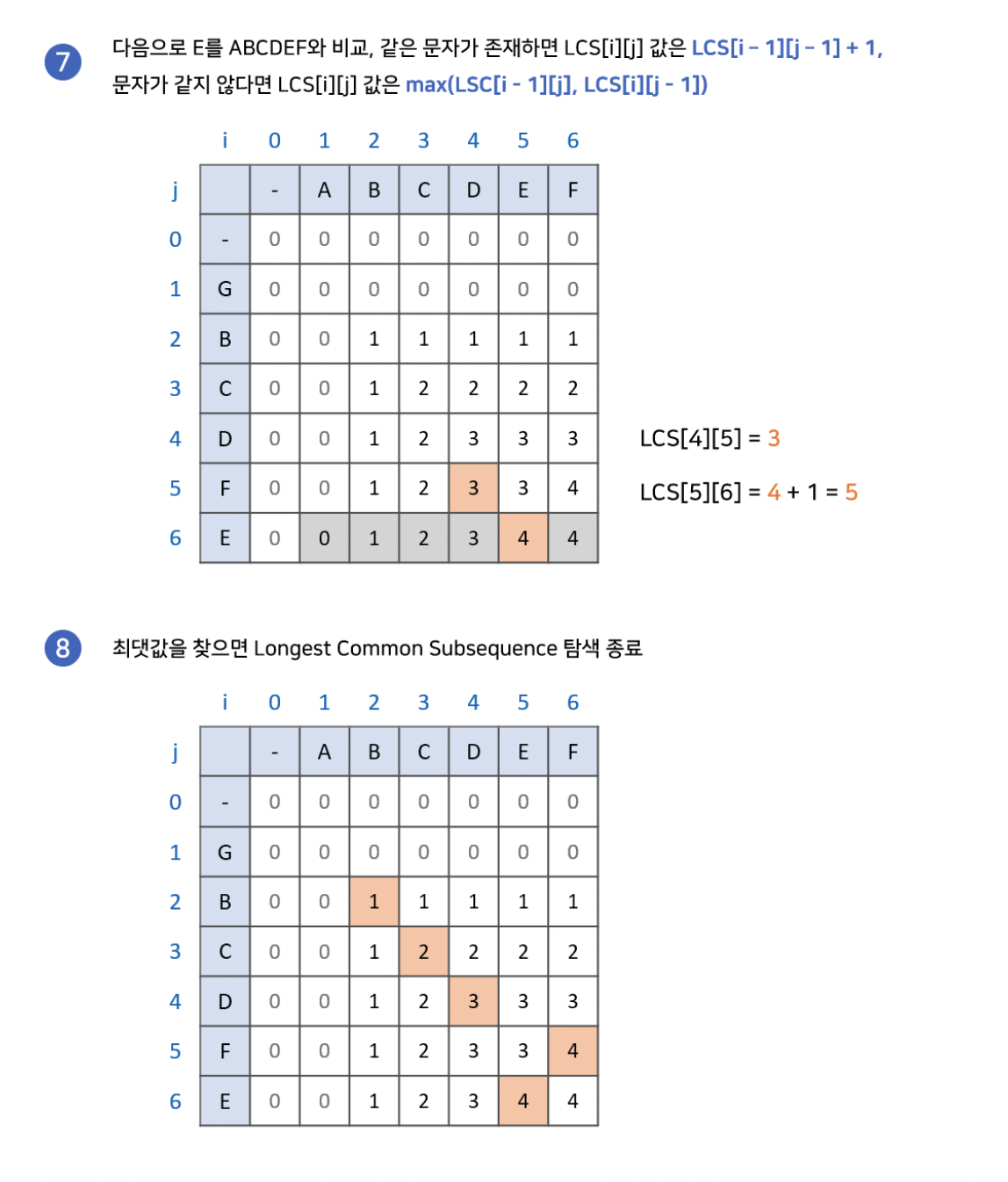
최장 공통 부분수열은 비슷하지만, 부분 수열의 특징인 "불연속 허용"을 반영하기 위해서 조금 다른 점화식을 사용합니다. 먼저 만약 특정 지점의 각 축의 문자가 같다면, 최장 공통 문자열 알고리즘과 같이 왼쪽 대각선에서 1을 더한 값을 넣어줍니다. 그렇지 않다면, 왼쪽과 위쪽 중 더 큰 값을 넣어줍니다. 이렇게 배열을 완성하고 최장 공통 부분수열을 찾을 수 있습니다.
2차원 배열의 모든 부분을 탐색하기 때문에, N을 첫번째 문자열의 길이, M을 두번째 문자열의 길이라고 할때 O(NM)의 시간복잡도를 가집니다.
Additional
Longest Common Substring(최장 공통 문자열)
점화식
if i == 0 or j == 0: # 마진 설정
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = 0그림

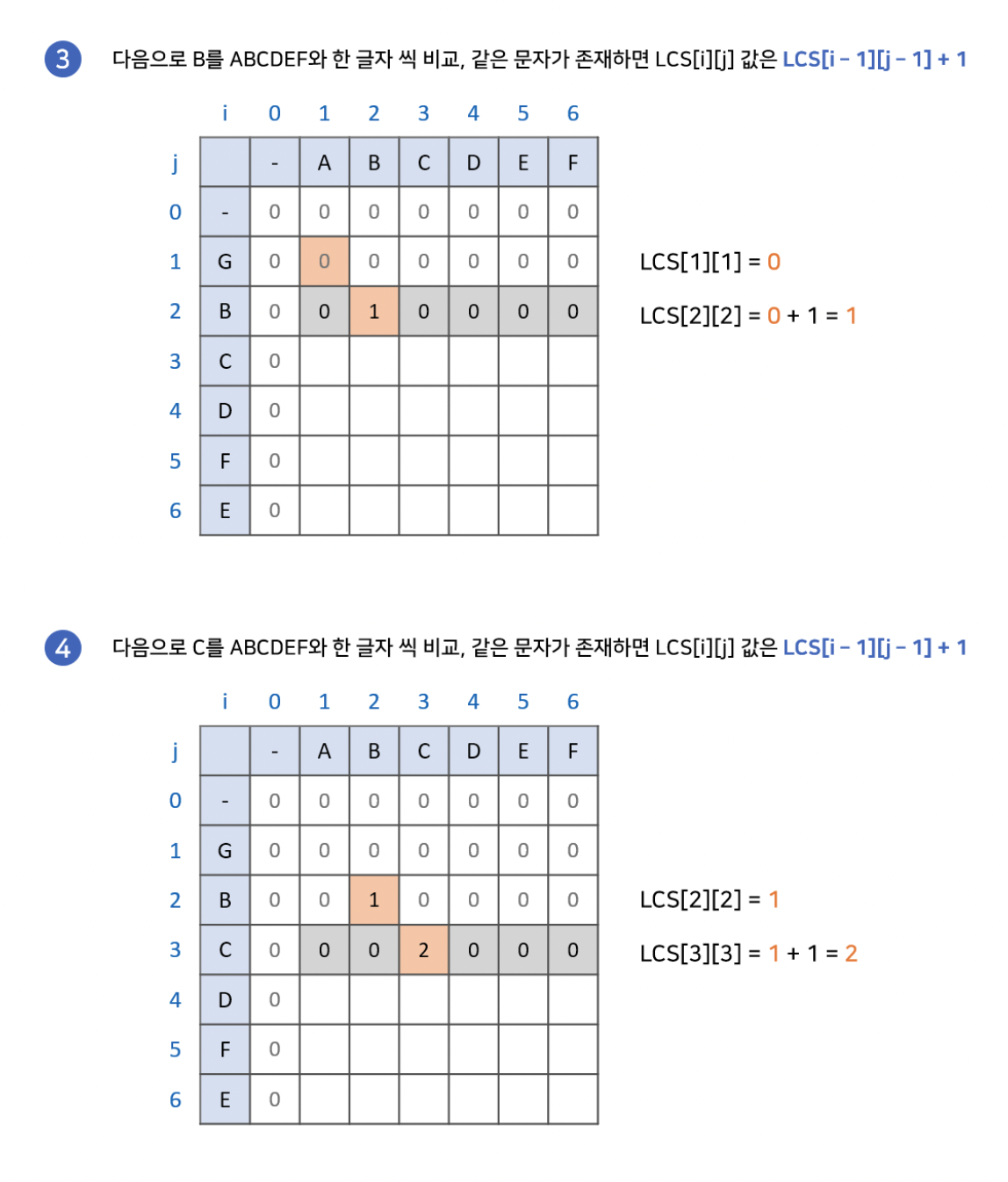
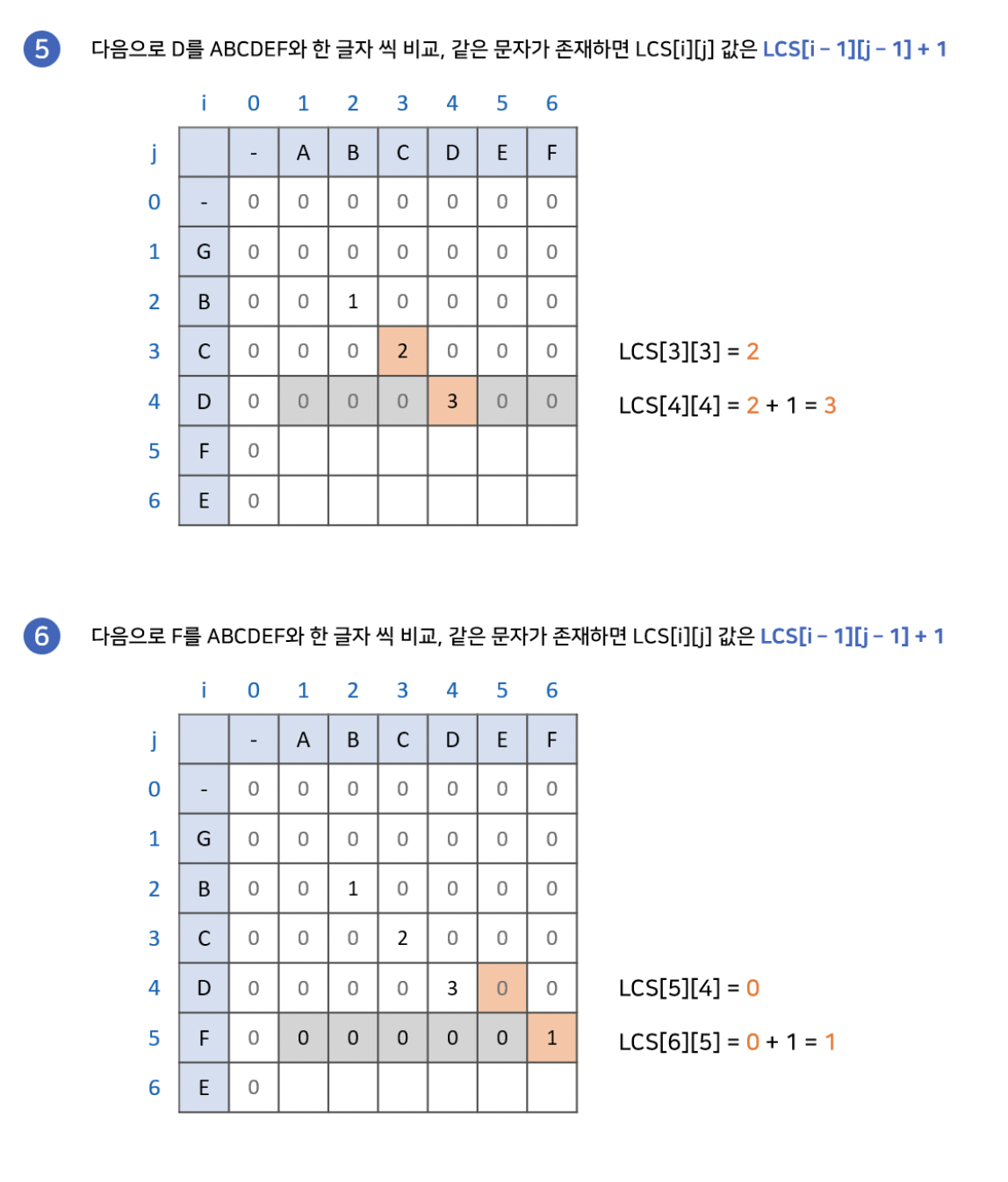
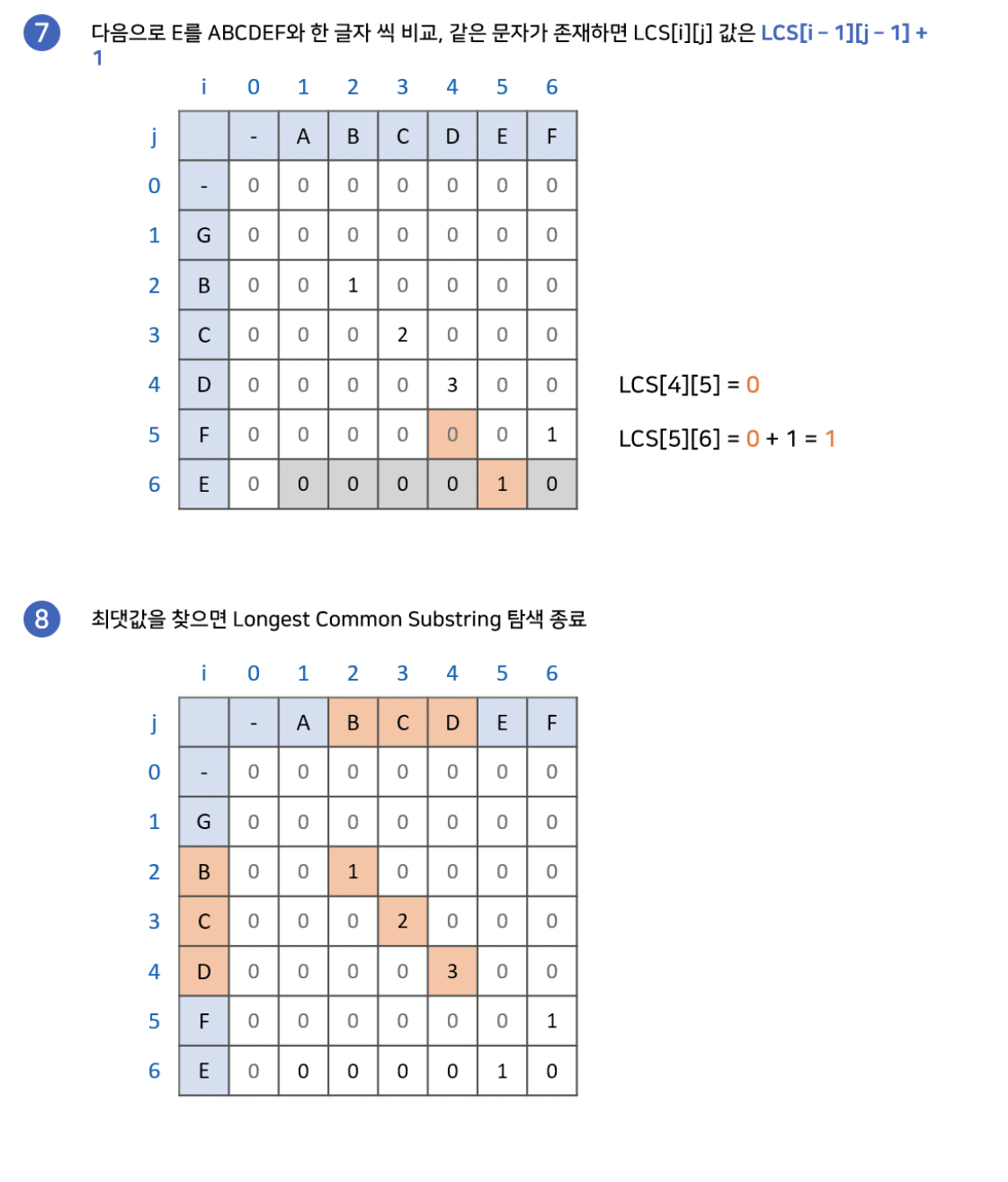
Longest Common Subsequence(최장 공통 부분수열)
점화식
if i == 0 or j == 0: # 마진 설정
LCS[i][j] = 0
elif string_A[i] == string_B[j]:
LCS[i][j] = LCS[i - 1][j - 1] + 1
else:
LCS[i][j] = max(LCS[i - 1][j], LCS[i][j - 1])그림