- 정규식(RE)은 파이썬에 내장된 매우 작고 고도로 특수화된 프로그래밍 언어
- 문자열 집합에 대한 규칙을 지정
즉 정규 표현식이 [abc]라면 이 표현식의 의미는 "a, b, c 중 한 개의 문자와 매치 "를 의미. 예시로 문자열 "a", "before", "dude"가 정규식 [abc]와 어떻게 매치되는지 확인
"a"는 정규식과 일치하는 문자인 "a"가 있으므로 매치
"before"는 정규식과 일치하는 문자인 "b"가 있으므로 매치
"dude"는 정규식과 일치하는 문자인 a, b, c 중 어느 하나도 포함하고 있지 않으므로 매치되지 않음
메타 문자 (meta characters)
- 그 문자가 가진 뜻이 아닌 특별한 용도로 사용하는 문자
. ^ $ * + ? { } [ ] \ | ( )
[]안의 두 문자 사이에 -을 사용하면 두 문자 사이의 범위를 의미
[a-c] = [abc]
[0-5] = [012345] 참고!
Row String : escape문자에 영향을 받지 않고 그대로 표시하는 방법
raw string을 사용하면 escape문(\b , \s ,\n ...)이 동작되지 않고, 있는 그대로 출력된다. 사용 방법은 출력할 문자열앞에 r을 붙여주면 된다.
print("골뱅이는 escape 시퀀스 때문에 삭제되겠지. @\b ")
print(r"골뱅이는 escape 시퀀스 때문에 삭제되겠지. @\b ")
<<< 골뱅이는 escape 시퀀스 때문에 삭제되겠지.
<<< 골뱅이는 escape 시퀀스 때문에 삭제되겠지. @\b\ 가 많이 들어가는 파일 경로(ex : C:\programs\Test\Bin') , 또는 변형되면 안되는 중요한 정보에 사용된다.
1. |
- or과 동일한 의미 A|B 로써 A또는 B
2. ^
- 문자열의 맨 처음과 일치.
# 정규식과 비교문자열을 한번에 쓸수 있다.
>>> print(re.search('^Life', 'Life is too short'))
<re.Match object; span=(0, 4), match='Life'>
>>> print(re.search('^Life', 'My Life'))
None3. $
- ^와 반대 경우로 $는 문자열의 끝과 매치함을 의미
>>> print(re.search('short$', 'Life is too short'))
<re.Match object; span=(12, 17), match='short'>
>>> print(re.search('short$', 'Life is too short, you need python'))
None4. \A
- \A는 문자열의 처음과 매치됨을 의미한다. ^ 메타 문자와 동일한 의미이지만 re.MULTILINE 옵션을 사용할 경우에는 다르게 해석된다. re.MULTILINE 옵션을 사용할 경우 ^은 각 줄의 문자열의 처음과 매치되지만 \A는 줄과 상관없이 전체 문자열의 처음하고만 매치된다.
5. \Z
- \Z는 문자열의 끝과 매치됨을 의미한다. 이것 역시 \A와 동일하게 re.MULTILINE 옵션을 사용할 경우 $ 메타 문자와는 달리 전체 문자열의 끝과 매치된다.
6. \b
7. \B
Dot(.)
정규 표현식의 Dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미
a.b "a + 모든 문자 + b"
즉 a와 b 문자 사이 어떤 문자가 들어가도 모두 매치가 된다.
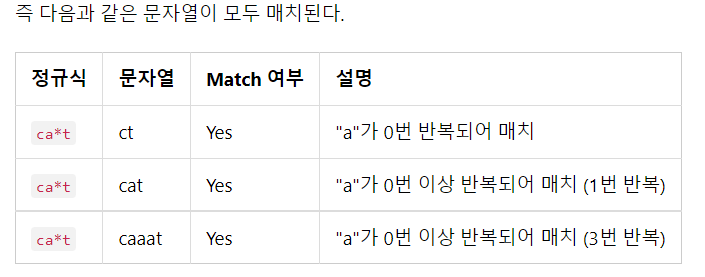
반복 (*)
cat
# '' * 바로 앞에 있는 문자 a가 0번~무한대 반복 될 수 있다.
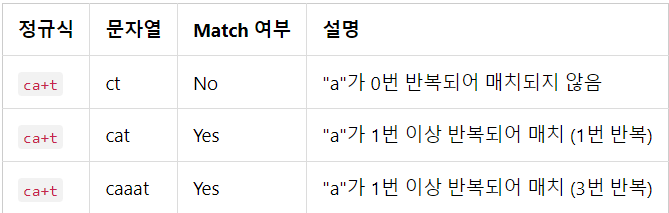
반복(+)
- 최소 1번 이상 반복될 때 사용된다.
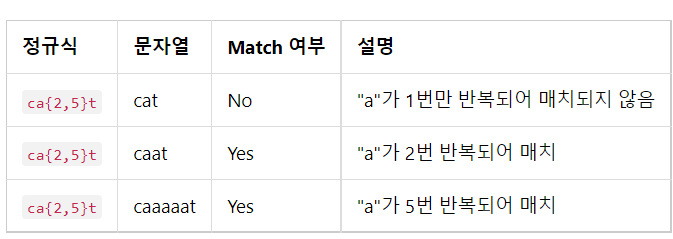
반복회수 제한
예를 들어 반복횟수를 1~3회로 제한하고 싶은 경우 {} 메타 문자를 이용하여 반복 횟수를 고정할 수 있다. {m, n}으로 작성 시 m부터 n 까지 매치가능.또는 m , n을 생략하여 사용할 수 도 있다. (최소 몇 이상 , 몇 이하 표현이 가능)
?
ab?c
b가 있어도 되고 없어도 되는 것들을 매치
파이썬 모듈(re)
import re
p = re.compile('ab*')
# re.compile을 이용하여 정규 표현식을 컴파일 한다. (찾고자 하는 정규식 선언)정규식을 이용한 문자열 검색
1) match() : 문자열의 처음부터 정규식가 매치되는지 확인(match 객체 반환)
2) search() : 문자열 전체를 검색하여 정규식과 매치되는지 확인(match 객체 반환)
3) findall() : 정규식과 매치되는 모든 문자열을 리스트로 반환
4) finditer() : 정규식과 매치되는 모든 문자열을 반복 가능한 객체로 반환(반복가능한 match 객체 반환)
match, search는 정규식과 매치될 때는 match 객체를 돌려주고, 매치되지 않을 때는 None을 돌려준다.
match 예시
import re
p = re.compile('[a-z]+')
m = p.match("python")
print(m)
<<< re.Match object; span=(0, 6), match='python'>
m = p.match("3 python")
print(m)
<<< None
# 3 python 문자열은 처음에 나오는 문자 3이 정규식에 부합되지 않으므로 None을 돌려준다. search 예시
import re
p = re.compile('[a-z]+')
m = p.search("python")
print(m)
<<< re.Match object; span=(0, 6), match='python'>
m = p.match("3 python")
print(m)
<<< None
# 3 python의 첫번째 문자는 3이지만 search는 처음부터 검색하는 것이 아니라
# 문자열 전체를 검색하기 때문에 3 이후의 "python"문자열과 매치된다.findall
import re
p = re.compile('[a-z]+')
result = p.findall("life is too short")
print(result)
<<< ['life', 'is', 'too', 'short']
# 정규식과 매치를 해서 리스트로 반환한다. finditer
import re
p = re.compile('[a-z]+')
result = p.finditer("life is too short")
print(result)
<<< <callable_iterator object at 0x01F5E390>
for r in result: print(r)
...
<re.Match object; span=(0, 4), match='life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 17), match='short'>
# findall과 도일하지만 그 결과로 반복가능한 객체(iterator object)를 돌려준다. match 객체의 메서드
- match와 search 메서드로 수행한 결과로 돌려준 match 객체에 대한 메서드 확인
1) group() : 매치된 문자열을 돌려준다.
2) start() : 매치된 문자열의 시작 위치
3) end() : 매치된 문자열의 끝 위치
4) span() : 매치된 문자열의 (시작, 끝)에 해당되는 튜플을 준다.
import re
p = re.compile('[a-z]+')
m = p.match("python")
m.group()
<<< 'python'
m.start() # match 매서드로 수행했다면 , match 객체의 start는 항상 0
<<< 0
m.end()
<<< 6
m.span()
<<< (0, 6)import re
p = re.compile('[a-z]+')
m = p.search("3 python")
m.group()
<<< 'python'
m.start()
<<< 2
m.end()
<<< 8
m.span()
<<< (2, 8)컴파일 옵션
DOTALL , S
. 메타 문자는 줄바꿈 문자(\n)를 제외한 모든 문자와 매치된다. 만약 \n 문자도 포함하여 매치하고 싶다면 re.DOTALL 또는 re.S 옵션을 사용해 정규식을 컴파일하면 된다.
p = re.compile('a.b', re.DOTALL) # 또는 re.S
m = p.match('a\nb')
print(m)
<<< <re.Match object; span=(0, 3), match='a\nb'>참고 링크 : https://wikidocs.net/4308
