
SQL - (2)
VIEW
하나 이상의 테이블로부터 유도되어 만들어진 가상의 테이블. 쿼리를 간단하게 쓰기위해 생성한다.
- VIEW 생성
CFEATE VIEW [view 이름]
AS SELECT [포함시킬 컬럼]
FROM [테이블]
JOIN문- JOIN과의 차이점
VIEW는 실제 테이블처럼 데이터가 저장되는 것이 아니라 쿼리가 저장되는 것이라는 차이가 있다.
VIEW의 장점
- 특정 사용자에게 테이블의 필요한 부분만을 보여주는 기능
- 복잡한 쿼리를 단순화할 수 있음
- 쿼리 재사용 가능
VIEW의 단점
- 삽입, 삭제, 갱신 작업에 많은 제한 사항이 있다. (조건이 있음)
- 자신만의 인덱스를 가질 수 없다.
VIEW는 성능상 이점이 거의 없다. 단지 개발자의 편의(간단한 쿼리) 때문에 사용하는데, 쿼리에 변화를 줘야할 경우 등 오히려 사용하다 보면 더 번거로워 진다. 주로 스토어드 프로시져를 사용한다.
INDEX
DB 테이블에서 삽입, 수정, 삭제 기능의 성능을 포기하는 대신 데이터 읽기 속도를 높이는 자료구조로, B-Tree 방식의 인덱싱을 사용한다.
INDEX의 장점
- 불필요한 검색의 숫자를 줄여준다.
- 검색량 단축으로 인한 쿼리 부하를 줄여준다.
- 검색 속도가 매우 빨라진다.
INDEX의 단점
- 조회 성능은 높아지지만, 수정 삭제 삽입 성능은 낮아진다.
- INDEX도 데이터이기 때문에 약 10%에 해당하는 추가적인 공간 할당이 필요하다.
- INDEX 생성시 시간이 걸린다.
INDEX의 한계
- 제목, 내용을 검색할 때는 분명한 한계가 있다. 따라서 이 경우 Elastic Search를 사용한다.
INDEX를 사용하지 않으면?
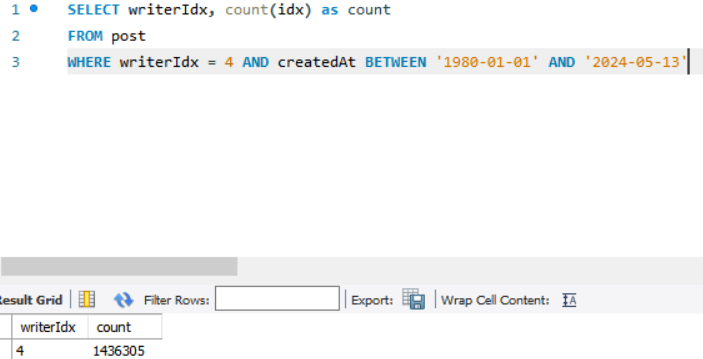
200만개의 샘플 데이터에서 위의 쿼리를 실행하면

위와같이 약 27초가 걸리는 모습을 볼 수 있다.
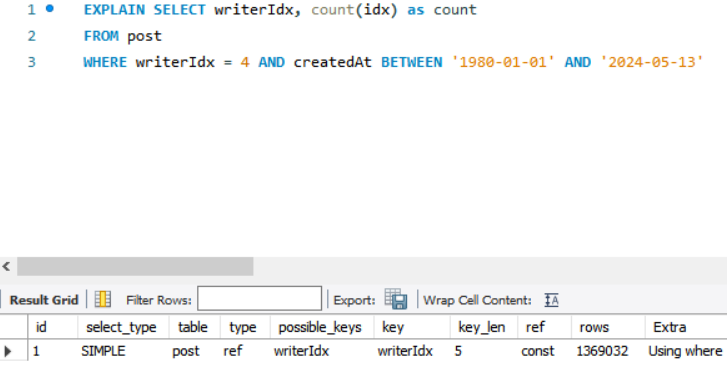
해당 쿼리의 체크항목 들은 EXPLAIN 키워드로 볼 수 있는데 다음과 같다.
SP(Stored Procedure)
SQL은 컴파일 언어이다
SQL문법으로 작성된 코드를 기계어 코드로 변경하고 변경된 코드를 실행한다.
따라서 작성된 SQL을 컴파일한 후 이를 실행하게 되는데, SP는 빈도수가 높은 사항에 대해 미리 컴파일을 해두고 필요할 때 마다 요청키로 바로 실행한다.
SP 문법
- SP 생성
DELIMITER $$ CREATE PROCEDURE SP이름 (IN 또는 OUT 속성) BEGIN [SP를 진행할 쿼리문] END $$ DELIMITER; - SP 사용
CALL SP이름; - 속성 입력 처리
DELIMITER $$ CREATE PROCEDURE SP이름 (IN userIdx INT) BEGIN SELECT * FROM member WHERE idx = userIdx; END $$ DELIMITER;
SP는 만들어 둔다고 해서 성능이 나빠지는 경우는 없기 때문에 SELECT문 사용시 거의 전부 사용한다.
SQL 성능개선
5명의 멤버가 각각 아래의 해당하는 갯수만큼 게시글을 작성했을 때, kang, kim, park 3사람이 작성한 게시글 수와 사용자명을 조회하는 쿼리의 성능을 개선해보자
- 20만 (kang)
- 20만 (kim)
- 20만 (lee)
- 200만 (park)
- 20만 (sim)
기본 쿼리
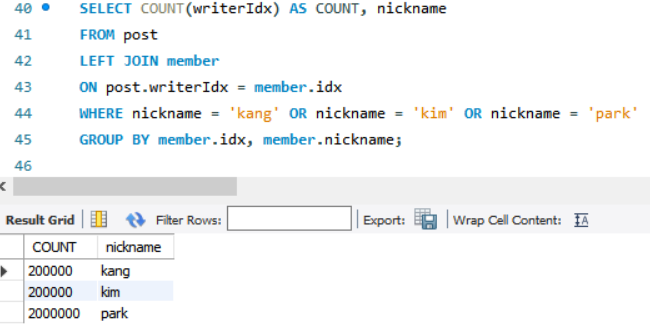
SELECT COUNT(writerIdx) AS COUNT, nickname
FROM post
LEFT JOIN member
ON post.writerIdx = member.idx
WHERE nickname = 'kang' OR nickname = 'kim' OR nickname = 'park'
GROUP BY member.idx, member.nickname;-
개선 전
쿼리에 따른 실행 결과
실행 시간(2.89s)
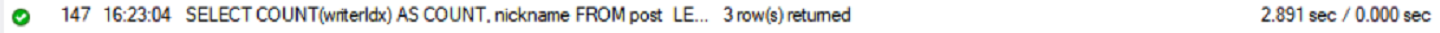
-
1차 개선(INDEX 사용)
쿼리에 따른 실행 결과
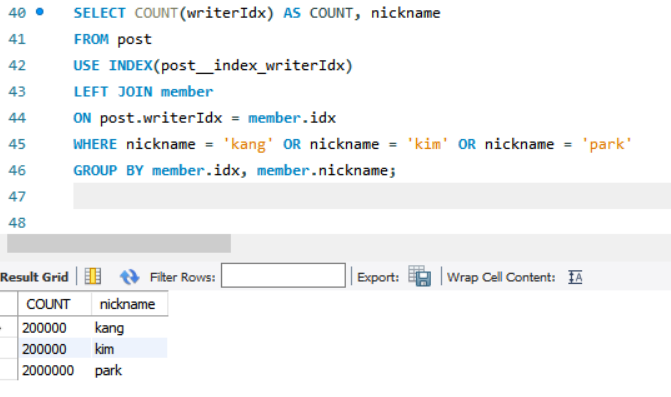
실행 시간 (2.89 -> 1.4s, 약 2배 개선)

-
2차 개선(SP 사용)
쿼리에 따른 실행 결과

실행시간(1.4s -> 1.0s)

EXPLAIN
쿼리 앞에 붙이는 키워드로 쿼리를 실행하기 전 실행 계획에 대한 정보를 알려준다.
결과
답이 정해져 있지 않기 때문에 프로젝트 성격과 흐름에 따른 근거를 토대로 결정해야한다.
- 수정, 삭제, 삽입이 빈번한지?
- CPU나 메모리 사용량은 쿼리별로 어떤지?
등등 다양한 지표를 근거에 맞게 반영해서 성능을 개선시키려는 노력이 중요하다.
