✏️학습 정리
3. BERT 언어 모델
-
BERT 모델 소개
-
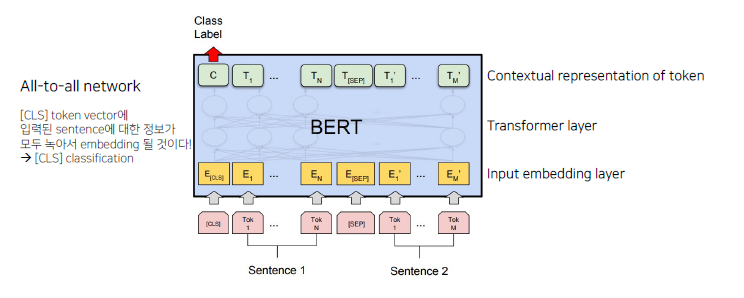
모델 구조
-
데이터 tokenizing
- WordPiece tokenizing 사용
- 2개의 token sequence가 학습에 사용
-
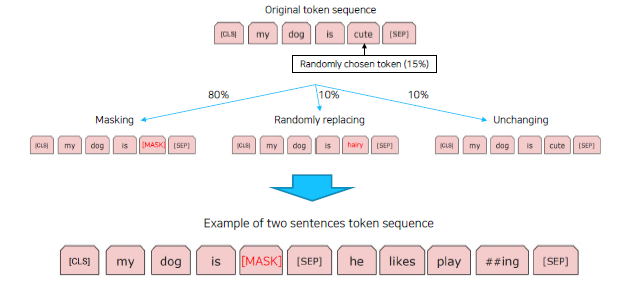
Masked Language Model
-
-
BERT 응용
-
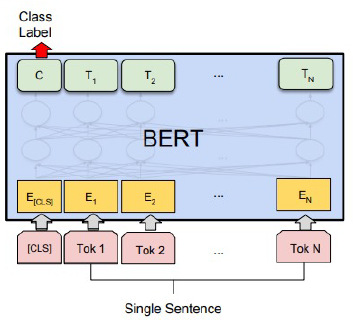
감정분석 (단일 문장 분류)
-
관계 추출 (단일 문장 분류)
-
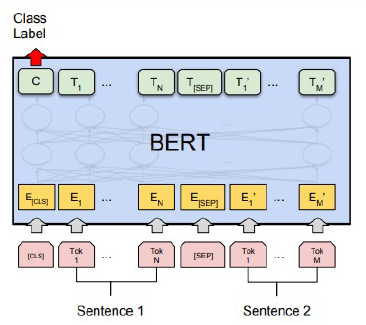
의미 비교 (두 문장 관계 분류)
-
개채명 분석 (문장 토큰 분류)
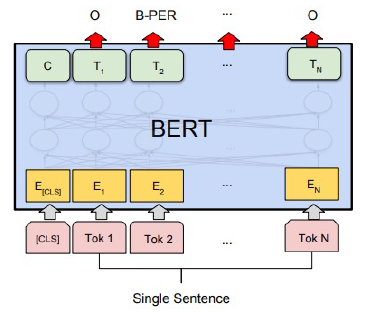
-
기계 독해 (기계 독해 정답 분류)
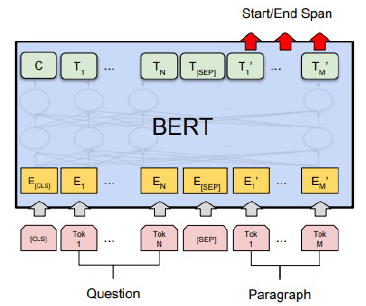
-
- 한국어 BERT 모델
- ETRI KoBERT (ETRI 형태소 기반 언어모델)
4. BERT Pre-Training
-
BERT 모델 학습
- 도메인 특화 task의 경우, 도메인 특화 된 학습 데이터만 사용하는 것이 성능이 더 좋다!
-
BERT 학습의 단계
- Tokenizer 만들기
- 데이터셋 확보
- Next Sentence Prediction (NSP)
- Masking
실습
-
BERT [Mask] token 예측 학습
-
한국어 BERT pre-trainging
- Tokenizer 만들기
- BERT 학습
🗣️피어세션
-
TAPT(Task-Adative Pretraining)에 관한 의문점
- 현재 주어진 train data 37000개로는 학습하기 부족하지 않은가?
- KLUE based 모델의 경우는 같은 코퍼스를 사용했기 때문에 상관없지만, 다른 모델의 경우 실험을 해봐야할 듯..
- 현재 주어진 train data 37000개로는 학습하기 부족하지 않은가?
-
해볼것들?
- Data Augmentation
- Special Token (An Improved Baseline for Sentence-level Relation Extraction(2019))
- 모델링
- 적합한 모델 search
- TAPT
- scikit-learn으로 validation data 분할 (stratified)

함께 자라기