✏️학습 정리
4. 자연어처리 데이터 소개 2
-
질의응답 QA
- SQuAD (위키피디아 기반)
- SQuAD 1.0
- SQuAD 2.0
- SQuAD (위키피디아 기반)
-
기계 번역 Machine Translation
- WMT 데이터셋
-
요약 Text Summarization
- CNN/Daily Mail
-
대화 Dialogue
- DSTC (Dialog System Technology Challenges)
- Wizard-of-Oz
- UDC (Ubuntu Dialogue Corpus)
5. 원시 데이터의 수집과 가공
-
원시 데이터의 정의
- 원하는 형태로 가공하지 이전의 데이터
- 데이터 수집은 하였으나, 주석 단계를 거치지 않은 상태
-
원시 데이터 수집 시 고려 사항
- 획득 가능성
- 데이터 균형과 다양성
- 신뢰성
- 법 제도 준수 (저작권, 데이터 윤리 등..)
-
원시 데이터 전처리
- 띄어쓰기
- 복합어 처리
- 숫자 처리
- 외국어 처리 ... 등
-
원시 데이터의 가공 - 주석 도구
- 구글 스프레드 시트
- 구글 폼
- Brat (오픈 소스, 옛날..)
- Doccano
- Tagtog
6. 데이터 구축 작업 설계
- 데이터 구축 프로세스
- MATTER cycle
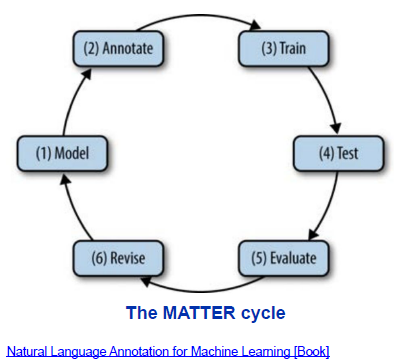
- MATTER cycle
-
데이터 주석
- 분류 (감정 분석, 주제 분류, 자연어 추론 등..)
- 특정 범위(span) 주석 (NER, 형태 분석 등..)
- 대상 간 관계 주석 (개체명 연결, 구문 분석)
- 텍스트 생성 (번역)
- 복합 유형 (질의 응답, 슬롯필링 대화 등...)
-
데이터 검수
- 가이드라인 정합성
- 데이터 형식
- 통계 정보
- 모델 성능 확인
- 오류 원인 분석
-
데이터 구축 프로세스 설계 시 유의 사항
- 데이터 구축 기간 넉넉히 설정
- 검수에 충분한 시간 확보
- 각 단계별 작업의 주체 고려
- 각 단계별 검수 유형 지정 등...

함께 자라기