✏️학습 정리
6. 확률론 맛보기
- 확률분포
-
데이터 공간: 𝒳×𝒴, 확률분포: 𝒟
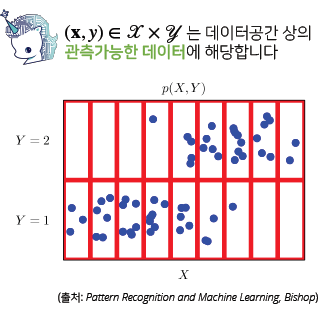
-
이산확률변수
-
확률변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링
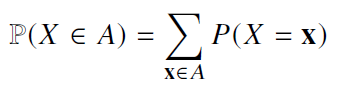
-
-
연속확률변수
-
데이터 공간에 정의된 확률변수의 밀도 위에서의 적분을 통해 모델링
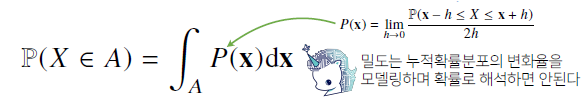
-
-
조건부확률
- P(y|x) 는 입력변수 x에 대해 정답이 y일 확률을 의미
- 선형 회귀에서 사용했던 선형모델과 softmax 함수의 결합은 데이터에서 추출된 패턴을 기반으로 확률을 해석
-
기대값
-
데이터를 대표하는 통계량
-
이산확률변수일 경우
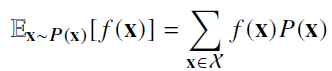
-
연속확률변수일 경우
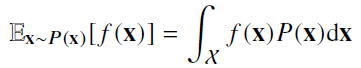
-
-
- 몬테카를로 샘플링
-
기계학습의 많은 문제들은 확률분포를 모를 때가 대부분
-
확률분포를 모를 때 데이터를 이용하여 기대값을 계산하려면 몬테카를로 샘플링 방법 사용
-
독립추출만 보장된다면 대수의 법칙에 의해 수렴성 보장
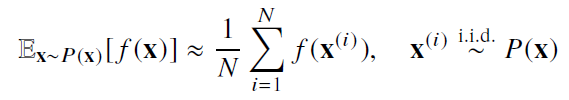
-
7. 통계학 맛보기
- 모수 (Parameter)
- 통계적 모델링은 적절한 가정 위에서 확률분포를 추정하는 것이 목표
- 데이터는 유한하기에 근사적으로 확률분포를 추정할 수 밖에 없음
- 데이터가 특정 확률분포를 따른다고 가정, 그 분포를 결정하는 모수(parameter)를 추정하는 방법이 모수적 방법론
- 데이터에 따라 모델의 구조 및 모수의 개수가 유연하게 바뀌면 비모수(non parameter) 방법론
- 최대가능도 추정법(Maximum Likelihood estimation, MLE)
-
이론적으로 가장 가능성이 높은 모수를 추정하는 방법

-
데이터 집합 X가 독립적으로 추출되었을 경우 로그가능도를 최적화
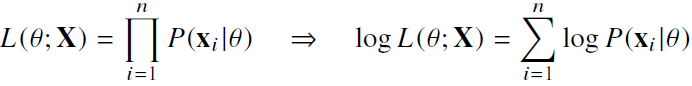
-
Why 로그가능도?
- 데이터의 숫자가 수억 단ㅇ위가 된다면 컴퓨터의 정확도로는 가능도 계산 불가
- 로그를 사용할 경우 곱셈을 덧셈으로 바꾸기 때문에 컴퓨터로 연산 가능
- 경사하강법에서 로그가능도를 사용하면 연산량을 O(n2)에서 O(n)으로 줄일 수 있다.
- 예제: 정규분포, 카테고리 분포
-
딥러닝에서 사용
-
one-hot vector로 표현한 정답레이블 y을 관찰 데이터로 이용해 확률분포인 softmax vector의 로그 가능도를 최적화할 수 있다.
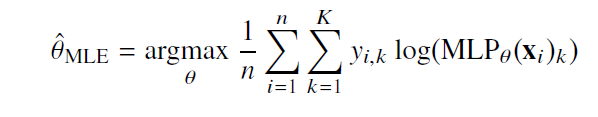
-
-
확률분포의 거리 구하기 (방법)
- 총변동 거리 (Total Variation Distance, TV)
- 쿨백-라이블러 발산 (Kullback-Leibler Divergence, KL)
- 바슈타인 거리 (Wasserstein Distance)
-
8. 베이즈 통계학 맛보기
- 조건부 확률

-
시각화
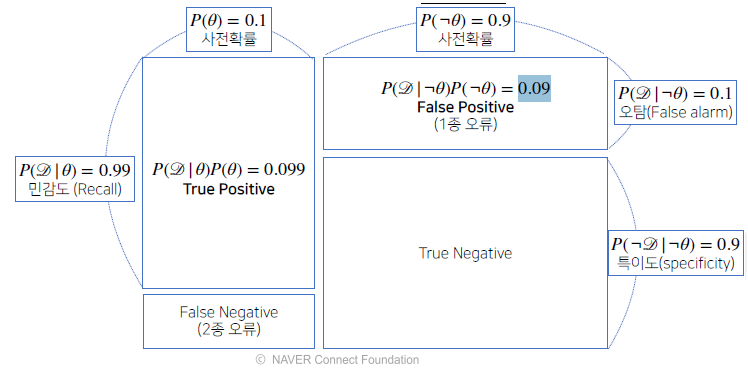
-
정밀도
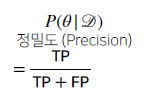
-
정보의 갱신

-
- 조건부 확률과 인과관계
-
조건부 확률은 인과관계를 추론할 때 함부로 사용해서는 안된다.
-
인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요
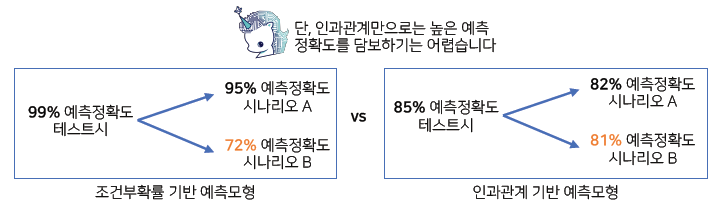
-
중첩요인 (confounding factor)의 효과를 제거하고 원인에 해당하는 변수만의 인과관계 계산
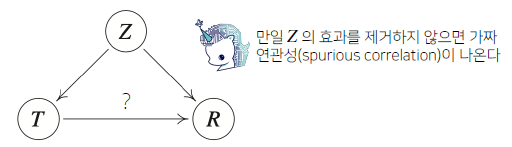
-
9. CNN 첫걸음
- MLP
-
각 뉴런들이 선형모델과 활성함수로 모두 연결된(fully connected) 구조
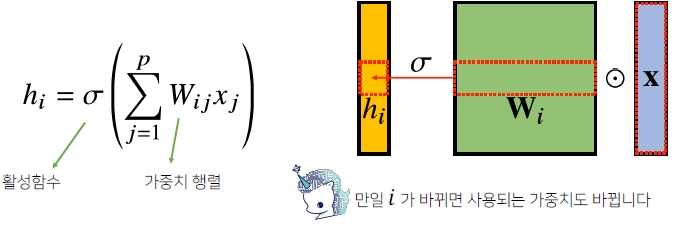
-
- CNN
-
커널(kernel)을 입력 vector 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
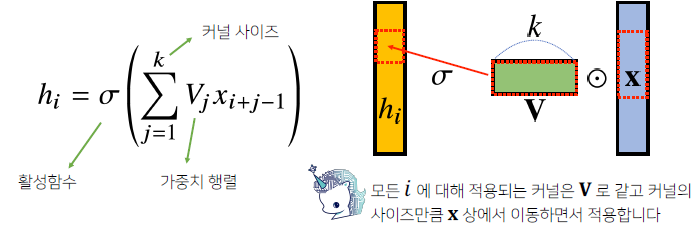
-
수학적 의미: 신호를 커널을 이용해 국소적(local)으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것
-
1차원뿐만 아니라 다양한 차원에서 계산 가능
-
입력 크기 (H, W), 커널 크기 (Kh, Kw), 출력 크기(Oh, Ow)
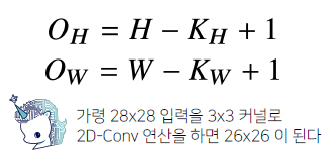
-
역전파 (backpropagation)
-
convolution 연산은 커널이 모든 입력 데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나온다.

-
-
10. RNN 첫걸음
- 시퀀스 데이터
-
소리, 문자열, 주가 등의 데이터
-
독립동등분포(i.i.d) 가정을 잘 위배하기 때문에 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
-
조건부확률 이용
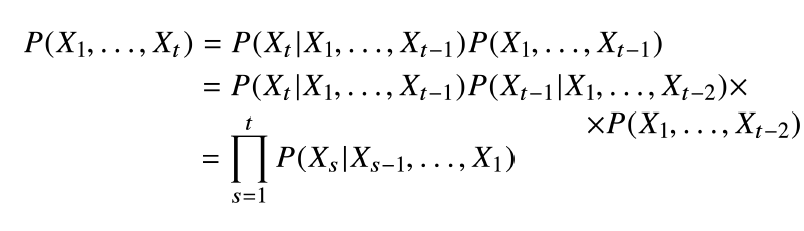
-
길이가 가변적인 데이터를 다룰 수 있는 모델이 필요

-
- RNN
-
이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링
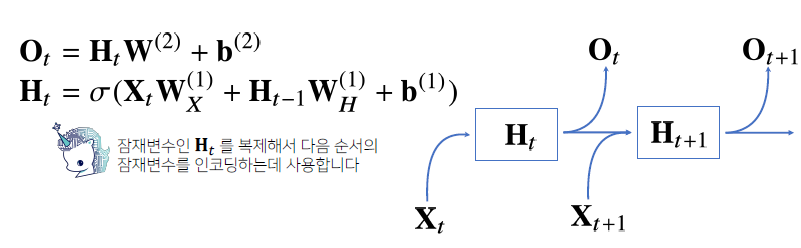
-
역전파 (backpropagation)
-
backpropagation through time (BPTT)라 한다.
-
잠재변수의 연결그래프에 따라 순차적으로 계산
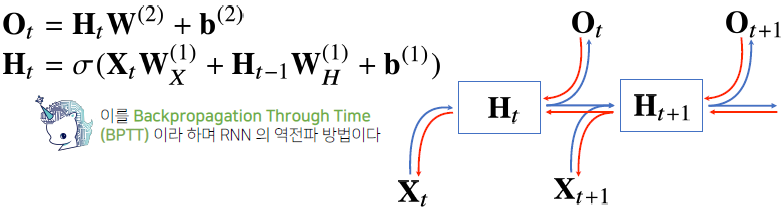
-
-
기울기 소실의 해결책
- truncated BPTT
- GRU
- LSTM
-
