📝프로젝트 개인 회고
역할
- 크롤링 코드 작성, 데이터 EDA, 텍스트 유사도 분석(Glove, SBERT)
이번 프로젝트 목표
- 데이터 수집, 모델링, 서빙을 모두 체험할 수 있는 프로젝트 경험
- 실제 비지니스에서 사용되는 데이터를 직접 수집하고 사용하면서 실무와 가까운 프로젝트 경험
프로젝트에서 시도해본 것과 결과
- 크롤링
- 공개된 리뷰 데이터를 확보하려고 했지만 매우 양이 적거나 없는 경우가 많았다. 따라서 직접 데이터 수집이 필요하게 되었고 유일하게 웹 페이지 접속이 가능한 요기요를 크롤링했다.
- 서울 전체 지하철역 주소 기준으로 Selenium을 이용해 요기요 웹페이지 크롤링
- 모든 업종의 리뷰 데이터를 수집하기에는 너무 방대해서 요기요의 모든 업종 중에 ‘카페/디저트’ 부분만 크롤링
- 총 25만 개 데이터 확보
- 힘들었던 점
click()함수 오류: 원하는 element나 xpath를 찾고 나서 click 함수를 통해 마우스 왼클릭을 수행해야하는데 자꾸 실패 →execute_script("arguments[0].click();", my_element)함수를 통해 실행 (자바스크립트 코드를 직접 실행시켜 오류 해결)
- 영업시간이 끝나면 가게의 위치가 맨뒤로 가는 경우: 전체 가게 페이지에서 하나씩 클릭하여 크롤링하는 구조이기에 크롤링 중에 영업시간이 끝나면 가게를 건너뛰게 됨 → 전체 가게 이름을 list화하고 하나씩 검색하여 크롤링 함
-
데이터 EDA
-
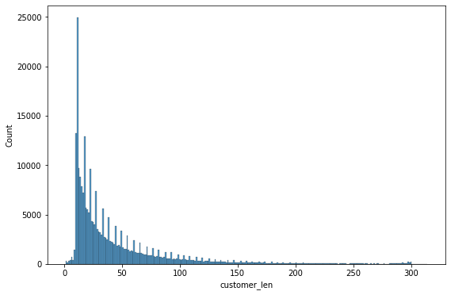
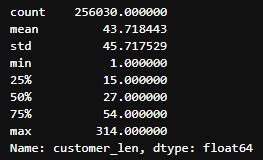
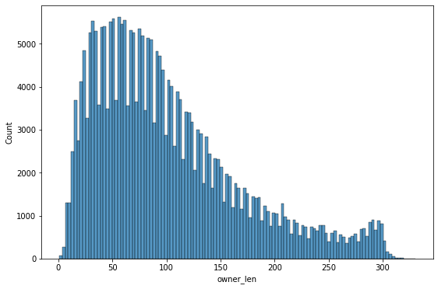
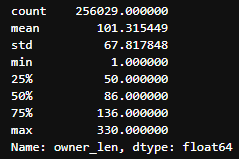
길이 분포
-
고객 리뷰
-
사장 답글
-
무성의한 고객 리뷰와 사장 답글을 거르기위해 길이 분포의 통계를 바탕으로 고객 리뷰와 사장 답글이 적절한 길이인 경우만 사용
- 고객 리뷰: 15 초과, 100 미만
- 사장 답글: 50 초과, 200 미만
-
-
-
유사도 분석
-
단순히 사장님 답글을 학습하는 것이 아닌 고객 리뷰에 맞춰 생성하는 것을 목표로 했다. 따라서, 고객 리뷰와 사장님 답글간의 유사도가 필요했다.
-
Glove
-
카운트 기반의 LSA와 예측 기반의 Word2Vec의 단점을 보완한 glove 사용
-
임베딩된 단어벡터 간 유사도 측정을 수월하게 수행하고 동시에 말뭉치 전체의 통계 정보를 반영하기에 적절하다고 판단
-
한국어 위키백과, KorQuAD, 네이버 영화 말뭉치 등으로 학습된 glove를 사용
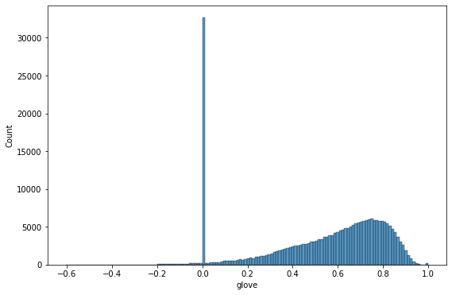
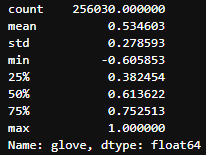
-
glove의 경우 명사를 추출하고 유사도를 측정하기 때문에 0이 대략 3만개 발생
- 의미 없이 이모티콘이나 특수문자로 도배된 리뷰들을 거를 수 있었다.
-
-
Sentence-BERT
-
SBERT의 finetuning 방식인 STS(Semantic Textual Similarity) 문제는 두 문장으로부터 의미적 유사성을 구한다. 해당 방식이 우리가 생각하는 유사도와 비슷하다고 생각하여 사용
-
multi-lingual SBERT 중 가장 성능이 좋은 paraphrase-multilingual-MiniLM-L12-v2 를 사용
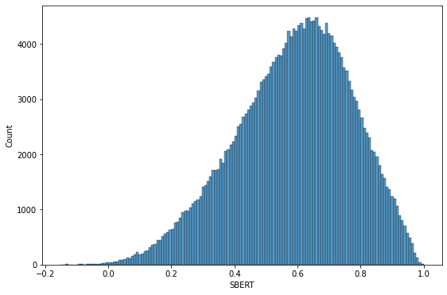
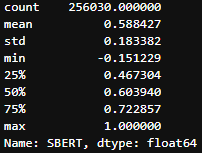
-
최종 유사도 분포를 이용하여 glove는 0을 제외한 분포에서 0.4 이상, Sentence-BERT는 전체 분포에서 0.4 이상의 값을 보이는 데이터만 남도록 전처리
- train, valid, test의 데이터합이 최소 10만은 되어야 한다고 생각하여 기준을 0.4로 잡았다.
-
-
아쉬웠던 점
-
TF-IDF를 적용하지 못한 점
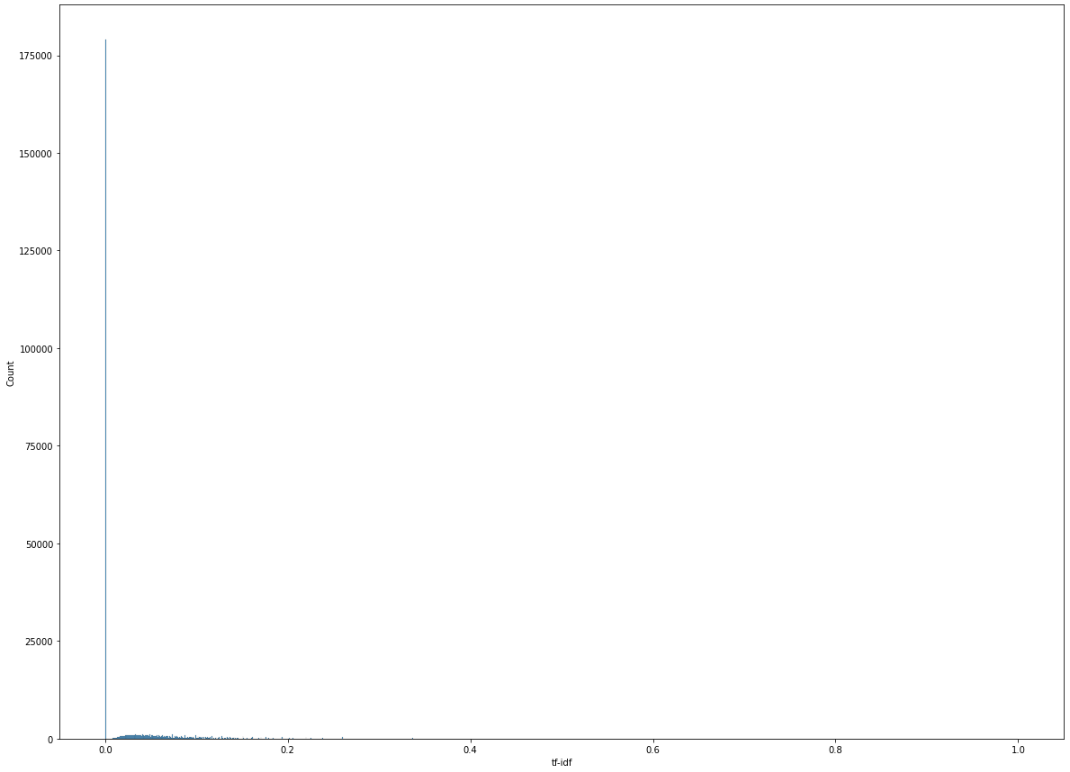
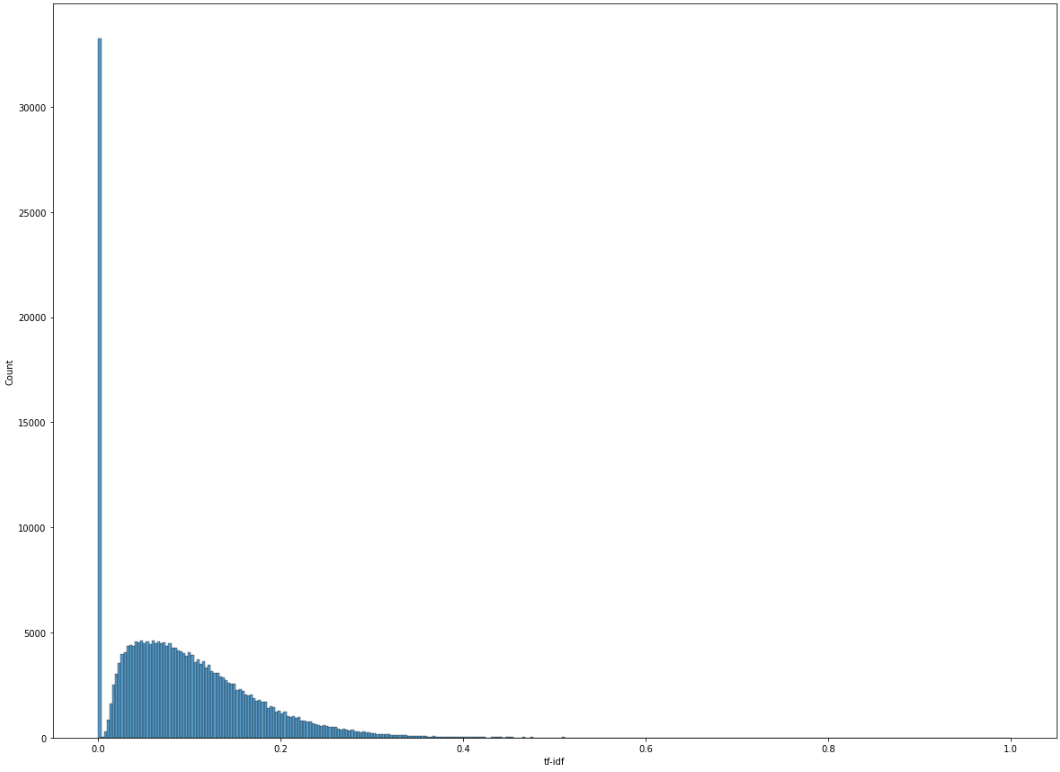
- 유사도하면 가장 먼저 생각나는 기법인 TF-IDF를 라이브러리로 구현했더니 전체 데이터에서 40%가 0점이 나와 사용할 수 없었다. 프로젝트 기간이 길지 않아 빠르게 다른 기법을 탐색하게 되었다. 프로젝트가 마무리되어 가는 시점에 시간이 남아 TF-IDF 라이브러리를 자세히 조사해보니 tokenizer를 설정할 수 있었다. 기존의 구현했던 TF-IDF의 경우 공백을 기준으로 단어를 나누기 때문에 한국어에서 성능이 좋을 수 없었다. (한국어는 조사가 존재하기 때문에) 한국어 형태소 분석기인 Okt나 Mecab을 사용하여 다시 유사도를 구해보니 기존보다 훨씬 유의미한 결과를 얻을 수 있었다. 초반에 더 자세히 조사하지 못한 점이 아쉬웠다.
- 기존 TF-IDF
- Mecab 토크나이저 적용 TF-IDF
-
서버마다 inference 결과 상이
- KoGPT2의 finetuning 이후 inference를 수행했는데 다른 팀원의 서버와 나의 서버에서 결과가 다르게 나왔다. 모델 파일, 코드, seed 값이 같았는데 결과가 다르게 나와 혼란스러웠다. 프로젝트 마무리 기간이 별로 남지 않았기에 원인을 파악하지 못했고, inference는 나의 서버에서 돌리게 되었다. 프로젝트가 끝나고 서버가 회수되어 원인을 결국 파악하지 못한 점이 아쉬웠다.
-
데이터 EDA 활용
- 데이터 EDA를 할 때 길이 분포를 제외하고도 단어, 이모티콘, 특수문자 빈도수도 확인해보았다. 예를 들어 단어
날씨는 사장답글 18만개 데이터 중에 1만개 문장에서 등장했다. 이는 확률로 따지면 5%지만 inference를 해보면 날씨가 5%보다 많이 등장했다. 이러한 편향성을 최대한 줄이고 싶었다. 하지만, 막상 빈도수를 구해도 어떻게 편향성을 구할지 감이 잡히지 않았고 프로젝트의 기간이 넉넉하지 않아 빠르게 진행해야 해서 길이 분포만 반영하였다. 데이터 EDA를 통해 좀더 다양한 실험을 못한 점이 아쉬웠다.
- 데이터 EDA를 할 때 길이 분포를 제외하고도 단어, 이모티콘, 특수문자 빈도수도 확인해보았다. 예를 들어 단어
다음에 시도해보고 싶은 것들
- 클라우드에 모델 서빙
- 이번 프로젝트에서는 클라우드가 아닌 개인 서버에서 streamlit을 이용하여 데모를 만들었지만, 다음 프로젝트는 GCP나 AWS를 이용하여 배포를 해볼 것이다.
- 모델 경량화
- 이번 부스트캠프에서는 모델 경량화를 배우지 않았지만, 이번 프로젝트를 하면서 모델의 학습 시간과 inference 시간 등 실제로 서비스를 하기에는 모델이 크다고 느껴졌고 경량화를 배울 필요가 있다고 생각했다.
- 깊은 데이터 EDA를 통해 좀 더 다양한 실험 설계
- 데이터 EDA로 길이 분포와 단어 빈도수를 확인했지만, 데이터를 더욱 깊이 살펴보면 유의미한 정보를 많이 얻을 수 있다고 생각한다. 이번 프로젝트는 기한이 짧아 깊이있게 볼 수는 없었지만 다음 프로젝트에서는 데이터를 깊이 분석해보고 싶다.

함께 자라기