✏️학습 정리
8. Multi-GPU 학습
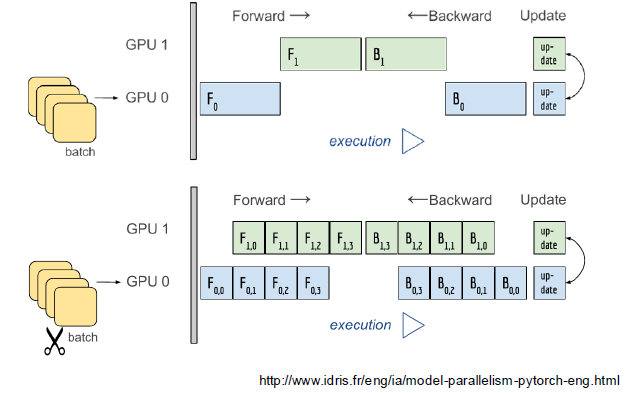
- Model parallel
-
다중 GPU에 학습을 분산하는 두가지 방법 (모델 나누기, 데이터 나누기)
-
모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
-
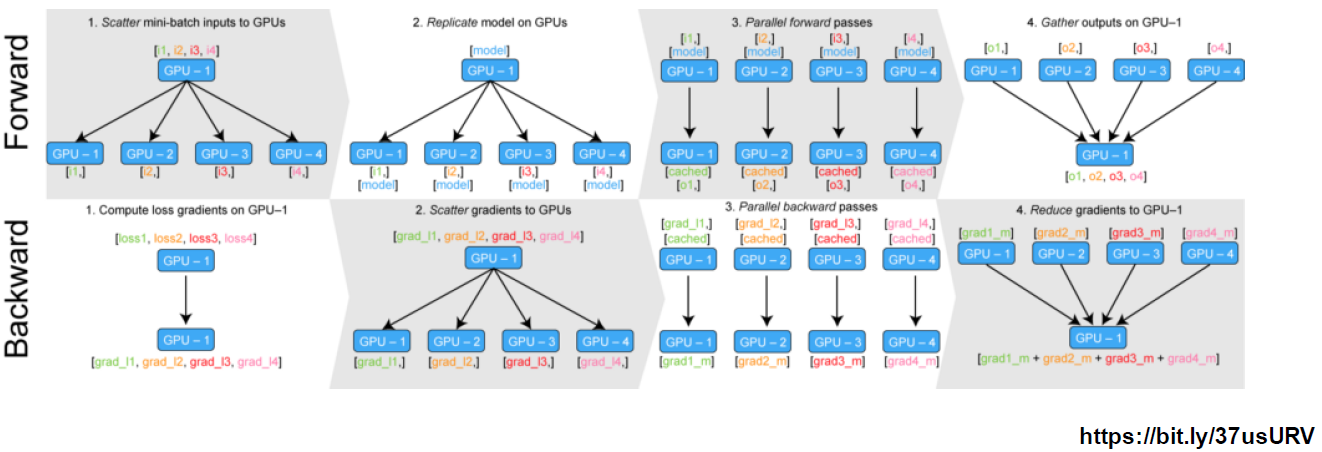
- Data parallel
-
데이터를 나눠 GPU에 할당후 결과의 평균을 취하는 방법
-
minibatch 수식과 유사한데 한번에 여러 GPU에서 수행
-
DataParallel: 단순히 데이터를 분배한 후 평균을 취함 (GPU 사용 불균형 발생 → GPU 병목)
-
DistributedDataParallel: 각 CPU마다 process 생성하여 개별 GPU에 할당 (개별적으로 연산의 평균을 냄)
-
9. Hyperparameter Tuning
-
Hyperparameter Tuning
-
모델 스스로 학습하지 않는 값은 사람이 지정(learning rate, 모델의 크기, optimizer 등..)
-
hyperparameter에 의해서 값이 크게 좌우 될 때도 있다. (요즘은 별로...)
-
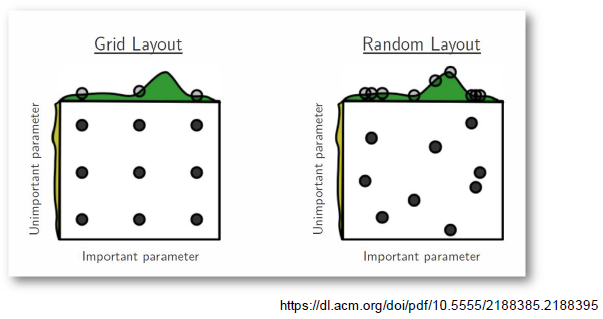
가장 기본적인 방법 (grid vs random)
-
최근에는 베이지안 기반 기법들이 주도
-
-
Ray
- multi-node nulti processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- Hyperparameter search를 위한 다양한 모듈 제공
10. PyTorch Troubleshooting
-
OOM (Out of Memory)
- 발생 이유를 알기 어려움
- 어디서 발생했는지 알기 어려움
- Error Tracking이 이상한 곳으로 감
- 메모리의 이전상황의 파악이 어려움
- 간단한 해결법 (Batch Size 줄이기 → GPU clean → 실행)
-
GPU Util
- nvidia-smi처럼 GPU 상태를 보여주는 모듈
- Colab은 환경에서 GPU 상태 보여주기 편함
- iter마다 메모리가 늘어나는지 확인
import GPUtil
GPUtil.showUtilization()-
torch.cuda.empty_cache()
- 사용되지 않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del 과는 구분이 필요
- reset 대신 쓰기 좋은 함수
-
trainning loop에 tensor로 축적되는 변수 확인
- tensor로 처리된 변수는 GPU 상에 메모리 사용
- 해당 변수가 loop 안의 연산에 있을 때 GPU에 computational graph를 생성(메모리 잠식)
- 1-d tensor의 경우 python 기본 객체로 변환하여 처리
- python의 메모리 배치 특성상 loop이 끝나도 메모리를 차지 → 필요가 없어진 변수는 적절한 삭제가 필요(del 사용)
-
torch.no_grad() 사용
- Inference 시점에서는 torch.no_grad() 구문을 사용
- backward pass으로 인해 쌓이는 메모리에서 자유로움

함께 자라기